 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentral Moment Discrepancy (CMD) for Domain-Invariant Representation Learning
Paper and Code
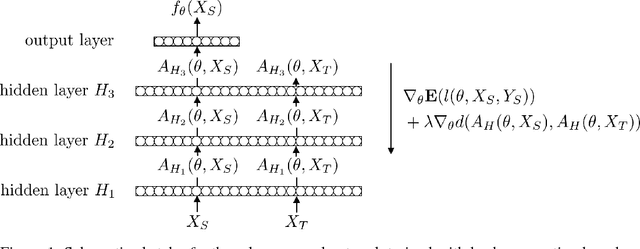
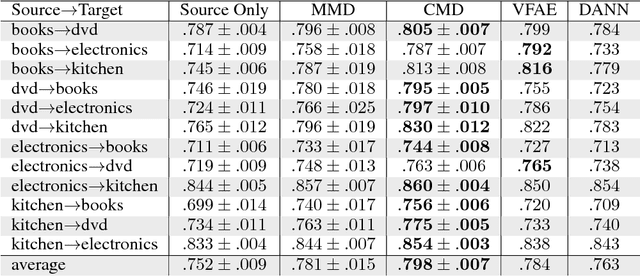
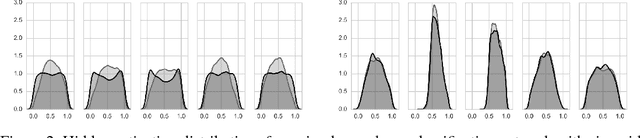
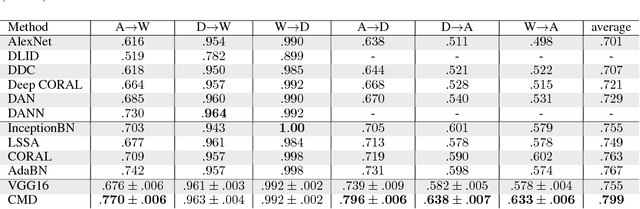
The learning of domain-invariant representations in the context of domain adaptation with neural networks is considered. We propose a new regularization method that minimizes the discrepancy between domain-specific latent feature representations directly in the hidden activation space. Although some standard distribution matching approaches exist that can be interpreted as the matching of weighted sums of moments, e.g. Maximum Mean Discrepancy (MMD), an explicit order-wise matching of higher order moments has not been considered before. We propose to match the higher order central moments of probability distributions by means of order-wise moment differences. Our model does not require computationally expensive distance and kernel matrix computations. We utilize the equivalent representation of probability distributions by moment sequences to define a new distance function, called Central Moment Discrepancy (CMD). We prove that CMD is a metric on the set of probability distributions on a compact interval. We further prove that convergence of probability distributions on compact intervals w.r.t. the new metric implies convergence in distribution of the respective random variables. We test our approach on two different benchmark data sets for object recognition (Office) and sentiment analysis of product reviews (Amazon reviews). CMD achieves a new state-of-the-art performance on most domain adaptation tasks of Office and outperforms networks trained with MMD, Variational Fair Autoencoders and Domain Adversarial Neural Networks on Amazon reviews. In addition, a post-hoc parameter sensitivity analysis shows that the new approach is stable w.r.t. parameter changes in a certain interval. The source code of the experiments is publicly available.