 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformative Communication of Robot Plans
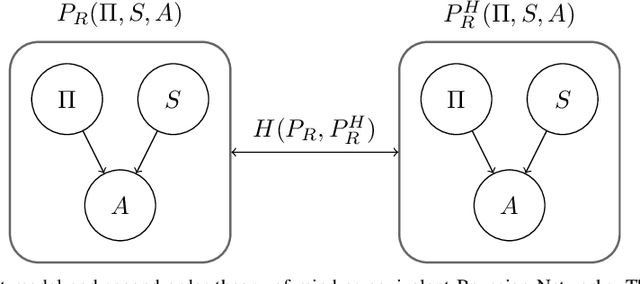
Nov 17, 2025When a robot is asked to verbalize its plan it can do it in many ways. For example, a seemingly natural strategy is incremental, where the robot verbalizes its planned actions in plan order. However, an important aspect of this type of strategy is that it misses considerations on what is effectively informative to communicate, because not considering what the user knows prior to explanations. In this paper we propose a verbalization strategy to communicate robot plans informatively, by measuring the information gain that verbalizations have against a second-order theory of mind of the user capturing his prior knowledge on the robot. As shown in our experiments, this strategy allows to understand the robot's goal much quicker than by using strategies such as increasing or decreasing plan order. In addition, following our formulation we hint to what is informative and why when a robot communicates its plan.
Policy Regularization for Legible Behavior
Mar 08, 2022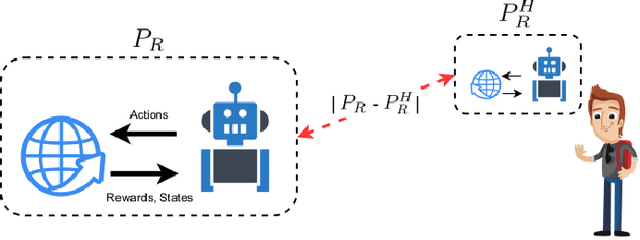
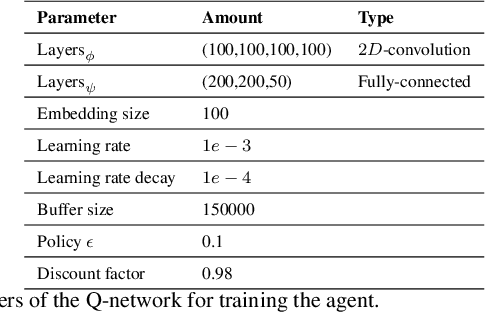
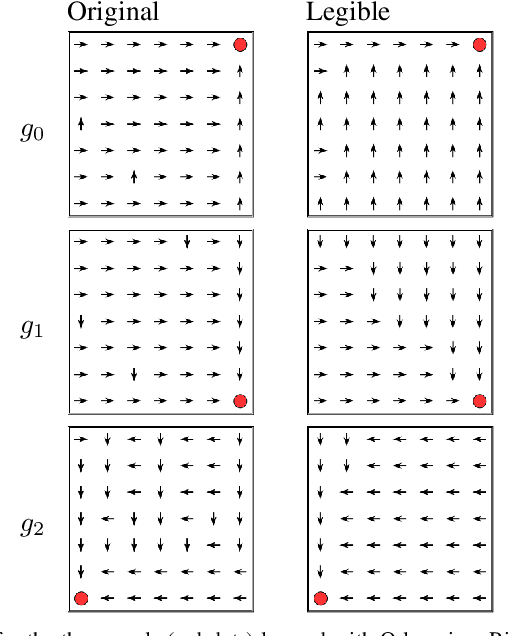
In Reinforcement Learning interpretability generally means to provide insight into the agent's mechanisms such that its decisions are understandable by an expert upon inspection. This definition, with the resulting methods from the literature, may however fall short for online settings where the fluency of interactions prohibits deep inspections of the decision-making algorithm. To support interpretability in online settings it is useful to borrow from the Explainable Planning literature methods that focus on the legibility of the agent, by making its intention easily discernable in an observer model. As we propose in this paper, injecting legible behavior inside an agent's policy doesn't require modify components of its learning algorithm. Rather, the agent's optimal policy can be regularized for legibility by evaluating how the policy may produce observations that would make an observer infer an incorrect policy. In our formulation, the decision boundary introduced by legibility impacts the states in which the agent's policy returns an action that has high likelihood also in other policies. In these cases, a trade-off between such action, and legible/sub-optimal action is made.