 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultigrid methods for total variation
Feb 25, 2025Based on a nonsmooth coherence condition, we construct and prove the convergence of a forward-backward splitting method that alternates between steps on a fine and a coarse grid. Our focus is a total variation regularised inverse imaging problems, specifically, their dual problems, for which we develop in detail the relevant coarse-grid problems. We demonstrate the performance of our method on total variation denoising and magnetic resonance imaging.
Online optimisation for dynamic electrical impedance tomography
Dec 17, 2024



Online optimisation studies the convergence of optimisation methods as the data embedded in the problem changes. Based on this idea, we propose a primal dual online method for nonlinear time-discrete inverse problems. We analyse the method through regret theory and demonstrate its performance in real-time monitoring of moving bodies in a fluid with Electrical Impedance Tomography (EIT). To do so, we also prove the second-order differentiability of the Complete Electrode Model (CEM) solution operator on $L^\infty$.
Prediction techniques for dynamic imaging with online primal-dual methods
May 03, 2024Online optimisation facilitates the solution of dynamic inverse problems, such as image stabilisation, fluid flow monitoring, and dynamic medical imaging. In this paper, we improve upon previous work on predictive online primal-dual methods on two fronts. Firstly, we provide a more concise analysis that symmetrises previously unsymmetric regret bounds, and relaxes previous restrictive conditions on the dual predictor. Secondly, based on the latter, we develop several improved dual predictors. We numerically demonstrate their efficacy in image stabilisation and dynamic positron emission tomography.
Proximal methods for point source localisation
Dec 06, 2022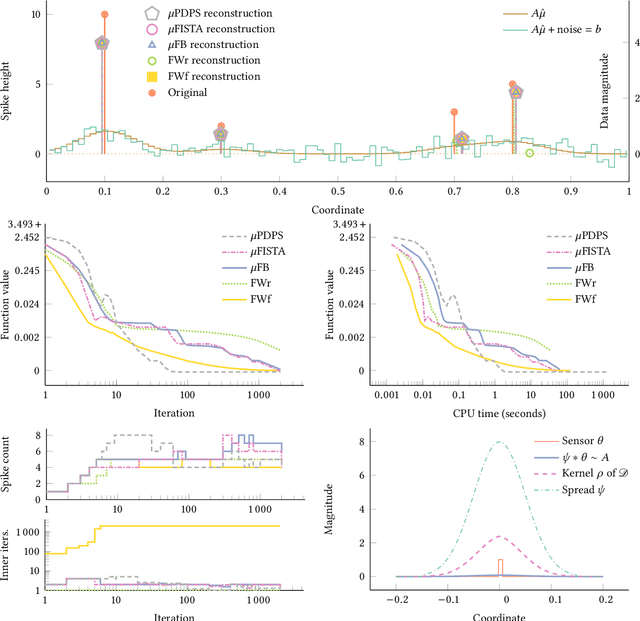



Point source localisation is generally modelled as a Lasso-type problem on measures. However, optimisation methods in non-Hilbert spaces, such as the space of Radon measures, are much less developed than in Hilbert spaces. Most numerical algorithms for point source localisation are based on the Frank-Wolfe conditional gradient method, for which ad hoc convergence theory is developed. We develop extensions of proximal-type methods to spaces of measures. This includes forward-backward splitting, its inertial version, and primal-dual proximal splitting. Their convergence proofs follow standard patterns. We demonstrate their numerical efficacy.
Inverse problems with second-order Total Generalized Variation constraints
May 19, 2020

Total Generalized Variation (TGV) has recently been introduced as penalty functional for modelling images with edges as well as smooth variations. It can be interpreted as a "sparse" penalization of optimal balancing from the first up to the $k$-th distributional derivative and leads to desirable results when applied to image denoising, i.e., $L^2$-fitting with TGV penalty. The present paper studies TGV of second order in the context of solving ill-posed linear inverse problems. Existence and stability for solutions of Tikhonov-functional minimization with respect to the data is shown and applied to the problem of recovering an image from blurred and noisy data.
* Published in 2011 as a conference proceeding. Uploaded in 2020 on arXiv to ensure availability: the original proceedings are no longer online
Predictive online optimisation with applications to optical flow
Feb 08, 2020



Online optimisation revolves around new data being introduced into a problem while it is still being solved; think of deep learning as more training samples become available. We adapt the idea to dynamic inverse problems such as video processing with optical flow. We introduce a corresponding predictive online primal-dual proximal splitting method. The video frames now exactly correspond to the algorithm iterations. A user-prescribed predictor describes the evolution of the primal variable. To prove convergence we need a predictor for the dual variable based on (proximal) gradient flow. This affects the model that the method asymptotically minimises. We show that for inverse problems the effect is, essentially, to construct a new dynamic regulariser based on infimal convolution of the static regularisers with the temporal coupling. We develop regularisation theory for dynamic inverse problems, and show the convergence of the algorithmic solutions in terms of this theory. We finish by demonstrating excellent real-time performance of our method in computational image stabilisation.
Acceleration of the PDHGM on strongly convex subspaces
Feb 10, 2016
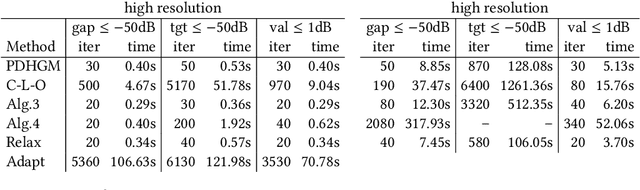
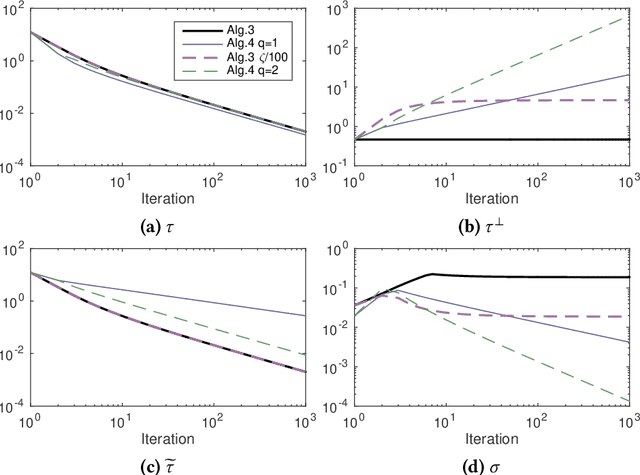
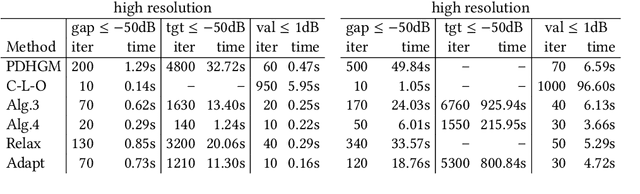
We propose several variants of the primal-dual method due to Chambolle and Pock. Without requiring full strong convexity of the objective functions, our methods are accelerated on subspaces with strong convexity. This yields mixed rates, $O(1/N^2)$ with respect to initialisation and $O(1/N)$ with respect to the dual sequence, and the residual part of the primal sequence. We demonstrate the efficacy of the proposed methods on image processing problems lacking strong convexity, such as total generalised variation denoising and total variation deblurring.
Diffusion tensor imaging with deterministic error bounds
Jan 26, 2016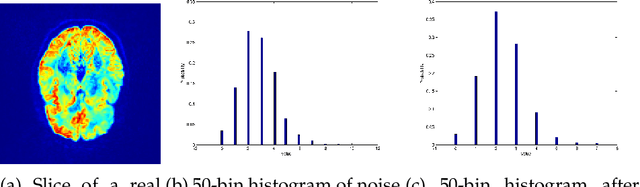

Errors in the data and the forward operator of an inverse problem can be handily modelled using partial order in Banach lattices. We present some existing results of the theory of regularisation in this novel framework, where errors are represented as bounds by means of the appropriate partial order. We apply the theory to Diffusion Tensor Imaging, where correct noise modelling is challenging: it involves the Rician distribution and the nonlinear Stejskal-Tanner equation. Linearisation of the latter in the statistical framework would complicate the noise model even further. We avoid this using the error bounds approach, which preserves simple error structure under monotone transformations.
Bilevel approaches for learning of variational imaging models
May 08, 2015We review some recent learning approaches in variational imaging, based on bilevel optimisation, and emphasize the importance of their treatment in function space. The paper covers both analytical and numerical techniques. Analytically, we include results on the existence and structure of minimisers, as well as optimality conditions for their characterisation. Based on this information, Newton type methods are studied for the solution of the problems at hand, combining them with sampling techniques in case of large databases. The computational verification of the developed techniques is extensively documented, covering instances with different type of regularisers, several noise models, spatially dependent weights and large image databases.
The structure of optimal parameters for image restoration problems
May 08, 2015

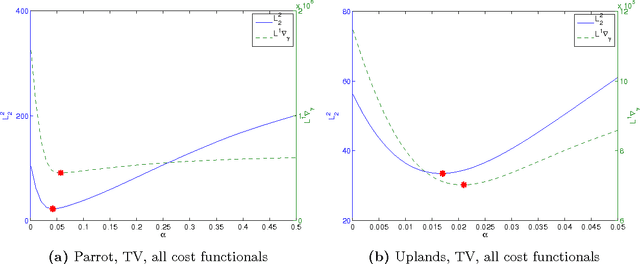
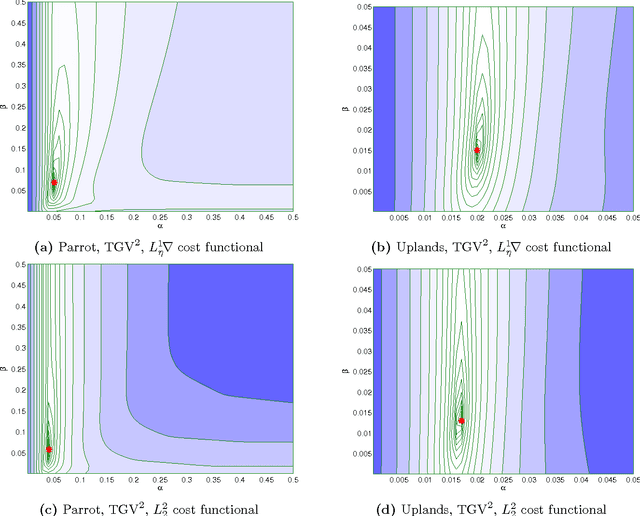
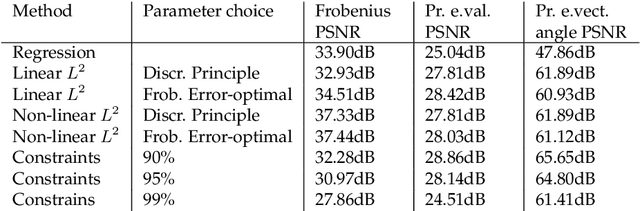
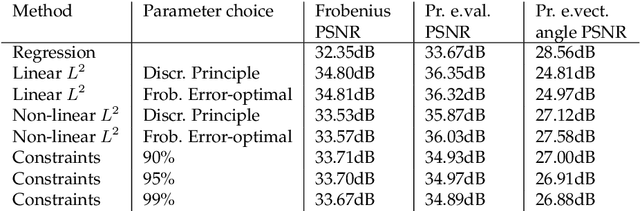
We study the qualitative properties of optimal regularisation parameters in variational models for image restoration. The parameters are solutions of bilevel optimisation problems with the image restoration problem as constraint. A general type of regulariser is considered, which encompasses total variation (TV), total generalized variation (TGV) and infimal-convolution total variation (ICTV). We prove that under certain conditions on the given data optimal parameters derived by bilevel optimisation problems exist. A crucial point in the existence proof turns out to be the boundedness of the optimal parameters away from $0$ which we prove in this paper. The analysis is done on the original -- in image restoration typically non-smooth variational problem -- as well as on a smoothed approximation set in Hilbert space which is the one considered in numerical computations. For the smoothed bilevel problem we also prove that it $\Gamma$ converges to the original problem as the smoothing vanishes. All analysis is done in function spaces rather than on the discretised learning problem.