 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Qualitative Clustering: clustering mixed datasets with critical qualitative information
Paper and Code
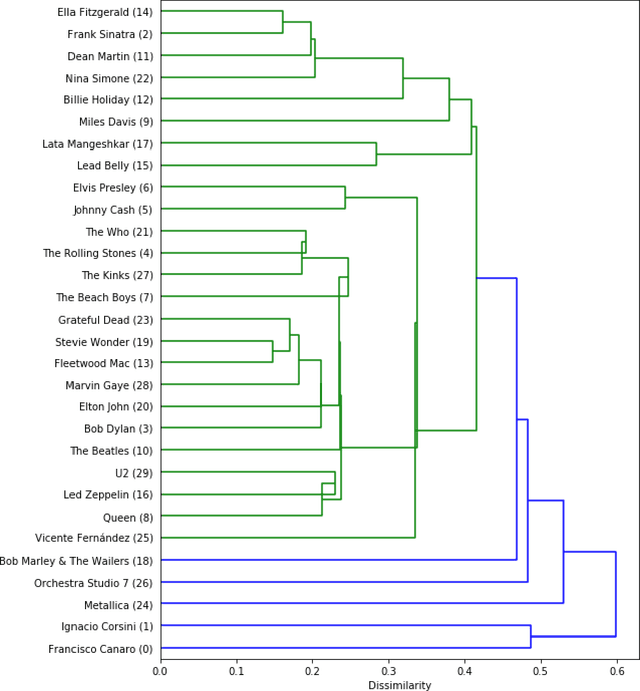
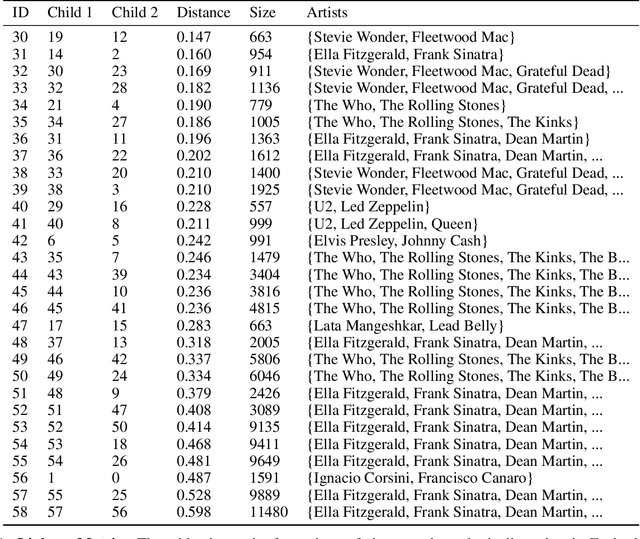
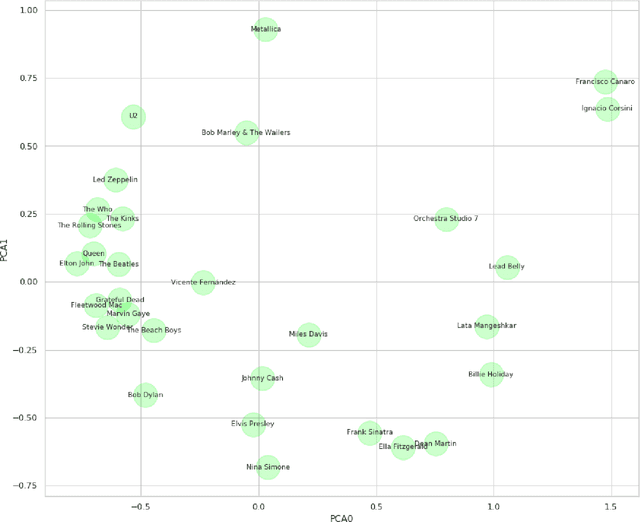
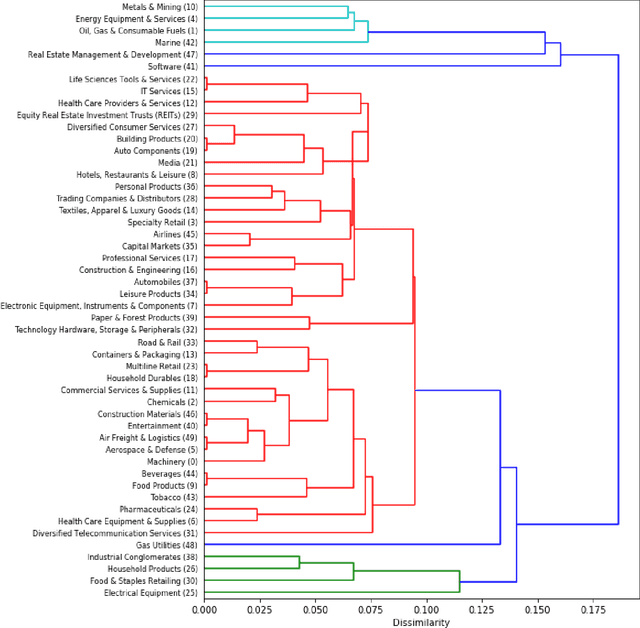
Clustering can be used to extract insights from data or to verify some of the assumptions held by the domain experts, namely data segmentation. In the literature, few methods can be applied in clustering qualitative values using the context associated with other variables present in the data, without losing interpretability. Moreover, the metrics for calculating dissimilarity between qualitative values often scale poorly for high dimensional mixed datasets. In this study, we propose a novel method for clustering qualitative values, based on Hierarchical Clustering (HQC), and using Maximum Mean Discrepancy. HQC maintains the original interpretability of the qualitative information present in the dataset. We apply HQC to two datasets. Using a mixed dataset provided by Spotify, we showcase how our method can be used for clustering music artists based on the quantitative features of thousands of songs. In addition, using financial features of companies, we cluster company industries, and discuss the implications in investment portfolios diversification.