 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXSCLAIM! -- An automated pipeline for the construction of labeled materials imaging datasets from literature
Paper and Code
Mar 19, 2021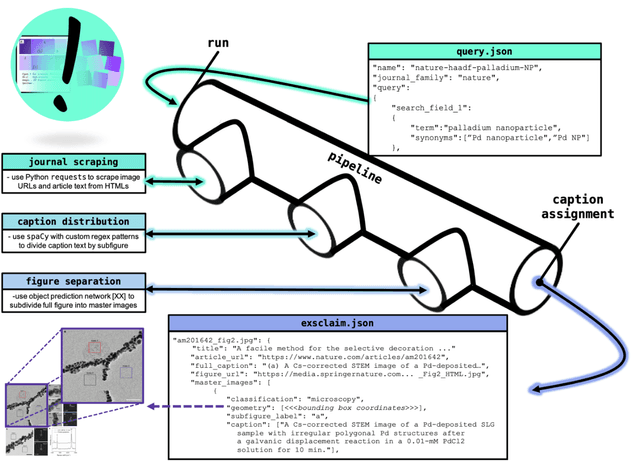

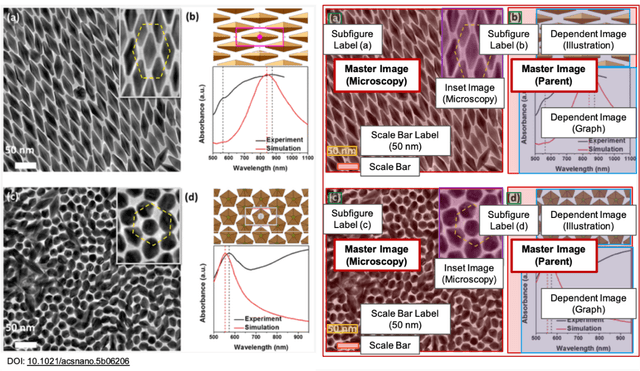
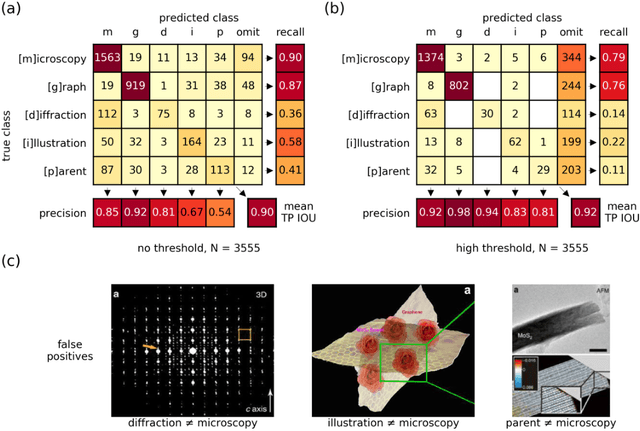
Due to recent improvements in image resolution and acquisition speed, materials microscopy is experiencing an explosion of published imaging data. The standard publication format, while sufficient for traditional data ingestion scenarios where a select number of images can be critically examined and curated manually, is not conducive to large-scale data aggregation or analysis, hindering data sharing and reuse. Most images in publications are presented as components of a larger figure with their explicit context buried in the main body or caption text, so even if aggregated, collections of images with weak or no digitized contextual labels have limited value. To solve the problem of curating labeled microscopy data from literature, this work introduces the EXSCLAIM! Python toolkit for the automatic EXtraction, Separation, and Caption-based natural Language Annotation of IMages from scientific literature. We highlight the methodology behind the construction of EXSCLAIM! and demonstrate its ability to extract and label open-source scientific images at high volume.