 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstrumentation for Better Demonstrations: A Case Study
Apr 25, 2025Learning from demonstrations is a powerful paradigm for robot manipulation, but its effectiveness hinges on both the quantity and quality of the collected data. In this work, we present a case study of how instrumentation, i.e. integration of sensors, can improve the quality of demonstrations and automate data collection. We instrument a squeeze bottle with a pressure sensor to learn a liquid dispensing task, enabling automated data collection via a PI controller. Transformer-based policies trained on automated demonstrations outperform those trained on human data in 78% of cases. Our findings indicate that instrumentation not only facilitates scalable data collection but also leads to better-performing policies, highlighting its potential in the pursuit of generalist robotic agents.
Self-Mixing Laser Interferometry: In Search of an Ambient Noise-Resilient Alternative to Acoustic Sensing
Apr 18, 2025



Self-mixing interferometry (SMI) has been lauded for its sensitivity in detecting microvibrations, while requiring no physical contact with its target. Microvibrations, i.e., sounds, have recently been used as a salient indicator of extrinsic contact in robotic manipulation. In previous work, we presented a robotic fingertip using SMI for extrinsic contact sensing as an ambient-noise-resilient alternative to acoustic sensing. Here, we extend the validation experiments to the frequency domain. We find that for broadband ambient noise, SMI still outperforms acoustic sensing, but the difference is less pronounced than in time-domain analyses. For targeted noise disturbances, analogous to multiple robots simultaneously collecting data for the same task, SMI is still the clear winner. Lastly, we show how motor noise affects SMI sensing more so than acoustic sensing, and that a higher SMI readout frequency is important for future work. Design and data files are available at https://github.com/RemkoPr/icra2025-SMI-tactile-sensing.
Evaluating Text-to-Image Diffusion Models for Texturing Synthetic Data
Nov 15, 2024Building generic robotic manipulation systems often requires large amounts of real-world data, which can be dificult to collect. Synthetic data generation offers a promising alternative, but limiting the sim-to-real gap requires significant engineering efforts. To reduce this engineering effort, we investigate the use of pretrained text-to-image diffusion models for texturing synthetic images and compare this approach with using random textures, a common domain randomization technique in synthetic data generation. We focus on generating object-centric representations, such as keypoints and segmentation masks, which are important for robotic manipulation and require precise annotations. We evaluate the efficacy of the texturing methods by training models on the synthetic data and measuring their performance on real-world datasets for three object categories: shoes, T-shirts, and mugs. Surprisingly, we find that texturing using a diffusion model performs on par with random textures, despite generating seemingly more realistic images. Our results suggest that, for now, using diffusion models for texturing does not benefit synthetic data generation for robotics. The code, data and trained models are available at \url{https://github.com/tlpss/diffusing-synthetic-data.git}.
Learning Keypoints for Robotic Cloth Manipulation using Synthetic Data
Jan 03, 2024Assistive robots should be able to wash, fold or iron clothes. However, due to the variety, deformability and self-occlusions of clothes, creating general-purpose robot systems for cloth manipulation is challenging. Synthetic data is a promising direction to improve generalization, though its usability is often limited by the sim-to-real gap. To advance the use of synthetic data for cloth manipulation and to enable tasks such as robotic folding, we present a synthetic data pipeline to train keypoint detectors for almost flattened cloth items. To test its performance, we have also collected a real-world dataset. We train detectors for both T-shirts, towels and shorts and obtain an average precision of 64.3%. Fine-tuning on real-world data improves performance to 74.2%. Additional insight is provided by discussing various failure modes of the keypoint detectors and by comparing different approaches to obtain cloth meshes and materials. We also quantify the remaining sim-to-real gap and argue that further improvements to the fidelity of cloth assets will be required to further reduce this gap. The code, dataset and trained models are available online.
Revisiting Proprioceptive Sensing for Articulated Object Manipulation
May 16, 2023Robots that assist humans will need to interact with articulated objects such as cabinets or microwaves. Early work on creating systems for doing so used proprioceptive sensing to estimate joint mechanisms during contact. However, nowadays, almost all systems use only vision and no longer consider proprioceptive information during contact. We believe that proprioceptive information during contact is a valuable source of information and did not find clear motivation for not using it in the literature. Therefore, in this paper, we create a system that, starting from a given grasp, uses proprioceptive sensing to open cabinets with a position-controlled robot and a parallel gripper. We perform a qualitative evaluation of this system, where we find that slip between the gripper and handle limits the performance. Nonetheless, we find that the system already performs quite well. This poses the question: should we make more use of proprioceptive information during contact in articulated object manipulation systems, or is it not worth the added complexity, and can we manage with vision alone? We do not have an answer to this question, but we hope to spark some discussion on the matter. The codebase and videos of the system are available at https://tlpss.github.io/revisiting-proprioception-for-articulated-manipulation/.
Learning Keypoints from Synthetic Data for Robotic Cloth Folding
May 13, 2022
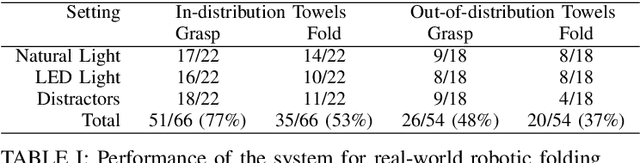
Robotic cloth manipulation is challenging due to its deformability, which makes determining its full state infeasible. However, for cloth folding, it suffices to know the position of a few semantic keypoints. Convolutional neural networks (CNN) can be used to detect these keypoints, but require large amounts of annotated data, which is expensive to collect. To overcome this, we propose to learn these keypoint detectors purely from synthetic data, enabling low-cost data collection. In this paper, we procedurally generate images of towels and use them to train a CNN. We evaluate the performance of this detector for folding towels on a unimanual robot setup and find that the grasp and fold success rates are 77% and 53%, respectively. We conclude that learning keypoint detectors from synthetic data for cloth folding and related tasks is a promising research direction, discuss some failures and relate them to future work. A video of the system, as well as the codebase, more details on the CNN architecture and the training setup can be found at https://github.com/tlpss/workshop-icra-2022-cloth-keypoints.git.