 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Meta Classifier: Improving the Reliability of Anomaly Segmentation
Dec 14, 2024

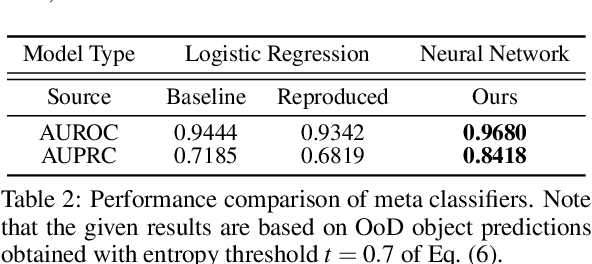

Deep neural networks (DNNs) are a contemporary solution for semantic segmentation and are usually trained to operate on a predefined closed set of classes. In open-set environments, it is possible to encounter semantically unknown objects or anomalies. Road driving is an example of such an environment in which, from a safety standpoint, it is important to ensure that a DNN indicates it is operating outside of its learned semantic domain. One possible approach to anomaly segmentation is entropy maximization, which is paired with a logistic regression based post-processing step called meta classification, which is in turn used to improve the reliability of detection of anomalous pixels. We propose to substitute the logistic regression meta classifier with a more expressive lightweight fully connected neural network. We analyze advantages and drawbacks of the proposed neural network meta classifier and demonstrate its better performance over logistic regression. We also introduce the concept of informative out-of-distribution examples which we show to improve training results when using entropy maximization in practice. Finally, we discuss the loss of interpretability and show that the behavior of logistic regression and neural network is strongly correlated.
A Note on Geometric Calibration of Multiple Cameras and Projectors
Oct 24, 2024



Geometric calibration of cameras and projectors is an essential step that must be performed before any imaging system can be used. There are many well-known geometric calibration methods for calibrating systems comprised of multiple cameras, but simultaneous geometric calibration of multiple projectors and cameras has received less attention. This leaves unresolved several practical issues which must be considered to achieve the simplicity of use required for real world applications. In this work we discuss several important components of a real-world geometric calibration procedure used in our laboratory to calibrate surface imaging systems comprised of many projectors and cameras. We specifically discuss the design of the calibration object and the image processing pipeline used to analyze it in the acquired images. We also provide quantitative calibration results in the form of reprojection errors and compare them to the classic approaches such as Zhang's calibration method.
Can Human Sex Be Learned Using Only 2D Body Keypoint Estimations?
Nov 05, 2020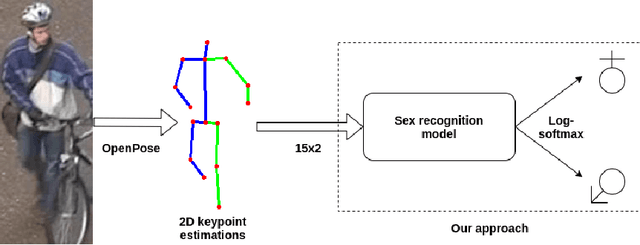

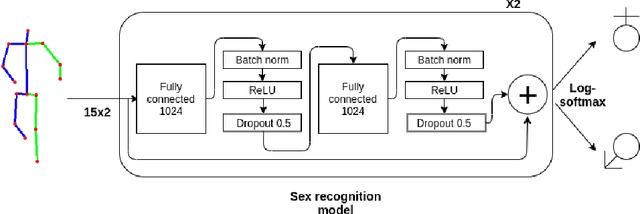
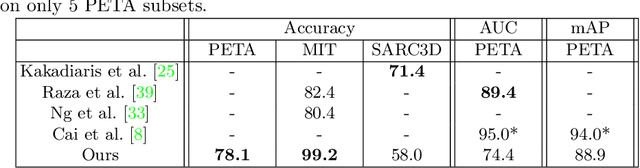
In this paper, we analyze human male and female sex recognition problem and present a fully automated classification system using only 2D keypoints. The keypoints represent human joints. A keypoint set consists of 15 joints and the keypoint estimations are obtained using an OpenPose 2D keypoint detector. We learn a deep learning model to distinguish males and females using the keypoints as input and binary labels as output. We use two public datasets in the experimental section - 3DPeople and PETA. On PETA dataset, we report a 77% accuracy. We provide model performance details on both PETA and 3DPeople. To measure the effect of noisy 2D keypoint detections on the performance, we run separate experiments on 3DPeople ground truth and noisy keypoint data. Finally, we extract a set of factors that affect the classification accuracy and propose future work. The advantage of the approach is that the input is small and the architecture is simple, which enables us to run many experiments and keep the real-time performance in inference. The source code, with the experiments and data preparation scripts, are available on GitHub (https://github.com/kristijanbartol/human-sex-classifier).
Smart Time-Multiplexing of Quads Solves the Multicamera Interference Problem
Nov 05, 2020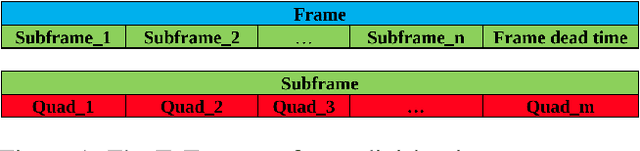
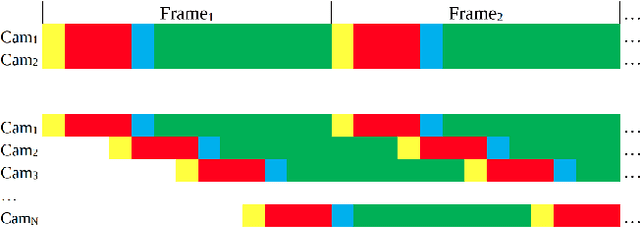
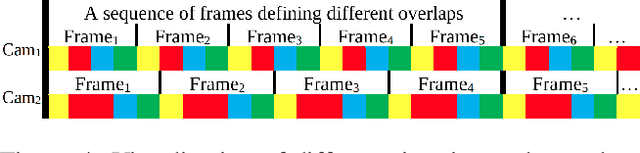
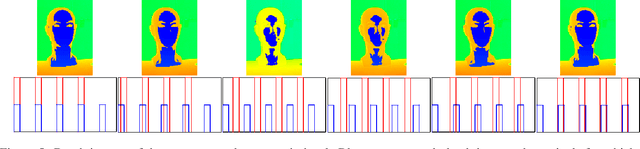
Time-of-flight (ToF) cameras are becoming increasingly popular for 3D imaging. Their optimal usage has been studied from the several aspects. One of the open research problems is the possibility of a multicamera interference problem when two or more ToF cameras are operating simultaneously. In this work we present an efficient method to synchronize multiple operating ToF cameras. Our method is based on the time-division multiplexing, but unlike traditional time multiplexing, it does not decrease the effective camera frame rate. Additionally, for unsynchronized cameras, we provide a robust method to extract from their corresponding video streams, frames which are not subject to multicamera interference problem. We demonstrate our approach through a series of experiments and with a different level of support available for triggering, ranging from a hardware triggering to purely random software triggering.
Towards Keypoint Guided Self-Supervised Depth Estimation
Nov 05, 2020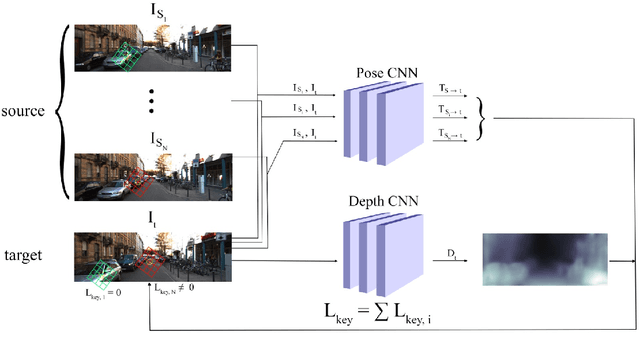
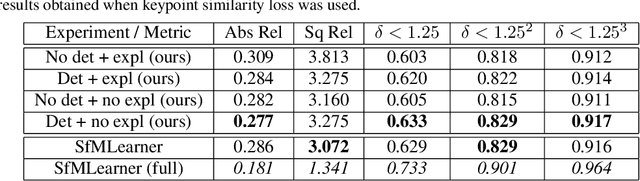
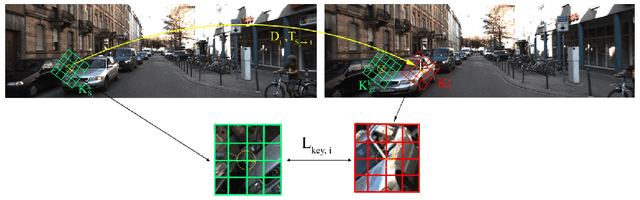
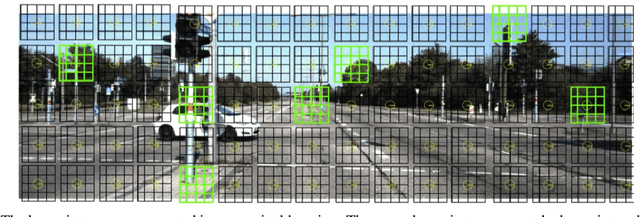
This paper proposes to use keypoints as a self-supervision clue for learning depth map estimation from a collection of input images. As ground truth depth from real images is difficult to obtain, there are many unsupervised and self-supervised approaches to depth estimation that have been proposed. Most of these unsupervised approaches use depth map and ego-motion estimations to reproject the pixels from the current image into the adjacent image from the image collection. Depth and ego-motion estimations are evaluated based on pixel intensity differences between the correspondent original and reprojected pixels. Instead of reprojecting the individual pixels, we propose to first select image keypoints in both images and then reproject and compare the correspondent keypoints of the two images. The keypoints should describe the distinctive image features well. By learning a deep model with and without the keypoint extraction technique, we show that using the keypoints improve the depth estimation learning. We also propose some future directions for keypoint-guided learning of structure-from-motion problems.