 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Umwelt Representation Hypothesis: Rethinking Universality
Apr 20, 2026Recent studies reveal striking representational alignment between artificial neural networks (ANNs) and biological brains, leading to proposals that all sufficiently capable systems converge on universal representations of reality. Here, we argue that this claim of Universality is premature. We introduce the Umwelt Representation Hypothesis (URH), proposing that alignment arises not from convergence toward a single global optimum, but from overlap in ecological constraints under which systems develop. We review empirical evidence showing that representational differences between species, individuals, and ANNs are systematic and adaptive, which is difficult to reconcile with Universality. Finally, we reframe ANN model comparison as a method for mapping clusters of alignment in ecological constraint space rather than searching for a single optimal world model.
A Minimal Task Reveals Emergent Path Integration and Object-Location Binding in a Predictive Sequence Model
Feb 03, 2026Adaptive cognition requires structured internal models representing objects and their relations. Predictive neural networks are often proposed to form such "world models", yet their underlying mechanisms remain unclear. One hypothesis is that action-conditioned sequential prediction suffices for learning such world models. In this work, we investigate this possibility in a minimal in-silico setting. Sequentially sampling tokens from 2D continuous token scenes, a recurrent neural network is trained to predict the upcoming token from current input and a saccade-like displacement. On novel scenes, prediction accuracy improves across the sequence, indicating in-context learning. Decoding analyses reveal path integration and dynamic binding of token identity to position. Interventional analyses show that new bindings can be learned late in sequence and that out-of-distribution bindings can be learned. Together, these results demonstrate how structured representations that rely on flexible binding emerge to support prediction, offering a mechanistic account of sequential world modeling relevant to cognitive science.
End-to-end topographic networks as models of cortical map formation and human visual behaviour: moving beyond convolutions
Aug 18, 2023Computational models are an essential tool for understanding the origin and functions of the topographic organisation of the primate visual system. Yet, vision is most commonly modelled by convolutional neural networks that ignore topography by learning identical features across space. Here, we overcome this limitation by developing All-Topographic Neural Networks (All-TNNs). Trained on visual input, several features of primate topography emerge in All-TNNs: smooth orientation maps and cortical magnification in their first layer, and category-selective areas in their final layer. In addition, we introduce a novel dataset of human spatial biases in object recognition, which enables us to directly link models to behaviour. We demonstrate that All-TNNs significantly better align with human behaviour than previous state-of-the-art convolutional models due to their topographic nature. All-TNNs thereby mark an important step forward in understanding the spatial organisation of the visual brain and how it mediates visual behaviour.
Semantic scene descriptions as an objective of human vision
Sep 23, 2022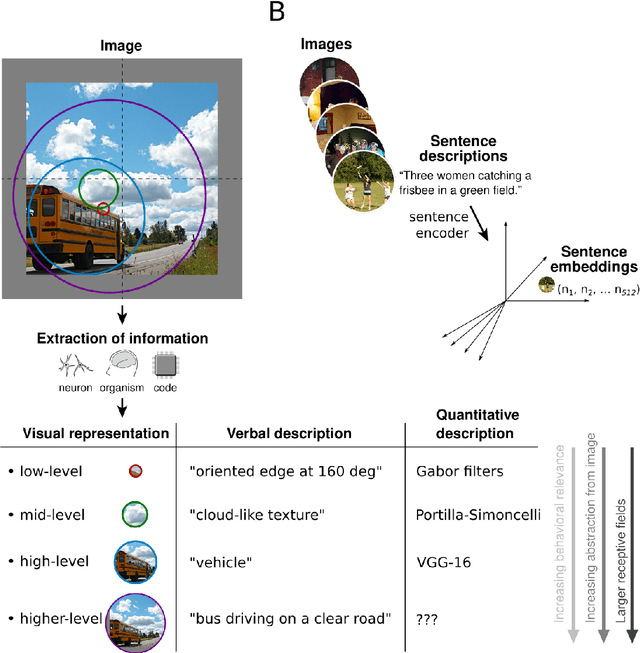
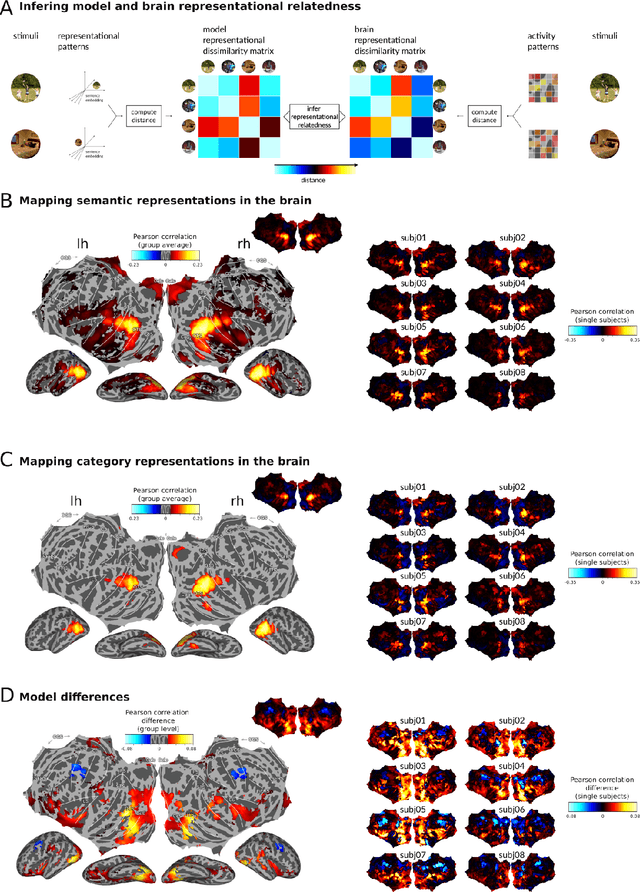


Interpreting the meaning of a visual scene requires not only identification of its constituent objects, but also a rich semantic characterization of object interrelations. Here, we study the neural mechanisms underlying visuo-semantic transformations by applying modern computational techniques to a large-scale 7T fMRI dataset of human brain responses elicited by complex natural scenes. Using semantic embeddings obtained by applying linguistic deep learning models to human-generated scene descriptions, we identify a widely distributed network of brain regions that encode semantic scene descriptions. Importantly, these semantic embeddings better explain activity in these regions than traditional object category labels. In addition, they are effective predictors of activity despite the fact that the participants did not actively engage in a semantic task, suggesting that visuo-semantic transformations are a default mode of vision. In support of this view, we then show that highly accurate reconstructions of scene captions can be directly linearly decoded from patterns of brain activity. Finally, a recurrent convolutional neural network trained on semantic embeddings further outperforms semantic embeddings in predicting brain activity, providing a mechanistic model of the brain's visuo-semantic transformations. Together, these experimental and computational results suggest that transforming visual input into rich semantic scene descriptions may be a central objective of the visual system, and that focusing efforts on this new objective may lead to improved models of visual information processing in the human brain.
Recurrence required to capture the dynamic computations of the human ventral visual stream
Mar 14, 2019



The visual system is an intricate network of brain regions that enables us to recognize the world around us. Despite its abundant lateral and feedback connections, human object processing is commonly viewed and studied as a feedforward process. Here, we measure and model the rapid representational dynamics across multiple stages of the human ventral stream using time-resolved brain imaging and deep learning. We observe substantial representational transformations during the first 300 ms of processing within and across ventral-stream regions. Categorical divisions emerge in sequence, cascading forward and in reverse across regions, and Granger causality analysis suggests bidirectional information flow between regions. Finally, recurrent deep neural network models clearly outperform feedforward models in terms of their ability to jointly capture the multi-region cortical dynamics. These results establish that recurrent models are required to understand information processing in the human ventral stream.