 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABFR-KAN: Kolmogorov-Arnold Networks for Functional Brain Analysis
Jan 01, 2026Functional connectivity (FC) analysis, a valuable tool for computer-aided brain disorder diagnosis, traditionally relies on atlas-based parcellation. However, issues relating to selection bias and a lack of regard for subject specificity can arise as a result of such parcellations. Addressing this, we propose ABFR-KAN, a transformer-based classification network that incorporates novel advanced brain function representation components with the power of Kolmogorov-Arnold Networks (KANs) to mitigate structural bias, improve anatomical conformity, and enhance the reliability of FC estimation. Extensive experiments on the ABIDE I dataset, including cross-site evaluation and ablation studies across varying model backbones and KAN configurations, demonstrate that ABFR-KAN consistently outperforms state-of-the-art baselines for autism spectrum distorder (ASD) classification. Our code is available at https://github.com/tbwa233/ABFR-KAN.
Autoadaptive Medical Segment Anything Model
Jul 02, 2025Medical image segmentation is a key task in the imaging workflow, influencing many image-based decisions. Traditional, fully-supervised segmentation models rely on large amounts of labeled training data, typically obtained through manual annotation, which can be an expensive, time-consuming, and error-prone process. This signals a need for accurate, automatic, and annotation-efficient methods of training these models. We propose ADA-SAM (automated, domain-specific, and adaptive segment anything model), a novel multitask learning framework for medical image segmentation that leverages class activation maps from an auxiliary classifier to guide the predictions of the semi-supervised segmentation branch, which is based on the Segment Anything (SAM) framework. Additionally, our ADA-SAM model employs a novel gradient feedback mechanism to create a learnable connection between the segmentation and classification branches by using the segmentation gradients to guide and improve the classification predictions. We validate ADA-SAM on real-world clinical data collected during rehabilitation trials, and demonstrate that our proposed method outperforms both fully-supervised and semi-supervised baselines by double digits in limited label settings. Our code is available at: https://github.com/tbwa233/ADA-SAM.
Detection of Breast Cancer Lumpectomy Margin with SAM-incorporated Forward-Forward Contrastive Learning
Jun 26, 2025Complete removal of cancer tumors with a negative specimen margin during lumpectomy is essential in reducing breast cancer recurrence. However, 2D specimen radiography (SR), the current method used to assess intraoperative specimen margin status, has limited accuracy, resulting in nearly a quarter of patients requiring additional surgery. To address this, we propose a novel deep learning framework combining the Segment Anything Model (SAM) with Forward-Forward Contrastive Learning (FFCL), a pre-training strategy leveraging both local and global contrastive learning for patch-level classification of SR images. After annotating SR images with regions of known maligancy, non-malignant tissue, and pathology-confirmed margins, we pre-train a ResNet-18 backbone with FFCL to classify margin status, then reconstruct coarse binary masks to prompt SAM for refined tumor margin segmentation. Our approach achieved an AUC of 0.8455 for margin classification and segmented margins with a 27.4% improvement in Dice similarity over baseline models, while reducing inference time to 47 milliseconds per image. These results demonstrate that FFCL-SAM significantly enhances both the speed and accuracy of intraoperative margin assessment, with strong potential to reduce re-excision rates and improve surgical outcomes in breast cancer treatment. Our code is available at https://github.com/tbwa233/FFCL-SAM/.
Domain and Task-Focused Example Selection for Data-Efficient Contrastive Medical Image Segmentation
May 25, 2025Segmentation is one of the most important tasks in the medical imaging pipeline as it influences a number of image-based decisions. To be effective, fully supervised segmentation approaches require large amounts of manually annotated training data. However, the pixel-level annotation process is expensive, time-consuming, and error-prone, hindering progress and making it challenging to perform effective segmentations. Therefore, models must learn efficiently from limited labeled data. Self-supervised learning (SSL), particularly contrastive learning via pre-training on unlabeled data and fine-tuning on limited annotations, can facilitate such limited labeled image segmentation. To this end, we propose a novel self-supervised contrastive learning framework for medical image segmentation, leveraging inherent relationships of different images, dubbed PolyCL. Without requiring any pixel-level annotations or unreasonable data augmentations, our PolyCL learns and transfers context-aware discriminant features useful for segmentation from an innovative surrogate, in a task-related manner. Additionally, we integrate the Segment Anything Model (SAM) into our framework in two novel ways: as a post-processing refinement module that improves the accuracy of predicted masks using bounding box prompts derived from coarse outputs, and as a propagation mechanism via SAM 2 that generates volumetric segmentations from a single annotated 2D slice. Experimental evaluations on three public computed tomography (CT) datasets demonstrate that PolyCL outperforms fully-supervised and self-supervised baselines in both low-data and cross-domain scenarios. Our code is available at https://github.com/tbwa233/PolyCL.
Improving Brain Disorder Diagnosis with Advanced Brain Function Representation and Kolmogorov-Arnold Networks
Apr 04, 2025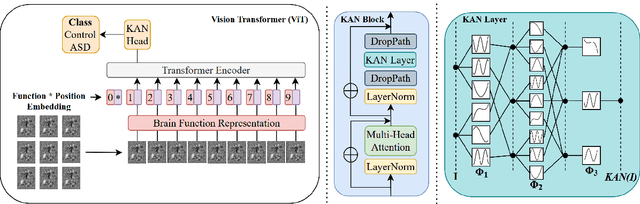
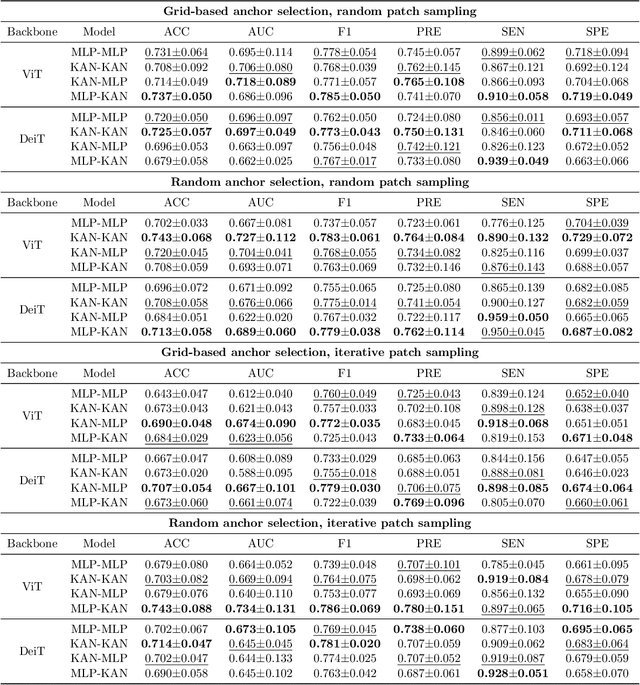
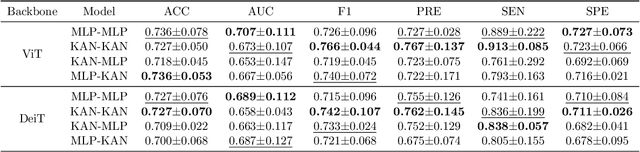
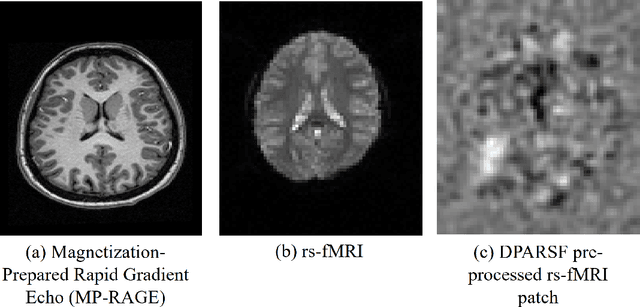
Quantifying functional connectivity (FC), a vital metric for the diagnosis of various brain disorders, traditionally relies on the use of a pre-defined brain atlas. However, using such atlases can lead to issues regarding selection bias and lack of regard for specificity. Addressing this, we propose a novel transformer-based classification network (AFBR-KAN) with effective brain function representation to aid in diagnosing autism spectrum disorder (ASD). AFBR-KAN leverages Kolmogorov-Arnold Network (KAN) blocks replacing traditional multi-layer perceptron (MLP) components. Thorough experimentation reveals the effectiveness of AFBR-KAN in improving the diagnosis of ASD under various configurations of the model architecture. Our code is available at https://github.com/tbwa233/ABFR-KAN
Annotation-Efficient Task Guidance for Medical Segment Anything
Dec 11, 2024



Medical image segmentation is a key task in the imaging workflow, influencing many image-based decisions. Traditional, fully-supervised segmentation models rely on large amounts of labeled training data, typically obtained through manual annotation, which can be an expensive, time-consuming, and error-prone process. This signals a need for accurate, automatic, and annotation-efficient methods of training these models. We propose SAM-Mix, a novel multitask learning framework for medical image segmentation that uses class activation maps produced by an auxiliary classifier to guide the predictions of the semi-supervised segmentation branch, which is based on the SAM framework. Experimental evaluations on the public LiTS dataset confirm the effectiveness of SAM-Mix for simultaneous classification and segmentation of the liver from abdominal computed tomography (CT) scans. When trained for 90% fewer epochs on only 50 labeled 2D slices, representing just 0.04% of the available labeled training data, SAM-Mix achieves a Dice improvement of 5.1% over the best baseline model. The generalization results for SAM-Mix are even more impressive, with the same model configuration yielding a 25.4% Dice improvement on a cross-domain segmentation task. Our code is available at https://github.com/tbwa233/SAM-Mix.
Areas of Improvement for Autonomous Vehicles: A Machine Learning Analysis of Disengagement Reports
Jul 31, 2024
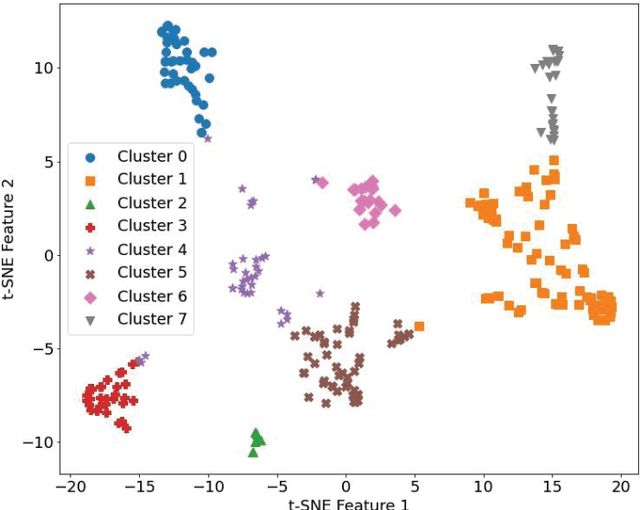


Since 2014, the California Department of Motor Vehicles (CDMV) has compiled information from manufacturers of autonomous vehicles (AVs) regarding factors that lead to the disengagement from autonomous driving mode in these vehicles. These disengagement reports (DRs) contain information detailing whether the AV disengaged from autonomous mode due to technology failure, manual override, or other factors during driving tests. This paper presents a machine learning (ML) based analysis of the information from the 2023 DRs. We use a natural language processing (NLP) approach to extract important information from the description of a disengagement, and use the k-Means clustering algorithm to group report entries together. The cluster frequency is then analyzed, and each cluster is manually categorized based on the factors leading to disengagement. We discuss findings from previous years' DRs, and provide our own analysis to identify areas of improvement for AVs.
Implementing the ICE Estimator in Multilayer Perceptron Classifiers
Jul 13, 2020
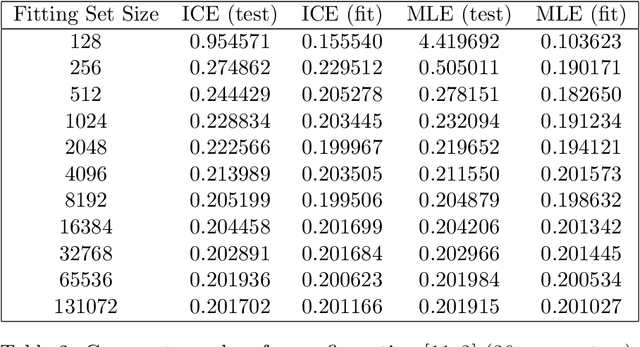
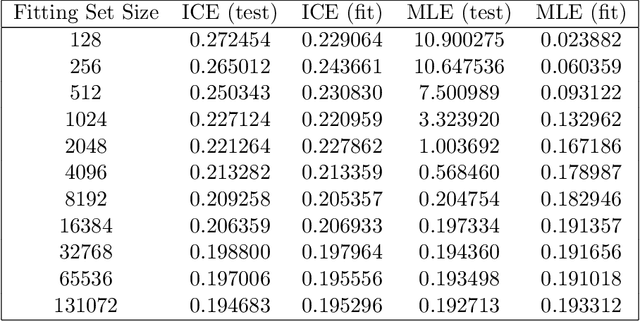
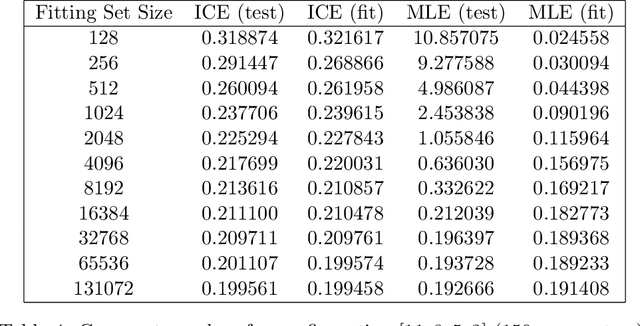
This paper describes the techniques used to implement the ICE estimator for a multilayer perceptron model, and reviews the performance of the resulting models. The ICE estimator is implemented in the Apache Spark MultilayerPerceptronClassifier, and shown in cross-validation to outperform the stock MultilayerPerceptronClassifier that uses unadjusted MLE (cross-entropy) loss. The resulting models have identical runtime performance, and similar fitting performance to the stock MLP implementations. Additionally, this approach requires no hyper-parameters, and is therefore viable as a drop-in replacement for cross-entropy optimizing multilayer perceptron classifiers wherever overfitting may be a concern.
The Information Theoretically Efficient Model (ITEM): A model for computerized analysis of large datasets
Nov 04, 2014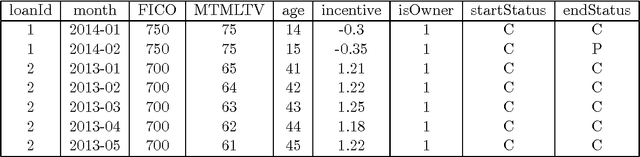

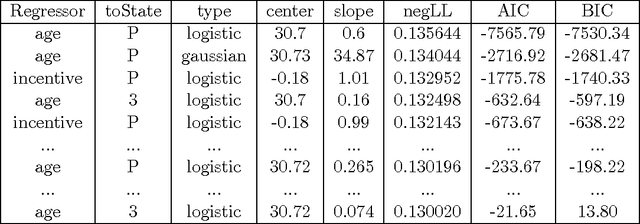

This document discusses the Information Theoretically Efficient Model (ITEM), a computerized system to generate an information theoretically efficient multinomial logistic regression from a general dataset. More specifically, this model is designed to succeed even where the logit transform of the dependent variable is not necessarily linear in the independent variables. This research shows that for large datasets, the resulting models can be produced on modern computers in a tractable amount of time. These models are also resistant to overfitting, and as such they tend to produce interpretable models with only a limited number of features, all of which are designed to be well behaved.