 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFRBench: A Reasoning Benchmark for Evaluating Forecasting Systems
Apr 07, 2026We introduce TFRBench, the first benchmark designed to evaluate the reasoning capabilities of forecasting systems. Traditionally, time-series forecasting has been evaluated solely on numerical accuracy, treating foundation models as ``black boxes.'' Unlike existing benchmarks, TFRBench provides a protocol for evaluating the reasoning generated by forecasting systems--specifically their analysis of cross-channel dependencies, trends, and external events. To enable this, we propose a systematic multi-agent framework that utilizes an iterative verification loop to synthesize numerically grounded reasoning traces. Spanning ten datasets across five domains, our evaluation confirms that this reasoning is causally effective; useful for evaluation; and prompting LLMs with our generated traces significantly improves forecasting accuracy compared to direct numerical prediction (e.g., avg. $\sim40.2\%\to56.6\%)$, validating the quality of our reasoning. Conversely, benchmarking experiments reveal that off-the-shelf LLMs consistently struggle with both reasoning (lower LLM-as-a-Judge scores) and numerical forecasting, frequently failing to capture domain-specific dynamics. TFRBench thus establishes a new standard for interpretable, reasoning-based evaluation in time-series forecasting. Our benchmark is available at: https://tfrbench.github.io
MolSnap: Snap-Fast Molecular Generation with Latent Variational Mean Flow
Aug 07, 2025Molecular generation conditioned on textual descriptions is a fundamental task in computational chemistry and drug discovery. Existing methods often struggle to simultaneously ensure high-quality, diverse generation and fast inference. In this work, we propose a novel causality-aware framework that addresses these challenges through two key innovations. First, we introduce a Causality-Aware Transformer (CAT) that jointly encodes molecular graph tokens and text instructions while enforcing causal dependencies during generation. Second, we develop a Variational Mean Flow (VMF) framework that generalizes existing flow-based methods by modeling the latent space as a mixture of Gaussians, enhancing expressiveness beyond unimodal priors. VMF enables efficient one-step inference while maintaining strong generation quality and diversity. Extensive experiments on four standard molecular benchmarks demonstrate that our model outperforms state-of-the-art baselines, achieving higher novelty (up to 74.5\%), diversity (up to 70.3\%), and 100\% validity across all datasets. Moreover, VMF requires only one number of function evaluation (NFE) during conditional generation and up to five NFEs for unconditional generation, offering substantial computational efficiency over diffusion-based methods.
Detection of Breast Cancer Lumpectomy Margin with SAM-incorporated Forward-Forward Contrastive Learning
Jun 26, 2025Complete removal of cancer tumors with a negative specimen margin during lumpectomy is essential in reducing breast cancer recurrence. However, 2D specimen radiography (SR), the current method used to assess intraoperative specimen margin status, has limited accuracy, resulting in nearly a quarter of patients requiring additional surgery. To address this, we propose a novel deep learning framework combining the Segment Anything Model (SAM) with Forward-Forward Contrastive Learning (FFCL), a pre-training strategy leveraging both local and global contrastive learning for patch-level classification of SR images. After annotating SR images with regions of known maligancy, non-malignant tissue, and pathology-confirmed margins, we pre-train a ResNet-18 backbone with FFCL to classify margin status, then reconstruct coarse binary masks to prompt SAM for refined tumor margin segmentation. Our approach achieved an AUC of 0.8455 for margin classification and segmented margins with a 27.4% improvement in Dice similarity over baseline models, while reducing inference time to 47 milliseconds per image. These results demonstrate that FFCL-SAM significantly enhances both the speed and accuracy of intraoperative margin assessment, with strong potential to reduce re-excision rates and improve surgical outcomes in breast cancer treatment. Our code is available at https://github.com/tbwa233/FFCL-SAM/.
RefiDiff: Refinement-Aware Diffusion for Efficient Missing Data Imputation
May 20, 2025Missing values in high-dimensional, mixed-type datasets pose significant challenges for data imputation, particularly under Missing Not At Random (MNAR) mechanisms. Existing methods struggle to integrate local and global data characteristics, limiting performance in MNAR and high-dimensional settings. We propose an innovative framework, RefiDiff, combining local machine learning predictions with a novel Mamba-based denoising network capturing interrelationships among distant features and samples. Our approach leverages pre-refinement for initial warm-up imputations and post-refinement to polish results, enhancing stability and accuracy. By encoding mixed-type data into unified tokens, RefiDiff enables robust imputation without architectural or hyperparameter tuning. RefiDiff outperforms state-of-the-art (SOTA) methods across missing-value settings, excelling in MNAR with a 4x faster training time than SOTA DDPM-based approaches. Extensive evaluations on nine real-world datasets demonstrate its robustness, scalability, and effectiveness in handling complex missingness patterns.
Mol-CADiff: Causality-Aware Autoregressive Diffusion for Molecule Generation
Mar 07, 2025The design of novel molecules with desired properties is a key challenge in drug discovery and materials science. Traditional methods rely on trial-and-error, while recent deep learning approaches have accelerated molecular generation. However, existing models struggle with generating molecules based on specific textual descriptions. We introduce Mol-CADiff, a novel diffusion-based framework that uses causal attention mechanisms for text-conditional molecular generation. Our approach explicitly models the causal relationship between textual prompts and molecular structures, overcoming key limitations in existing methods. We enhance dependency modeling both within and across modalities, enabling precise control over the generation process. Our extensive experiments demonstrate that Mol-CADiff outperforms state-of-the-art methods in generating diverse, novel, and chemically valid molecules, with better alignment to specified properties, enabling more intuitive language-driven molecular design.
CausalGeD: Blending Causality and Diffusion for Spatial Gene Expression Generation
Feb 11, 2025



The integration of single-cell RNA sequencing (scRNA-seq) and spatial transcriptomics (ST) data is crucial for understanding gene expression in spatial context. Existing methods for such integration have limited performance, with structural similarity often below 60\%, We attribute this limitation to the failure to consider causal relationships between genes. We present CausalGeD, which combines diffusion and autoregressive processes to leverage these relationships. By generalizing the Causal Attention Transformer from image generation to gene expression data, our model captures regulatory mechanisms without predefined relationships. Across 10 tissue datasets, CausalGeD outperformed state-of-the-art baselines by 5- 32\% in key metrics, including Pearson's correlation and structural similarity, advancing both technical and biological insights.
TSCMamba: Mamba Meets Multi-View Learning for Time Series Classification
Jun 06, 2024Time series classification (TSC) on multivariate time series is a critical problem. We propose a novel multi-view approach integrating frequency-domain and time-domain features to provide complementary contexts for TSC. Our method fuses continuous wavelet transform spectral features with temporal convolutional or multilayer perceptron features. We leverage the Mamba state space model for efficient and scalable sequence modeling. We also introduce a novel tango scanning scheme to better model sequence relationships. Experiments on 10 standard benchmark datasets demonstrate our approach achieves an average 6.45% accuracy improvement over state-of-the-art TSC models.
TimeMachine: A Time Series is Worth 4 Mambas for Long-term Forecasting
Mar 14, 2024
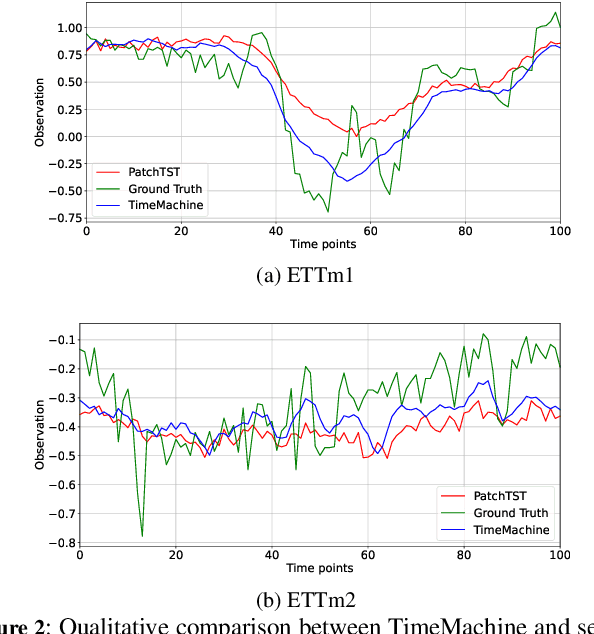
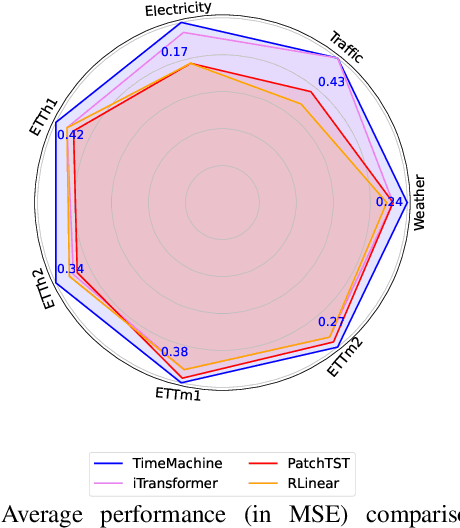
Long-term time-series forecasting remains challenging due to the difficulty in capturing long-term dependencies, achieving linear scalability, and maintaining computational efficiency. We introduce TimeMachine, an innovative model that leverages Mamba, a state-space model, to capture long-term dependencies in multivariate time series data while maintaining linear scalability and small memory footprints. TimeMachine exploits the unique properties of time series data to produce salient contextual cues at multi-scales and leverage an innovative integrated quadruple-Mamba architecture to unify the handling of channel-mixing and channel-independence situations, thus enabling effective selection of contents for prediction against global and local contexts at different scales. Experimentally, TimeMachine achieves superior performance in prediction accuracy, scalability, and memory efficiency, as extensively validated using benchmark datasets. Code availability: https://github.com/Atik-Ahamed/TimeMachine
MambaTab: A Simple Yet Effective Approach for Handling Tabular Data
Jan 16, 2024

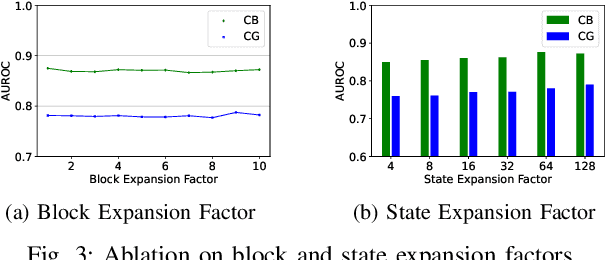

Tabular data remains ubiquitous across domains despite growing use of images and texts for machine learning. While deep learning models like convolutional neural networks and transformers achieve strong performance on tabular data, they require extensive data preprocessing, tuning, and resources, limiting accessibility and scalability. This work develops an innovative approach based on a structured state-space model (SSM), MambaTab, for tabular data. SSMs have strong capabilities for efficiently extracting effective representations from data with long-range dependencies. MambaTab leverages Mamba, an emerging SSM variant, for end-to-end supervised learning on tables. Compared to state-of-the-art baselines, MambaTab delivers superior performance while requiring significantly fewer parameters and minimal preprocessing, as empirically validated on diverse benchmark datasets. MambaTab's efficiency, scalability, generalizability, and predictive gains signify it as a lightweight, "out-of-the-box" solution for diverse tabular data with promise for enabling wider practical applications.