 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlot2Spectra: an Automatic Spectra Extraction Tool
Jul 06, 2021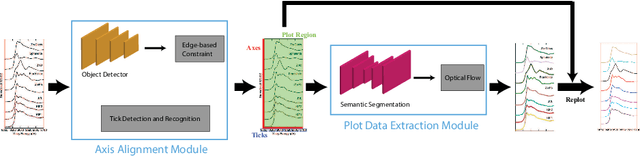
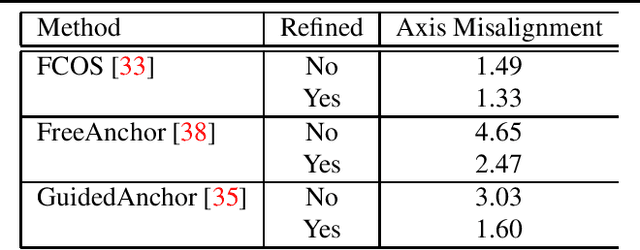
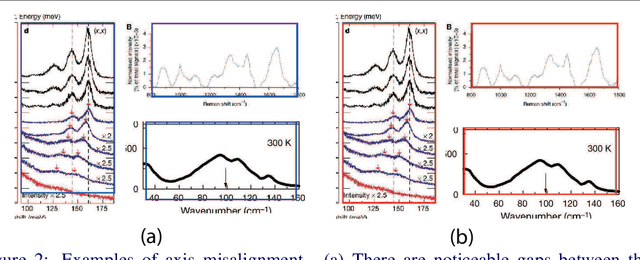
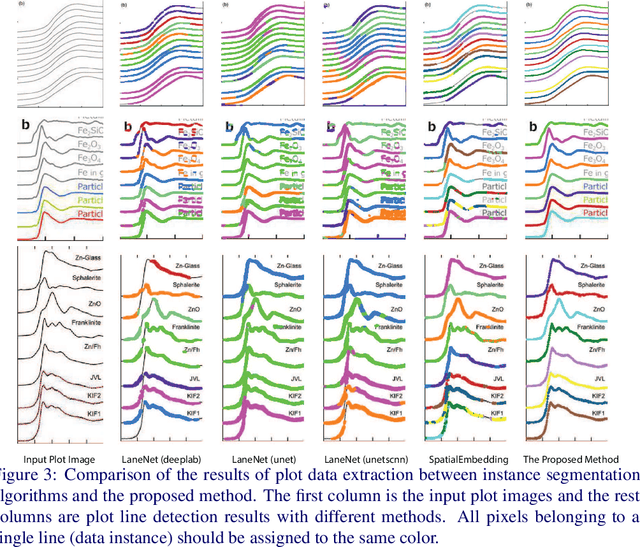
Different types of spectroscopies, such as X-ray absorption near edge structure (XANES) and Raman spectroscopy, play a very important role in analyzing the characteristics of different materials. In scientific literature, XANES/Raman data are usually plotted in line graphs which is a visually appropriate way to represent the information when the end-user is a human reader. However, such graphs are not conducive to direct programmatic analysis due to the lack of automatic tools. In this paper, we develop a plot digitizer, named Plot2Spectra, to extract data points from spectroscopy graph images in an automatic fashion, which makes it possible for large scale data acquisition and analysis. Specifically, the plot digitizer is a two-stage framework. In the first axis alignment stage, we adopt an anchor-free detector to detect the plot region and then refine the detected bounding boxes with an edge-based constraint to locate the position of two axes. We also apply scene text detector to extract and interpret all tick information below the x-axis. In the second plot data extraction stage, we first employ semantic segmentation to separate pixels belonging to plot lines from the background, and from there, incorporate optical flow constraints to the plot line pixels to assign them to the appropriate line (data instance) they encode. Extensive experiments are conducted to validate the effectiveness of the proposed plot digitizer, which shows that such a tool could help accelerate the discovery and machine learning of materials properties.
EXSCLAIM! -- An automated pipeline for the construction of labeled materials imaging datasets from literature
Mar 19, 2021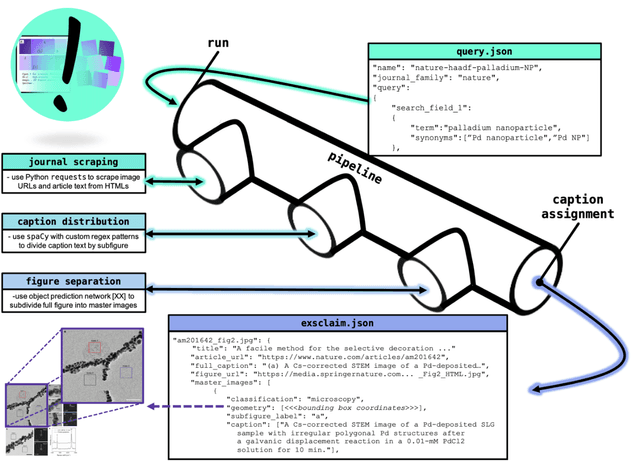

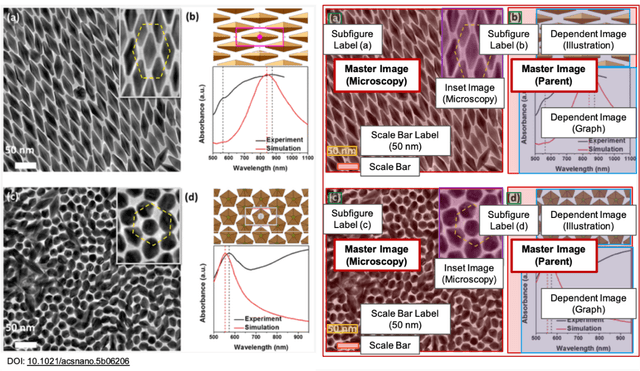
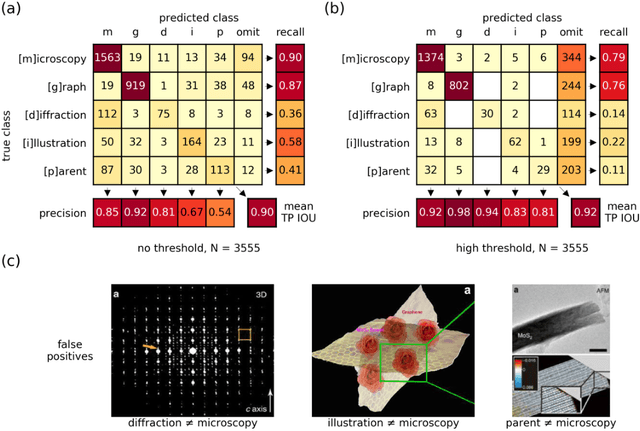
Due to recent improvements in image resolution and acquisition speed, materials microscopy is experiencing an explosion of published imaging data. The standard publication format, while sufficient for traditional data ingestion scenarios where a select number of images can be critically examined and curated manually, is not conducive to large-scale data aggregation or analysis, hindering data sharing and reuse. Most images in publications are presented as components of a larger figure with their explicit context buried in the main body or caption text, so even if aggregated, collections of images with weak or no digitized contextual labels have limited value. To solve the problem of curating labeled microscopy data from literature, this work introduces the EXSCLAIM! Python toolkit for the automatic EXtraction, Separation, and Caption-based natural Language Annotation of IMages from scientific literature. We highlight the methodology behind the construction of EXSCLAIM! and demonstrate its ability to extract and label open-source scientific images at high volume.
A Two-stage Framework for Compound Figure Separation
Jan 25, 2021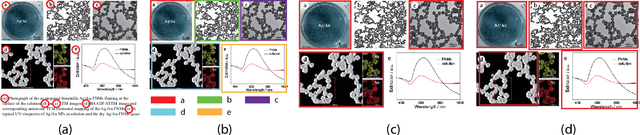
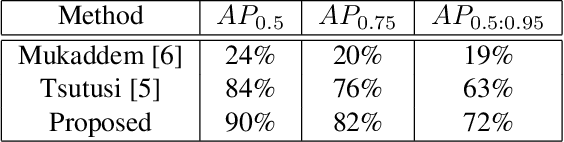

Scientific literature contains large volumes of complex, unstructured figures that are compound in nature (i.e. composed of multiple images, graphs, and drawings). Separation of these compound figures is critical for information retrieval from these figures. In this paper, we propose a new strategy for compound figure separation, which decomposes the compound figures into constituent subfigures while preserving the association between the subfigures and their respective caption components. We propose a two-stage framework to address the proposed compound figure separation problem. In particular, the subfigure label detection module detects all subfigure labels in the first stage. Then, in the subfigure detection module, the detected subfigure labels help to detect the subfigures by optimizing the feature selection process and providing the global layout information as extra features. Extensive experiments are conducted to validate the effectiveness and superiority of the proposed framework, which improves the detection precision by 9%.