 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing Stochastic Gradient towards Second-Order Methods -- Backpropagation Learning with Transformations in Nonlinearities
Mar 11, 2013

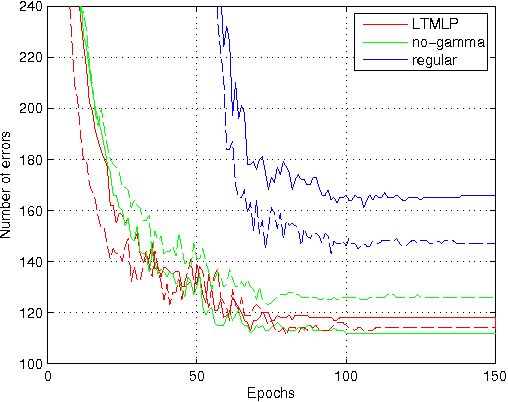
Recently, we proposed to transform the outputs of each hidden neuron in a multi-layer perceptron network to have zero output and zero slope on average, and use separate shortcut connections to model the linear dependencies instead. We continue the work by firstly introducing a third transformation to normalize the scale of the outputs of each hidden neuron, and secondly by analyzing the connections to second order optimization methods. We show that the transformations make a simple stochastic gradient behave closer to second-order optimization methods and thus speed up learning. This is shown both in theory and with experiments. The experiments on the third transformation show that while it further increases the speed of learning, it can also hurt performance by converging to a worse local optimum, where both the inputs and outputs of many hidden neurons are close to zero.
Semi-Supervised Anomaly Detection - Towards Model-Independent Searches of New Physics
Apr 16, 2012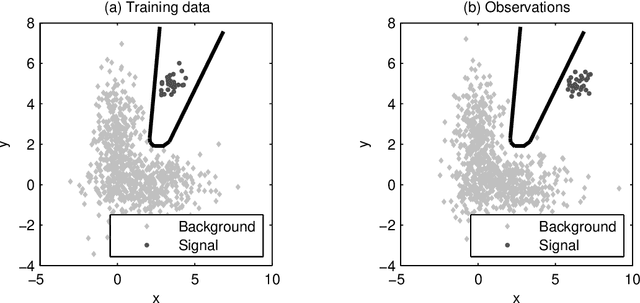
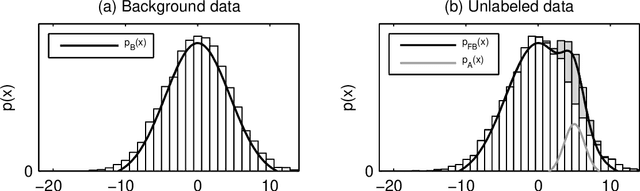
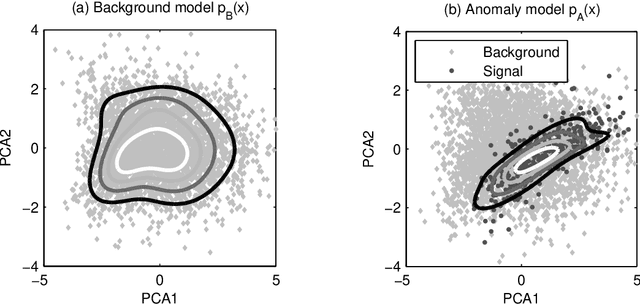
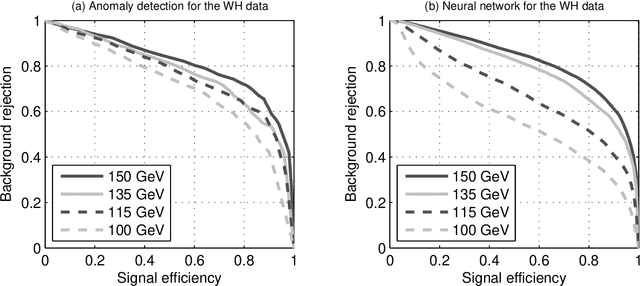
Most classification algorithms used in high energy physics fall under the category of supervised machine learning. Such methods require a training set containing both signal and background events and are prone to classification errors should this training data be systematically inaccurate for example due to the assumed MC model. To complement such model-dependent searches, we propose an algorithm based on semi-supervised anomaly detection techniques, which does not require a MC training sample for the signal data. We first model the background using a multivariate Gaussian mixture model. We then search for deviations from this model by fitting to the observations a mixture of the background model and a number of additional Gaussians. This allows us to perform pattern recognition of any anomalous excess over the background. We show by a comparison to neural network classifiers that such an approach is a lot more robust against misspecification of the signal MC than supervised classification. In cases where there is an unexpected signal, a neural network might fail to correctly identify it, while anomaly detection does not suffer from such a limitation. On the other hand, when there are no systematic errors in the training data, both methods perform comparably.