 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Unsupervised Domain Adaptation for Neural Networks via Moment Alignment
May 28, 2018



A novel approach for unsupervised domain adaptation for neural networks is proposed that relies on metric-based regularization of the learning process. The metric-based regularization aims at domain-invariant latent feature representations by means of maximizing the similarity between domain-specific activation distributions. The proposed metric results from modifying an integral probability metric such that it becomes translation-invariant on a polynomial function space. The metric has an intuitive interpretation in the dual space as the sum of differences of higher order central moments of the corresponding activation distributions. Error minimization guarantees are proven for the continuous case. As demonstrated by an analysis of standard benchmark experiments for sentiment analysis, object recognition and digit recognition, the outlined approach is robust regarding parameter changes and achieves higher classification accuracies than comparable approaches.
Central Moment Discrepancy (CMD) for Domain-Invariant Representation Learning
Jul 04, 2017
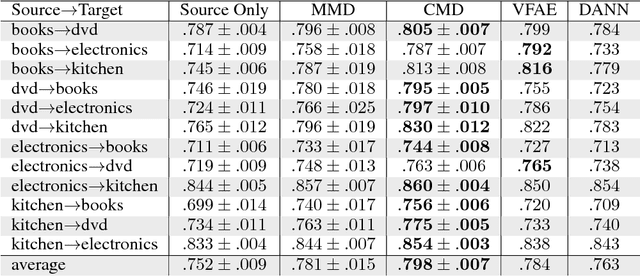
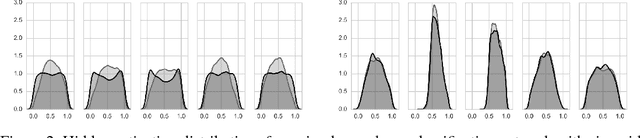
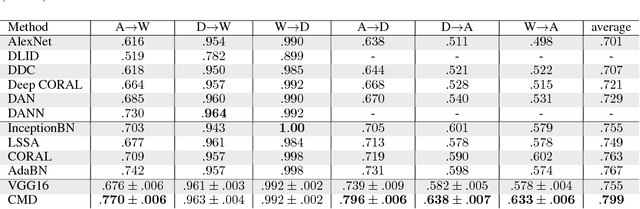
The learning of domain-invariant representations in the context of domain adaptation with neural networks is considered. We propose a new regularization method that minimizes the discrepancy between domain-specific latent feature representations directly in the hidden activation space. Although some standard distribution matching approaches exist that can be interpreted as the matching of weighted sums of moments, e.g. Maximum Mean Discrepancy (MMD), an explicit order-wise matching of higher order moments has not been considered before. We propose to match the higher order central moments of probability distributions by means of order-wise moment differences. Our model does not require computationally expensive distance and kernel matrix computations. We utilize the equivalent representation of probability distributions by moment sequences to define a new distance function, called Central Moment Discrepancy (CMD). We prove that CMD is a metric on the set of probability distributions on a compact interval. We further prove that convergence of probability distributions on compact intervals w.r.t. the new metric implies convergence in distribution of the respective random variables. We test our approach on two different benchmark data sets for object recognition (Office) and sentiment analysis of product reviews (Amazon reviews). CMD achieves a new state-of-the-art performance on most domain adaptation tasks of Office and outperforms networks trained with MMD, Variational Fair Autoencoders and Domain Adversarial Neural Networks on Amazon reviews. In addition, a post-hoc parameter sensitivity analysis shows that the new approach is stable w.r.t. parameter changes in a certain interval. The source code of the experiments is publicly available.
Generalized Online Transfer Learning for Climate Control in Residential Buildings
Oct 13, 2016
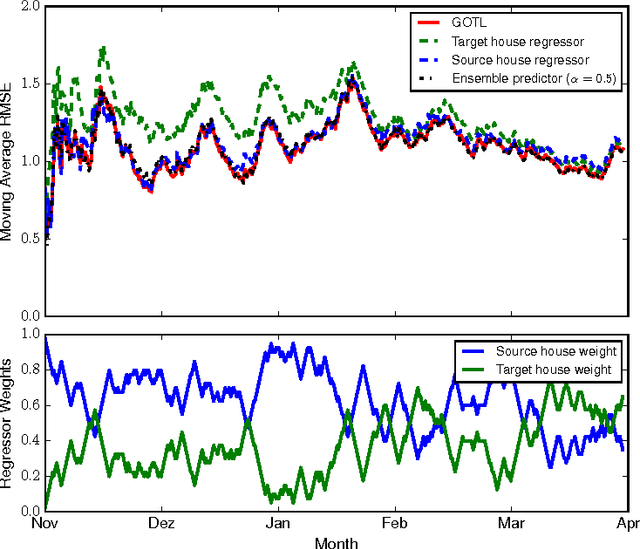

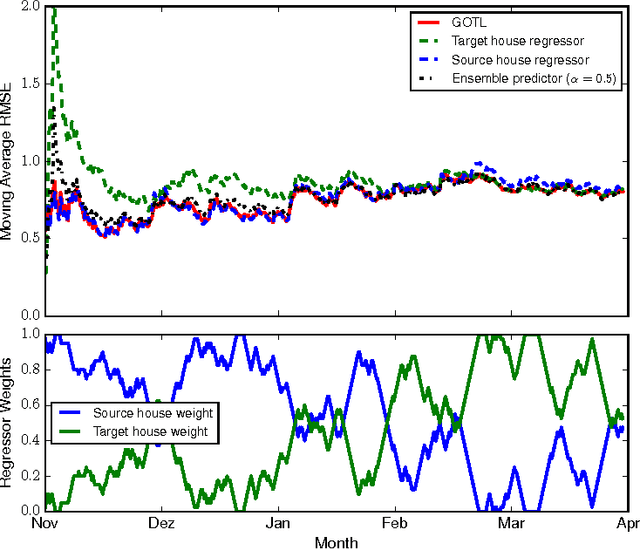
This paper presents an online transfer learning framework for improving temperature predictions in residential buildings. In transfer learning, prediction models trained under a set of available data from a target domain (e.g., house with limited data) can be improved through the use of data generated from similar source domains (e.g., houses with rich data). Given also the need for prediction models that can be trained online (e.g., as part of a model-predictive-control implementation), this paper introduces the generalized online transfer learning algorithm (GOTL). It employs a weighted combination of the available predictors (i.e., the target and source predictors) and guarantees convergence to the best weighted predictor. Furthermore, the use of Transfer Component Analysis (TCA) allows for using more than a single source domains, since it may facilitate the fit of a single model on more than one source domains (houses). This allows GOTL to transfer knowledge from more than one source domains. We further validate our results through experiments in climate control for residential buildings and show that GOTL may lead to non-negligible energy savings for given comfort levels.