 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Keypoint Guided Self-Supervised Depth Estimation
Paper and Code
Nov 05, 2020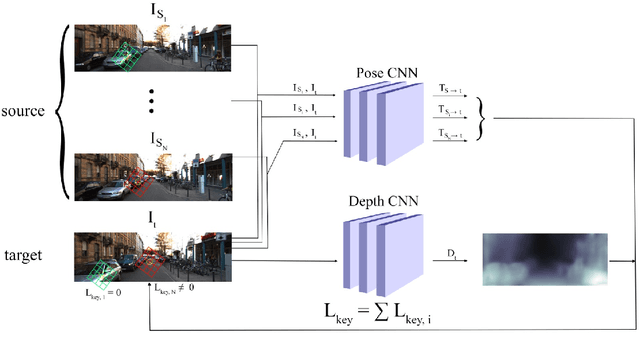
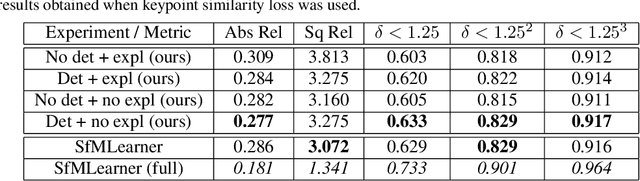
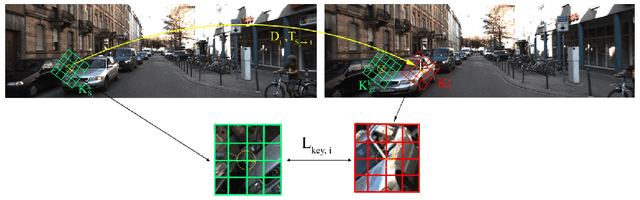
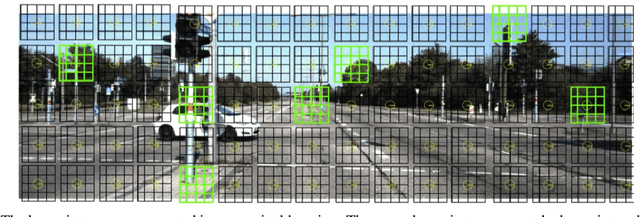
This paper proposes to use keypoints as a self-supervision clue for learning depth map estimation from a collection of input images. As ground truth depth from real images is difficult to obtain, there are many unsupervised and self-supervised approaches to depth estimation that have been proposed. Most of these unsupervised approaches use depth map and ego-motion estimations to reproject the pixels from the current image into the adjacent image from the image collection. Depth and ego-motion estimations are evaluated based on pixel intensity differences between the correspondent original and reprojected pixels. Instead of reprojecting the individual pixels, we propose to first select image keypoints in both images and then reproject and compare the correspondent keypoints of the two images. The keypoints should describe the distinctive image features well. By learning a deep model with and without the keypoint extraction technique, we show that using the keypoints improve the depth estimation learning. We also propose some future directions for keypoint-guided learning of structure-from-motion problems.