 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHetroD: A High-Fidelity Drone Dataset and Benchmark for Autonomous Driving in Heterogeneous Traffic
Feb 03, 2026We present HetroD, a dataset and benchmark for developing autonomous driving systems in heterogeneous environments. HetroD targets the critical challenge of navi- gating real-world heterogeneous traffic dominated by vulner- able road users (VRUs), including pedestrians, cyclists, and motorcyclists that interact with vehicles. These mixed agent types exhibit complex behaviors such as hook turns, lane splitting, and informal right-of-way negotiation. Such behaviors pose significant challenges for autonomous vehicles but remain underrepresented in existing datasets focused on structured, lane-disciplined traffic. To bridge the gap, we collect a large- scale drone-based dataset to provide a holistic observation of traffic scenes with centimeter-accurate annotations, HD maps, and traffic signal states. We further develop a modular toolkit for extracting per-agent scenarios to support downstream task development. In total, the dataset comprises over 65.4k high- fidelity agent trajectories, 70% of which are from VRUs. HetroD supports modeling of VRU behaviors in dense, het- erogeneous traffic and provides standardized benchmarks for forecasting, planning, and simulation tasks. Evaluation results reveal that state-of-the-art prediction and planning models struggle with the challenges presented by our dataset: they fail to predict lateral VRU movements, cannot handle unstructured maneuvers, and exhibit limited performance in dense and multi-agent scenarios, highlighting the need for more robust approaches to heterogeneous traffic. See our project page for more examples: https://hetroddata.github.io/HetroD/
A Semi-Automated Corner Case Detection and Evaluation Pipeline
May 25, 2023In order to deploy automated vehicles to the public, it has to be proven that the vehicle can safely and robustly handle traffic in many different scenarios. One important component of automated vehicles is the perception system that captures and processes the environment around the vehicle. Perception systems require large datasets for training their deep neural network. Knowing which parts of the data in these datasets describe a corner case is an advantage during training or testing of the network. These corner cases describe situations that are rare and potentially challenging for the network. We propose a pipeline that converts collective expert knowledge descriptions into the extended KI Absicherung ontology. The ontology is used to describe scenes and scenarios that can be mapped to perception datasets. The corner cases can then be extracted from the datasets. In addition, the pipeline enables the evaluation of the detection networks against the extracted corner cases to measure their performance.
The inD Dataset: A Drone Dataset of Naturalistic Road User Trajectories at German Intersections
Nov 18, 2019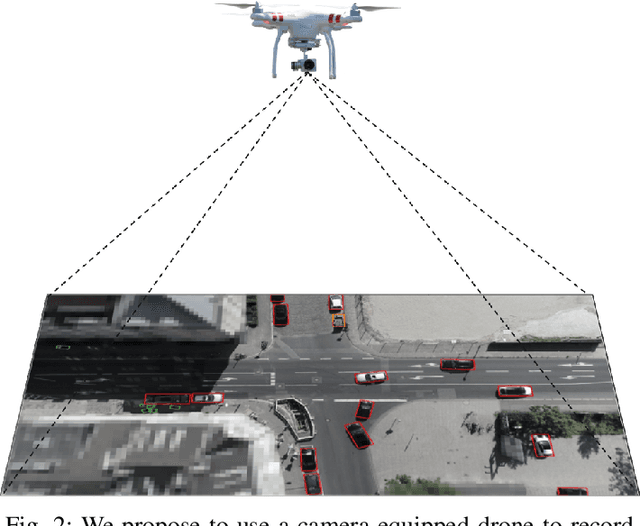


Automated vehicles rely heavily on data-driven methods, especially for complex urban environments. Large datasets of real world measurement data in the form of road user trajectories are crucial for several tasks like road user prediction models or scenario-based safety validation. So far, though, this demand is unmet as no public dataset of urban road user trajectories is available in an appropriate size, quality and variety. By contrast, the highway drone dataset (highD) has recently shown that drones are an efficient method for acquiring naturalistic road user trajectories. Compared to driving studies or ground-level infrastructure sensors, one major advantage of using a drone is the possibility to record naturalistic behavior, as road users do not notice measurements taking place. Due to the ideal viewing angle, an entire intersection scenario can be measured with significantly less occlusion than with sensors at ground level. Both the class and the trajectory of each road user can be extracted from the video recordings with high precision using state-of-the-art deep neural networks. Therefore, we propose the creation of a comprehensive, large-scale urban intersection dataset with naturalistic road user behavior using camera-equipped drones as successor of the highD dataset. The resulting dataset contains more than 11500 road users including vehicles, bicyclists and pedestrians at intersections in Germany and is called inD. The dataset consists of 10 hours of measurement data from four intersections and is available online for non-commercial research at: http://www.inD-dataset.com
Social Emotion Mining Techniques for Facebook Posts Reaction Prediction
Dec 08, 2017
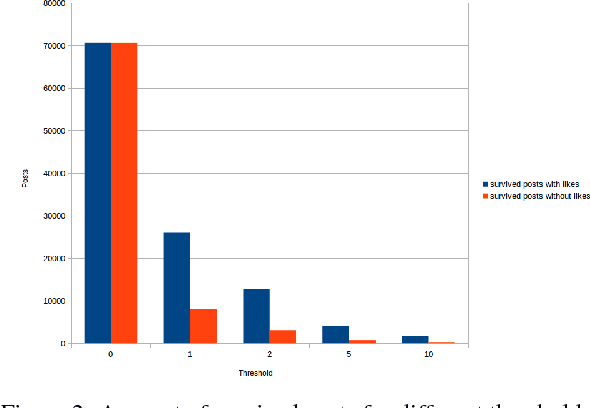

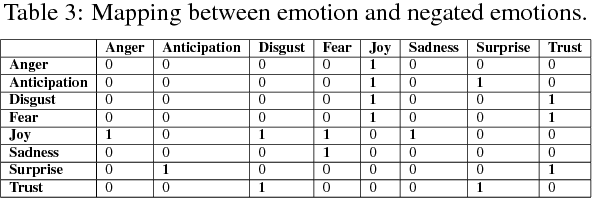
As of February 2016 Facebook allows users to express their experienced emotions about a post by using five so-called `reactions'. This research paper proposes and evaluates alternative methods for predicting these reactions to user posts on public pages of firms/companies (like supermarket chains). For this purpose, we collected posts (and their reactions) from Facebook pages of large supermarket chains and constructed a dataset which is available for other researches. In order to predict the distribution of reactions of a new post, neural network architectures (convolutional and recurrent neural networks) were tested using pretrained word embeddings. Results of the neural networks were improved by introducing a bootstrapping approach for sentiment and emotion mining on the comments for each post. The final model (a combination of neural network and a baseline emotion miner) is able to predict the reaction distribution on Facebook posts with a mean squared error (or misclassification rate) of 0.135.