 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neighbor-based Approach to Pitch Ownership Models in Soccer
Jan 10, 2025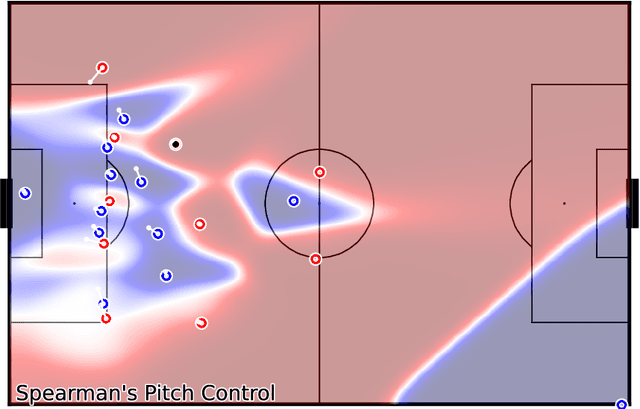
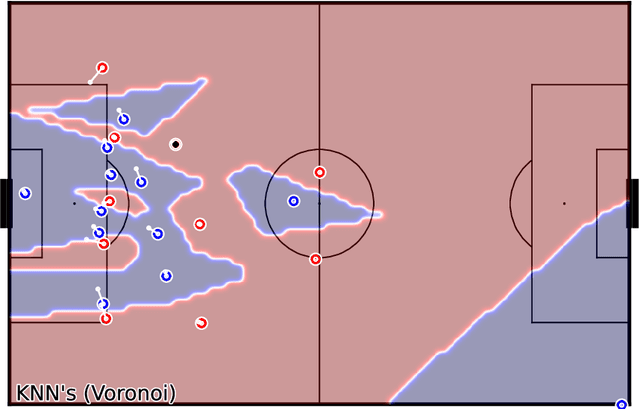
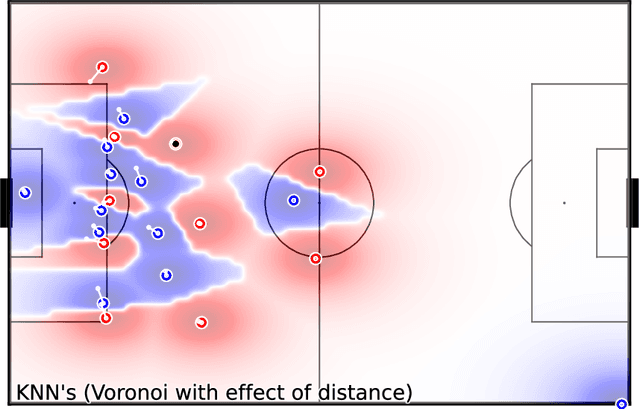
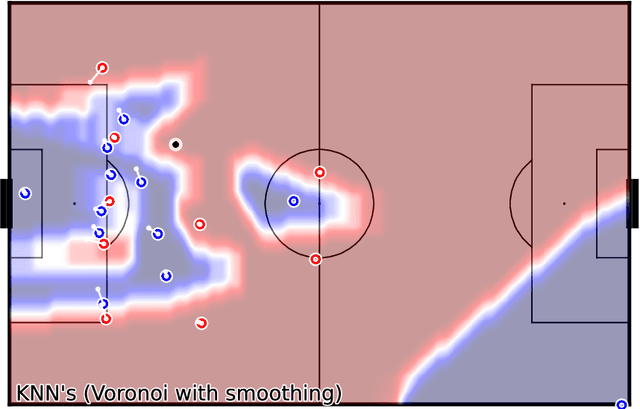
Pitch ownership models allow many types of analysis in soccer and provide valuable assistance to tactical analysts in understanding the game's dynamics. The novelty they provide over event-based analysis is that tracking data incorporates context that event-based data does not possess, like player positioning. This paper proposes a novel approach to building pitch ownership models in soccer games using the K-Nearest Neighbors (KNN) algorithm. Our approach provides a fast inference mechanism that can model different approaches to pitch control using the same algorithm. Despite its flexibility, it uses only three hyperparameters to tune the model, facilitating the tuning process for different player skill levels. The flexibility of the approach allows for the emulation of different methods available in the literature by adjusting a small number of parameters, including adjusting for different levels of uncertainty. In summary, the proposed model provides a new and more flexible strategy for building pitch ownership models, extending beyond just replicating existing algorithms, and can provide valuable insights for tactical analysts and open up new avenues for future research. We thoroughly visualize several examples demonstrating the presented models' strengths and weaknesses. The code is available at github.com/nvsclub/KNNPitchControl.
Forecasting Events in Soccer Matches Through Language
Feb 09, 2024

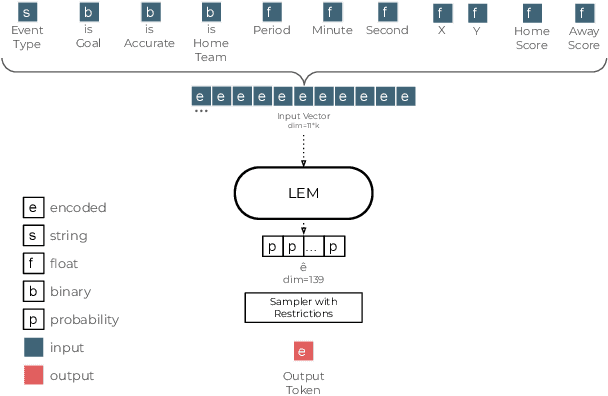
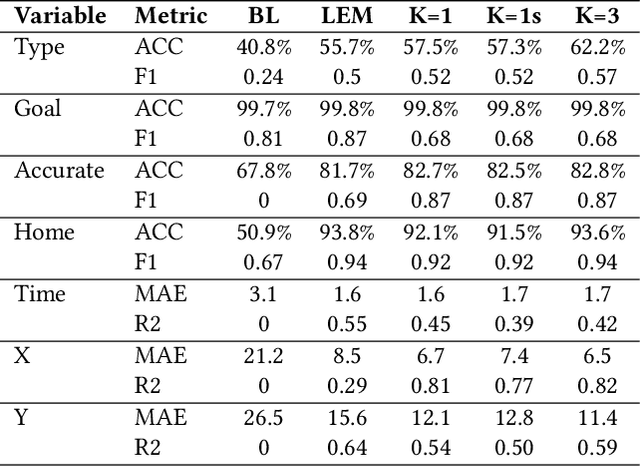
This paper introduces an approach to predicting the next event in a soccer match, a challenge bearing remarkable similarities to the problem faced by Large Language Models (LLMs). Unlike other methods that severely limit event dynamics in soccer, often abstracting from many variables or relying on a mix of sequential models, our research proposes a novel technique inspired by the methodologies used in LLMs. These models predict a complete chain of variables that compose an event, significantly simplifying the construction of Large Event Models (LEMs) for soccer. Utilizing deep learning on the publicly available WyScout dataset, the proposed approach notably surpasses the performance of previous LEM proposals in critical areas, such as the prediction accuracy of the next event type. This paper highlights the utility of LEMs in various applications, including betting and match analytics. Moreover, we show that LEMs provide a simulation backbone on which many analytics pipelines can be built, an approach opposite to the current specialized single-purpose models. LEMs represent a pivotal advancement in soccer analytics, establishing a foundational framework for multifaceted analytics pipelines through a singular machine-learning model.
Estimating Player Performance in Different Contexts Using Fine-tuned Large Events Models
Feb 09, 2024



This paper introduces an innovative application of Large Event Models (LEMs), akin to Large Language Models, to the domain of soccer analytics. By learning the "language" of soccer - predicting variables for subsequent events rather than words LEMs facilitate the simulation of matches and offer various applications, including player performance prediction across different team contexts. We focus on fine-tuning LEMs with the WyScout dataset for the 2017-2018 Premier League season to derive specific insights into player contributions and team strategies. Our methodology involves adapting these models to reflect the nuanced dynamics of soccer, enabling the evaluation of hypothetical transfers. Our findings confirm the effectiveness and limitations of LEMs in soccer analytics, highlighting the model's capability to forecast teams' expected standings and explore high-profile scenarios, such as the potential effects of transferring Cristiano Ronaldo or Lionel Messi to different teams in the Premier League. This analysis underscores the importance of context in evaluating player quality. While general metrics may suggest significant differences between players, contextual analyses reveal narrower gaps in performance within specific team frameworks.
Towards a Systematic Approach to Design New Ensemble Learning Algorithms
Feb 09, 2024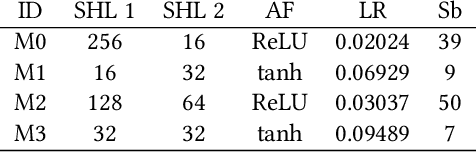


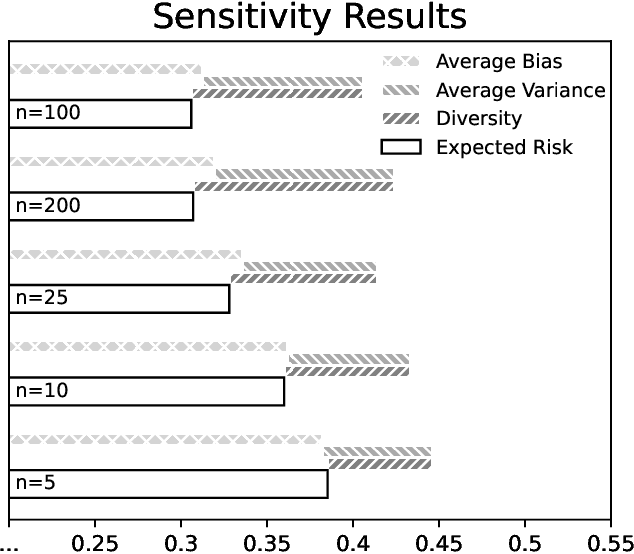
Ensemble learning has been a focal point of machine learning research due to its potential to improve predictive performance. This study revisits the foundational work on ensemble error decomposition, historically confined to bias-variance-covariance analysis for regression problems since the 1990s. Recent advancements introduced a "unified theory of diversity," which proposes an innovative bias-variance-diversity decomposition framework. Leveraging this contemporary understanding, our research systematically explores the application of this decomposition to guide the creation of new ensemble learning algorithms. Focusing on regression tasks, we employ neural networks as base learners to investigate the practical implications of this theoretical framework. This approach used 7 simple ensemble methods, we name them strategies, for neural networks that were used to generate 21 new ensemble algorithms. Among these, most of the methods aggregated with the snapshot strategy, one of the 7 strategies used, showcase superior predictive performance across diverse datasets w.r.t. the Friedman rank test with the Conover post-hoc test. Our systematic design approach contributes a suite of effective new algorithms and establishes a structured pathway for future ensemble learning algorithm development.
A Survey of Advanced Computer Vision Techniques for Sports
Jan 18, 2023

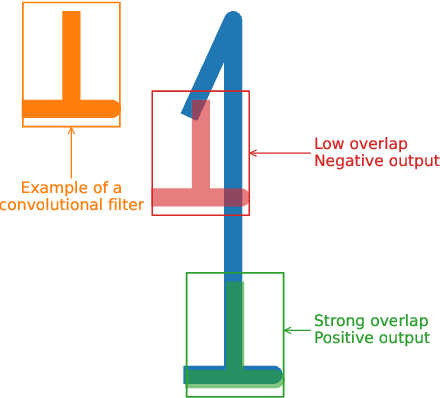
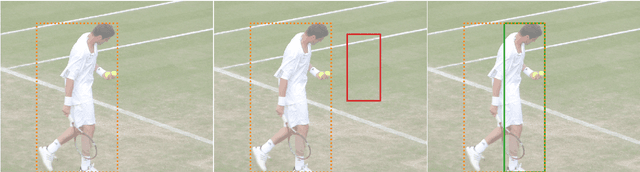
Computer Vision developments are enabling significant advances in many fields, including sports. Many applications built on top of Computer Vision technologies, such as tracking data, are nowadays essential for every top-level analyst, coach, and even player. In this paper, we survey Computer Vision techniques that can help many sports-related studies gather vast amounts of data, such as Object Detection and Pose Estimation. We provide a use case for such data: building a model for shot speed estimation with pose data obtained using only Computer Vision models. Our model achieves a correlation of 67%. The possibility of estimating shot speeds enables much deeper studies about enabling the creation of new metrics and recommendation systems that will help athletes improve their performance, in any sport. The proposed methodology is easily replicable for many technical movements and is only limited by the availability of video data.
Valuing Players Over Time
Sep 08, 2022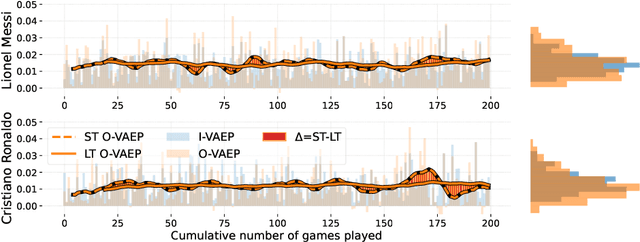
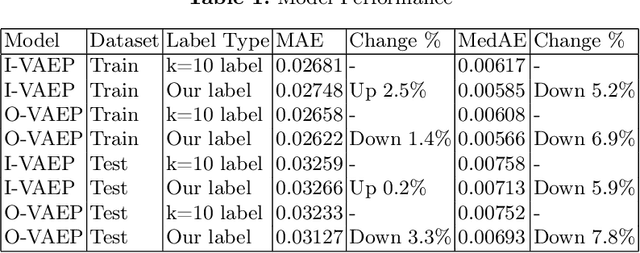
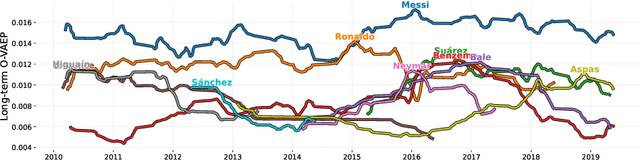
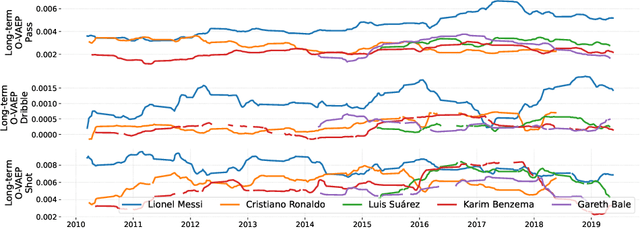
In soccer (or association football), players quickly go from heroes to zeroes, or vice-versa. Performance is not a static measure but a somewhat volatile one. Analyzing performance as a time series rather than a stationary point in time is crucial to making better decisions. This paper introduces and explores I-VAEP and O-VAEP models to evaluate actions and rate players' intention and execution. Then, we analyze these ratings over time and propose use cases to fundament our option of treating player ratings as a continuous problem. As a result, we present who were the best players and how their performance evolved, define volatility metrics to measure a player's consistency, and build a player development curve to assist decision-making.
Hierarchical Qualitative Clustering: clustering mixed datasets with critical qualitative information
Jul 06, 2020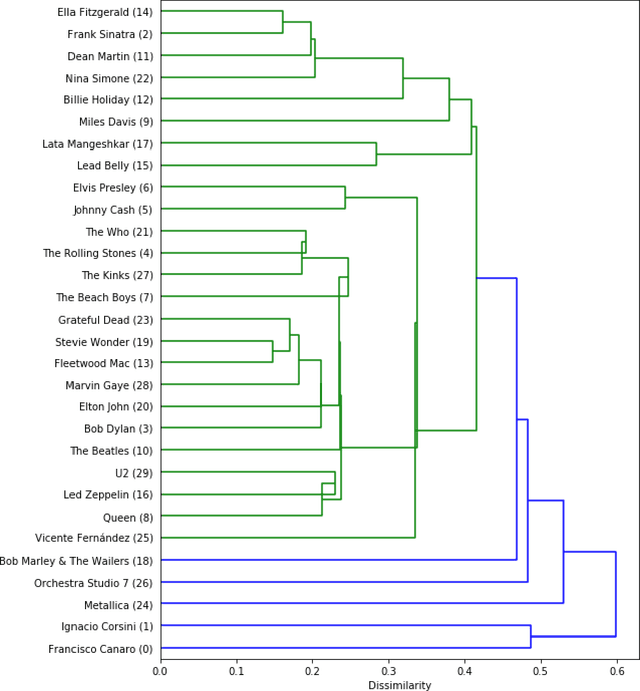
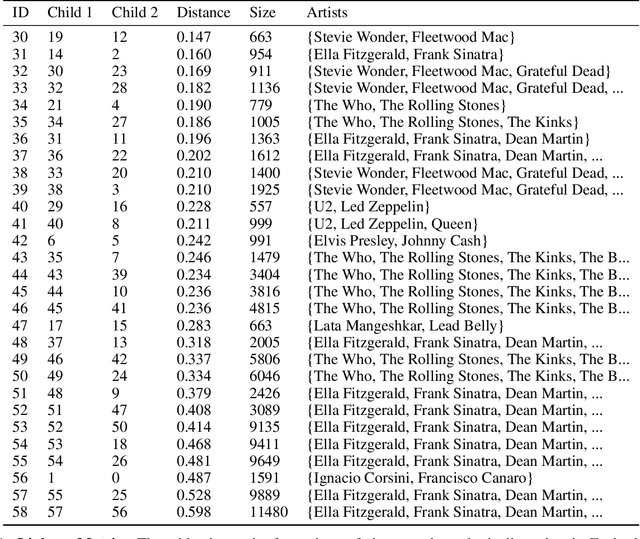
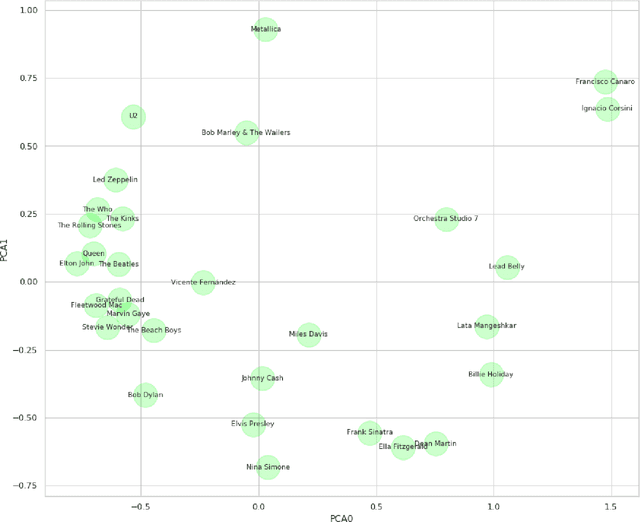
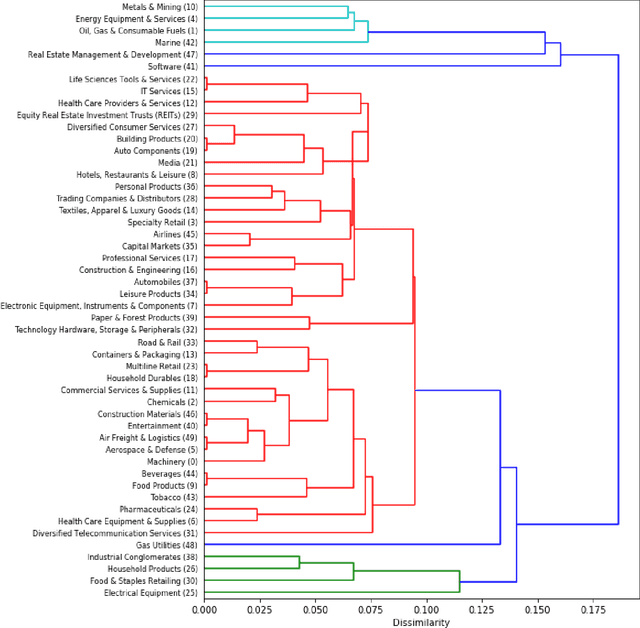
Clustering can be used to extract insights from data or to verify some of the assumptions held by the domain experts, namely data segmentation. In the literature, few methods can be applied in clustering qualitative values using the context associated with other variables present in the data, without losing interpretability. Moreover, the metrics for calculating dissimilarity between qualitative values often scale poorly for high dimensional mixed datasets. In this study, we propose a novel method for clustering qualitative values, based on Hierarchical Clustering (HQC), and using Maximum Mean Discrepancy. HQC maintains the original interpretability of the qualitative information present in the dataset. We apply HQC to two datasets. Using a mixed dataset provided by Spotify, we showcase how our method can be used for clustering music artists based on the quantitative features of thousands of songs. In addition, using financial features of companies, we cluster company industries, and discuss the implications in investment portfolios diversification.