 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Heterogeneity Assessment for Multilevel Models
May 06, 2020
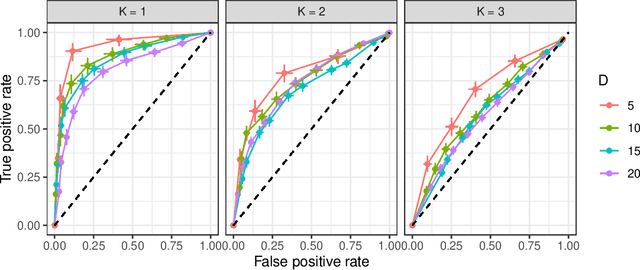

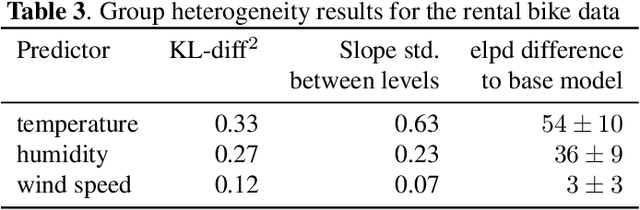
Many data sets contain an inherent multilevel structure, for example, because of repeated measurements of the same observational units. Taking this structure into account is critical for the accuracy and calibration of any statistical analysis performed on such data. However, the large number of possible model configurations hinders the use of multilevel models in practice. In this work, we propose a flexible framework for efficiently assessing differences between the levels of given grouping variables in the data. The assessed group heterogeneity is valuable in choosing the relevant group coefficients to consider in a multilevel model. Our empirical evaluations demonstrate that the framework can reliably identify relevant multilevel components in both simulated and real data sets.
Ranking variables and interactions using predictive uncertainty measures
Oct 17, 2019



For complex nonlinear supervised learning models, assessing the relevance of input variables or their interactions is not straightforward due to the lack of a direct measure of relevance, such as the regression coefficients in generalized linear models. One can assess the relevance of input variables locally by using the mean prediction or its derivative, but this disregards the predictive uncertainty. In this work, we present a Bayesian method for identifying relevant input variables with main effects and interactions by differentiating the Kullback-Leibler divergence of predictive distributions. The method averages over local measures of relevance and has a conservative property that takes into account the uncertainty in the predictive distribution. Our empirical results on simulated and real data sets with nonlinearities demonstrate accurate and efficient identification of relevant main effects and interactions compared to alternative methods.
Pushing the Limits of Importance Sampling through Iterative Moment Matching
Jun 20, 2019



The accuracy of an integral approximation via Monte Carlo sampling depends on the distribution of the integrand and the existence of its moments. In importance sampling, the choice of the proposal distribution markedly affects the existence of these moments and thus the accuracy of the obtained integral approximation. In this work, we present a method for improving the proposal distribution that applies to complicated distributions which are not available in closed form. The method iteratively matches the moments of a sample from the proposal distribution to their importance weighted moments, and is applicable to both standard importance sampling and self-normalized importance sampling. We apply the method to Bayesian leave-one-out cross-validation and show that it can significantly improve the accuracy of model assessment compared to regular Monte Carlo sampling or importance sampling when there are influential observations. We also propose a diagnostic method that can estimate the convergence rate of any Monte Carlo estimator from a finite random sample.
Variable selection for Gaussian processes via sensitivity analysis of the posterior predictive distribution
Oct 10, 2018



Variable selection for Gaussian process models is often done using automatic relevance determination, which uses the inverse length-scale parameter of each input variable as a proxy for variable relevance. This implicitly determined relevance has several drawbacks that prevent the selection of optimal input variables in terms of predictive performance. To improve on this, we propose two novel variable selection methods for Gaussian process models that utilize the predictions of a full model in the vicinity of the training points and thereby rank the variables based on their predictive relevance. Our empirical results on synthetic and real world data sets demonstrate improved variable selection compared to automatic relevance determination in terms of variability and predictive performance.