 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe experience of humans' and robots' mutual (im)politeness in enacted service scenarios: An empirical study
Jun 25, 2024
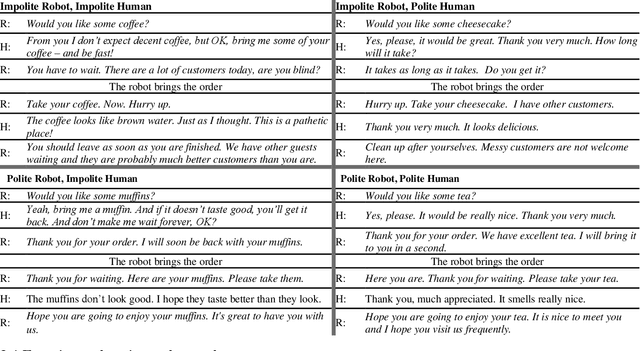
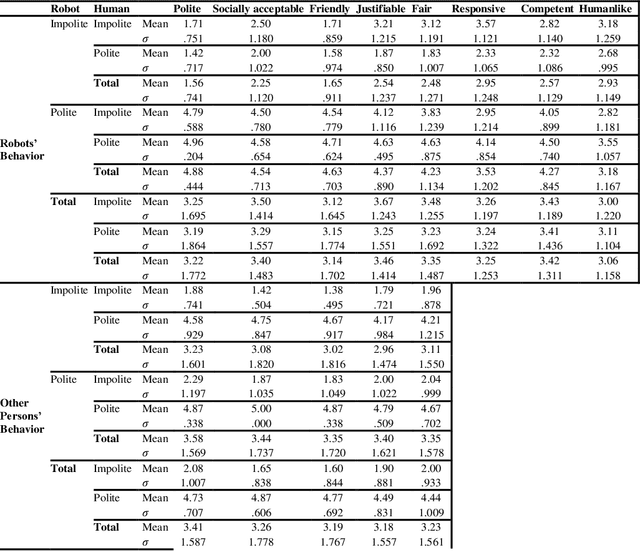
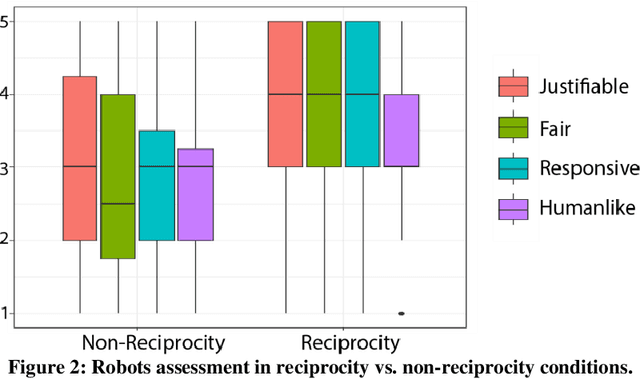
The paper reports an empirical study of the effect of human treatment of a robot on the social perception of the robot's behavior. The study employed an enacted interaction between an anthropomorphic "waiter" robot and two customers. The robot and one of the customers (acted out by a researcher) were following four different interaction scripts, representing all combinations of mutual politeness and impoliteness of the robot and the customer. The participants (N=24, within-subject design) were assigned the role of an "included observer", that is, a fellow customer who was present in the situation without being actively involved in the interactions. The participants assessed how they experienced the interaction scenarios by providing Likert scale scores and free-text responses. The results indicate that while impolite robots' behavior was generally assessed negatively, it was commonly perceived as more justifiable and fairer if the robot was treated impolitely by the human. Politeness reciprocity expectations in the context of the social perception of robots are discussed.
Policy Regularization for Legible Behavior
Mar 08, 2022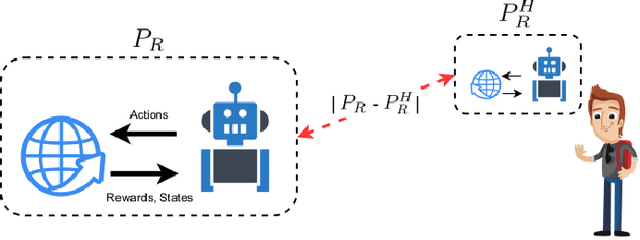
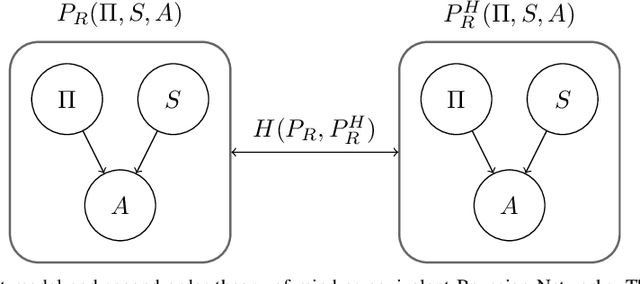
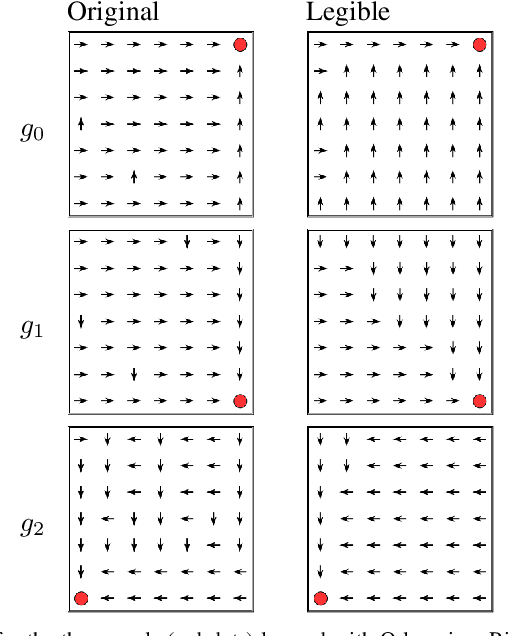
In Reinforcement Learning interpretability generally means to provide insight into the agent's mechanisms such that its decisions are understandable by an expert upon inspection. This definition, with the resulting methods from the literature, may however fall short for online settings where the fluency of interactions prohibits deep inspections of the decision-making algorithm. To support interpretability in online settings it is useful to borrow from the Explainable Planning literature methods that focus on the legibility of the agent, by making its intention easily discernable in an observer model. As we propose in this paper, injecting legible behavior inside an agent's policy doesn't require modify components of its learning algorithm. Rather, the agent's optimal policy can be regularized for legibility by evaluating how the policy may produce observations that would make an observer infer an incorrect policy. In our formulation, the decision boundary introduced by legibility impacts the states in which the agent's policy returns an action that has high likelihood also in other policies. In these cases, a trade-off between such action, and legible/sub-optimal action is made.
Conversational Norms for Human-Robot Dialogues
Mar 02, 2021This paper describes a recently initiated research project aiming at supporting development of computerised dialogue systems that handle breaches of conversational norms such as the Gricean maxims, which describe how dialogue participants ideally form their utterances in order to be informative, relevant, brief, etc. Our approach is to model dialogue and norms with co-operating distributed grammar systems (CDGSs), and to develop methods to detect breaches and to handle them in dialogue systems for verbal human-robot interaction.
Bias in Machine Learning What is it Good for?
Apr 01, 2020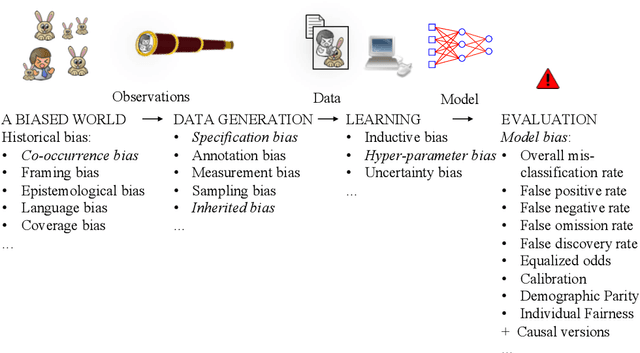
In public media as well as in scientific publications, the term \emph{bias} is used in conjunction with machine learning in many different contexts, and with many different meanings. This paper proposes a taxonomy of these different meanings, terminology, and definitions by surveying the, primarily scientific, literature on machine learning. In some cases, we suggest extensions and modifications to promote a clear terminology and completeness. The survey is followed by an analysis and discussion on how different types of biases are connected and depend on each other. We conclude that there is a complex relation between bias occurring in the machine learning pipeline that leads to a model, and the eventual bias of the model (which is typically related to social discrimination). The former bias may or may not influence the latter, in a sometimes bad, and sometime good way.