 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADC-Net: An Open-Source Deep Learning Network for Automated Dispersion Compensation in Optical Coherence Tomography
Jan 29, 2022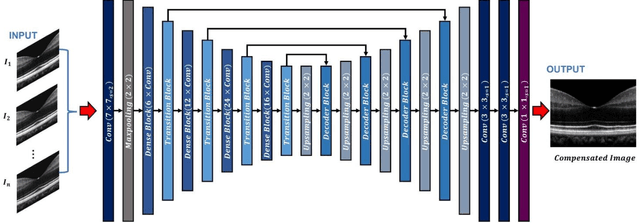
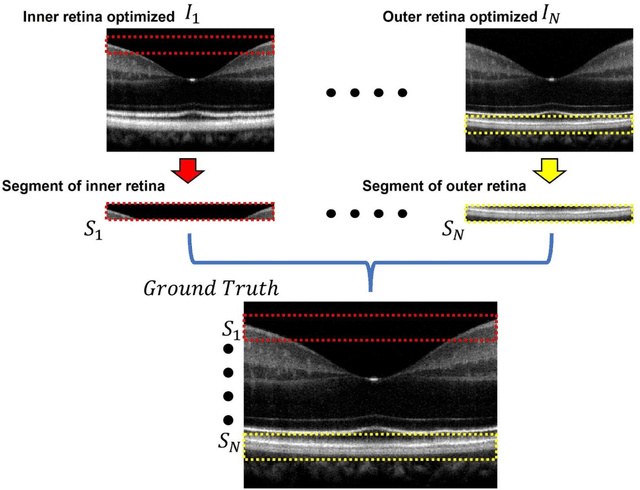
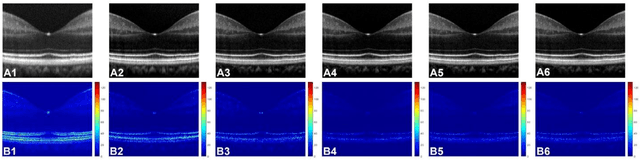
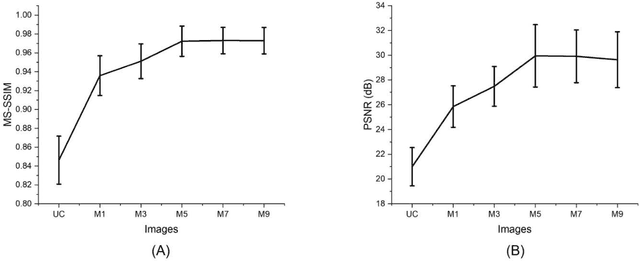
Chromatic dispersion is a common problem to degrade the system resolution in optical coherence tomography (OCT). This study is to develop a deep learning network for automated dispersion compensation (ADC-Net) in OCT. The ADC-Net is based on a redesigned UNet architecture which employs an encoder-decoder pipeline. The input section encompasses partially compensated OCT B-scans with individual retinal layers optimized. Corresponding output is a fully compensated OCT B-scans with all retinal layers optimized. Two numeric parameters, i.e., peak signal to noise ratio (PSNR) and structural similarity index metric computed at multiple scales (MS-SSIM), were used for objective assessment of the ADC-Net performance. Comparative analysis of training models, including single, three, five, seven and nine input channels were implemented. The five-input channels implementation was observed as the optimal mode for ADC-Net training to achieve robust dispersion compensation in OCT
Depth-resolved vascular profile features for artery-vein classification in OCT and OCT angiography of human retina
Dec 14, 2021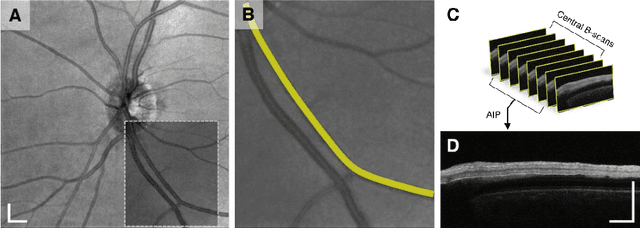
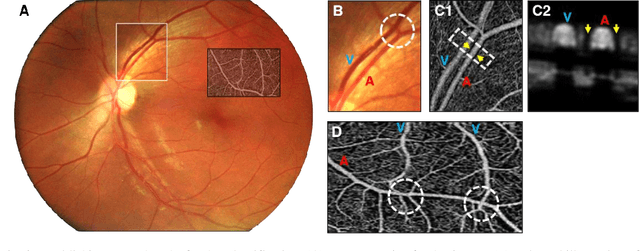
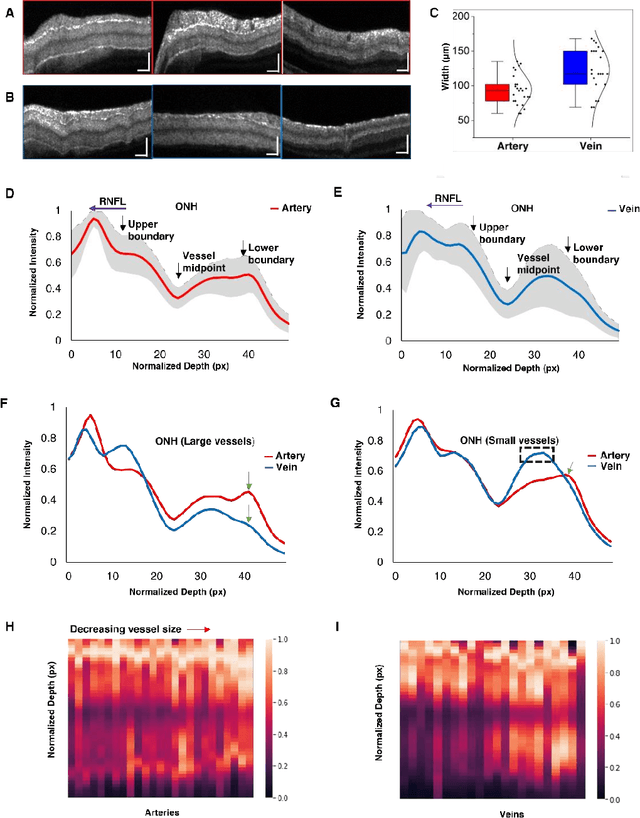
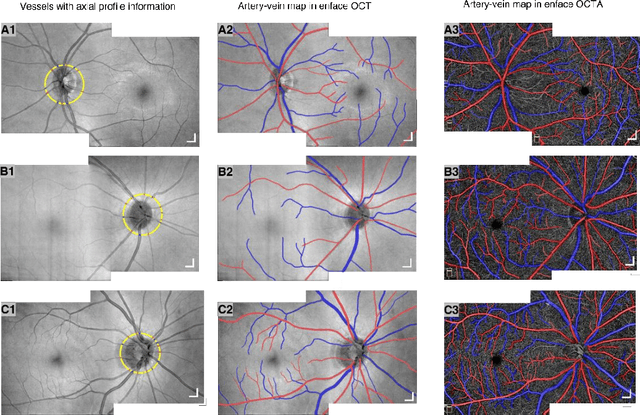
This study is to characterize reflectance profiles of retinal blood vessels in optical coherence tomography (OCT), and to validate these vascular features to guide artery-vein classification in OCT angiography (OCTA) of human retina. Depth-resolved OCT reveals unique features of retinal arteries and veins. Retinal arteries show hyper-reflective boundaries at both upper (inner side towards the vitreous) and lower (outer side towards the choroid) walls. In contrary, retinal veins reveal hyper-reflectivity at the upper boundary only. Uniform lumen intensity was observed in both small and large arteries. However, the vein lumen intensity was dependent on the vessel size. Small veins exhibit a hyper-reflective zone at the bottom half of the lumen, while large veins show a hypo-reflective zone at the bottom half of the lumen
Human Activity Recognition using Deep Learning Models on Smartphones and Smartwatches Sensor Data
Feb 28, 2021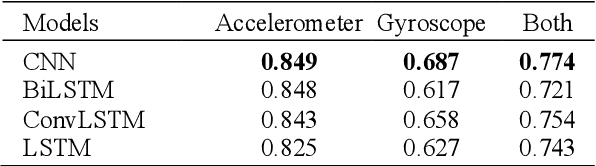
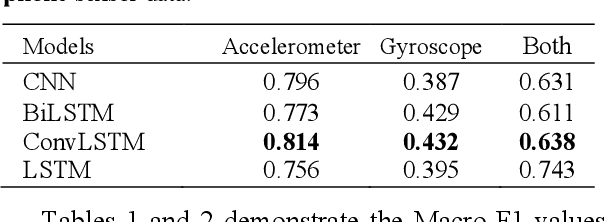
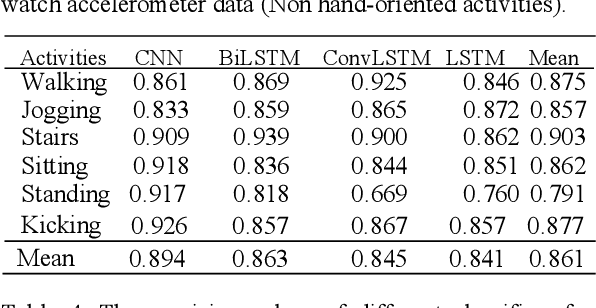
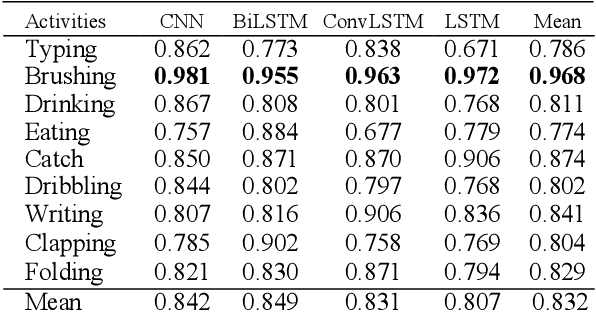
In recent years, human activity recognition has garnered considerable attention both in industrial and academic research because of the wide deployment of sensors, such as accelerometers and gyroscopes, in products such as smartphones and smartwatches. Activity recognition is currently applied in various fields where valuable information about an individual's functional ability and lifestyle is needed. In this study, we used the popular WISDM dataset for activity recognition. Using multivariate analysis of covariance (MANCOVA), we established a statistically significant difference (p<0.05) between the data generated from the sensors embedded in smartphones and smartwatches. By doing this, we show that smartphones and smartwatches don't capture data in the same way due to the location where they are worn. We deployed several neural network architectures to classify 15 different hand and non-hand-oriented activities. These models include Long short-term memory (LSTM), Bi-directional Long short-term memory (BiLSTM), Convolutional Neural Network (CNN), and Convolutional LSTM (ConvLSTM). The developed models performed best with watch accelerometer data. Also, we saw that the classification precision obtained with the convolutional input classifiers (CNN and ConvLSTM) was higher than the end-to-end LSTM classifier in 12 of the 15 activities. Additionally, the CNN model for the watch accelerometer was better able to classify non-hand oriented activities when compared to hand-oriented activities.