 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Bearing Anomaly Detection Based on Model-Agnostic Meta-Learning
Jul 28, 2020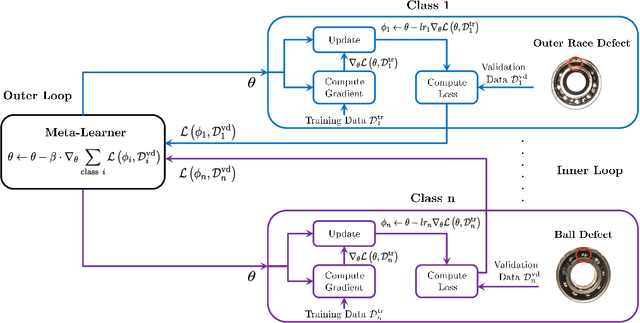
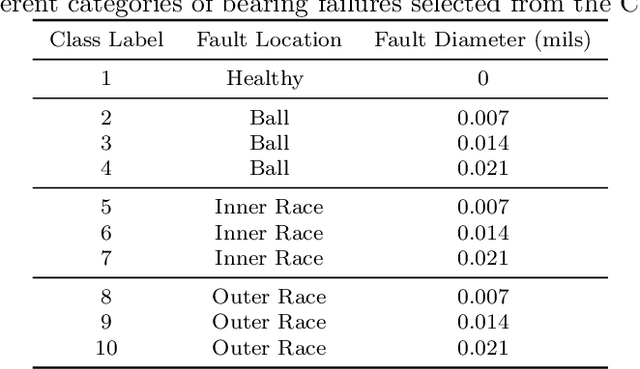

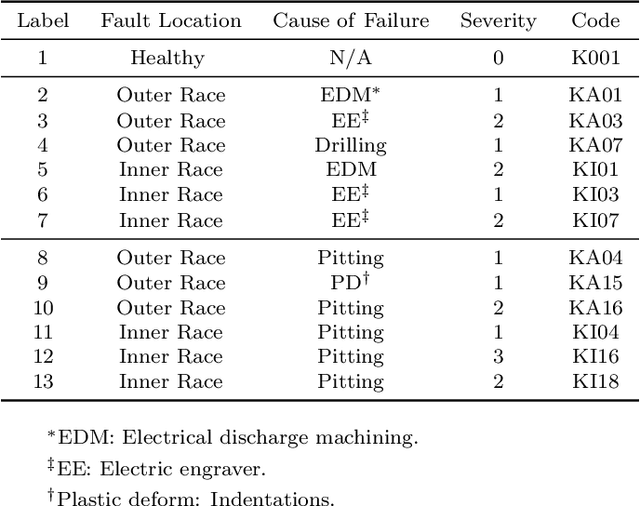
The rapid development of artificial intelligence and deep learning technology has provided many opportunities to further enhance the safety, stability, and accuracy of industrial Cyber-Physical Systems (CPS). As indispensable components to many mission-critical CPS assets and equipment, mechanical bearings need to be monitored to identify any trace of abnormal conditions. Most of the data-driven approaches applied to bearing anomaly detection up-to-date are trained using a large amount of fault data collected a priori. In many practical applications, however, it can be unsafe and time-consuming to collect sufficient data samples for each fault category, making it challenging to train a robust classifier. In this paper, we propose a few-shot learning approach for bearing anomaly detection based on model-agnostic meta-learning (MAML), which targets for training an effective fault classifier using limited data. In addition, it can leverage the training data and learn to identify new fault scenarios more efficiently. Case studies on the generalization to new artificial faults show that the proposed method achieves an overall accuracy up to 25% higher than a Siamese-network-based benchmark study. Finally, the robustness of the generalization capability of MAML is further validated by case studies of applying the algorithm to identify real bearing damages using data from artificial damages.
Semi-Supervised Learning of Bearing Anomaly Detection via Deep Variational Autoencoders
Dec 09, 2019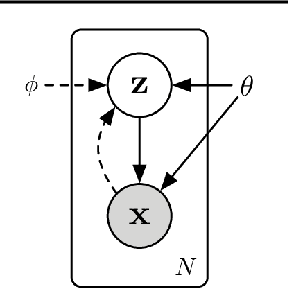
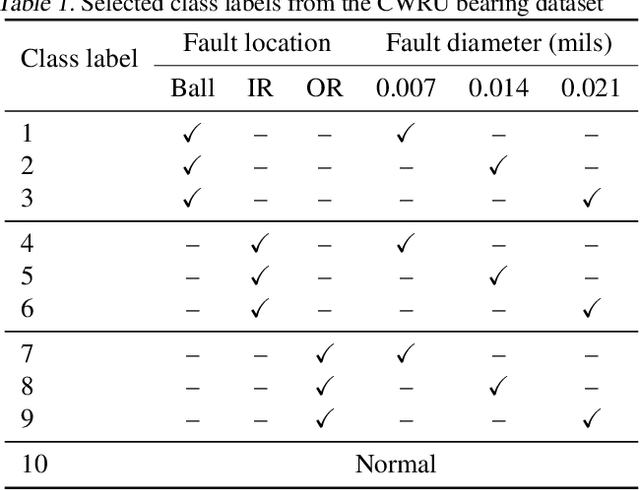
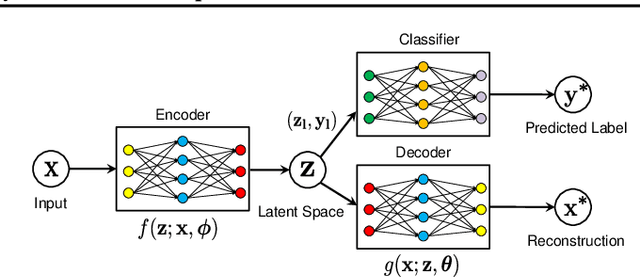
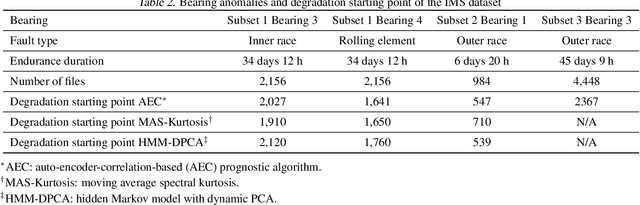
Most of the data-driven approaches applied to bearing fault diagnosis up to date are established in the supervised learning paradigm, which usually requires a large set of labeled data collected a priori. In practical applications, however, obtaining accurate labels based on real-time bearing conditions can be far more challenging than simply collecting a huge amount of unlabeled data using various sensors. In this paper, we thus propose a semi-supervised learning approach for bearing anomaly detection using variational autoencoder (VAE) based deep generative models, which allows for effective utilization of dataset when only a small subset of data have labels. Finally, a series of experiments is performed using both the Case Western Reserve University (CWRU) bearing dataset and the University of Cincinnati's Center for Intelligent Maintenance Systems (IMS) dataset. The experimental results demonstrate that the proposed semi-supervised learning scheme greatly outperforms two mainstream semi-supervised learning approaches and a baseline supervised convolutional neural network approach, with the overall accuracy improvement ranging between 3% to 30% using different proportions of labeled samples.
Visualization of Multi-Objective Switched Reluctance Machine Optimization at Multiple Operating Conditions with t-SNE
Nov 04, 2019
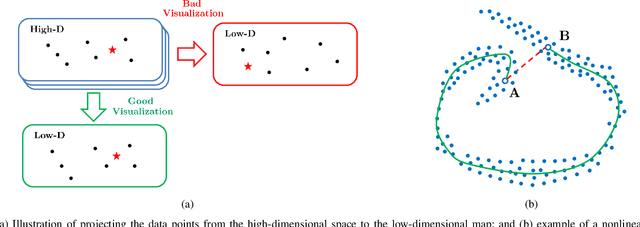
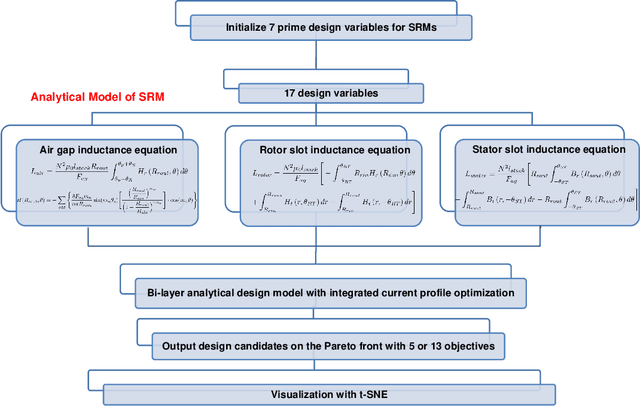
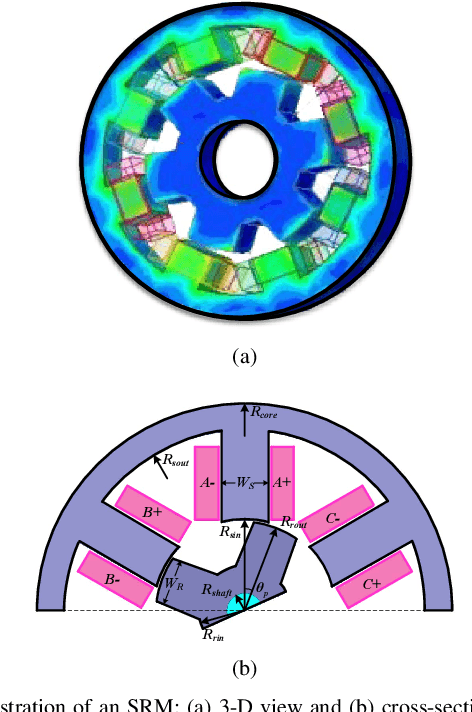
The optimization of electric machines at multiple operating points is crucial for applications that require frequent changes on speeds and loads, such as the electric vehicles, to strive for the machine optimal performance across the entire driving cycle. However, the number of objectives that would need to be optimized would significantly increase with the number of operating points considered in the optimization, thus posting a potential problem in regards to the visualization techniques currently in use, such as in the scatter plots of Pareto fronts, the parallel coordinates, and in the principal component analysis (PCA), inhibiting their ability to provide machine designers with intuitive and informative visualizations of all of the design candidates and their ability to pick a few for further fine-tuning with performance verification. Therefore, this paper proposes the utilization of t-distributed stochastic neighbor embedding (t-SNE) to visualize all of the optimization objectives of various electric machines design candidates with various operating conditions, which constitute a high-dimensional set of data that would lie on several different, but related, low-dimensional manifolds. Finally, two case studies of switched reluctance machines (SRM) are presented to illustrate the superiority of then t-SNE when compared to traditional visualization techniques used in electric machine optimizations.
Machine Learning and Deep Learning Algorithms for Bearing Fault Diagnostics - A Comprehensive Review
Jan 24, 2019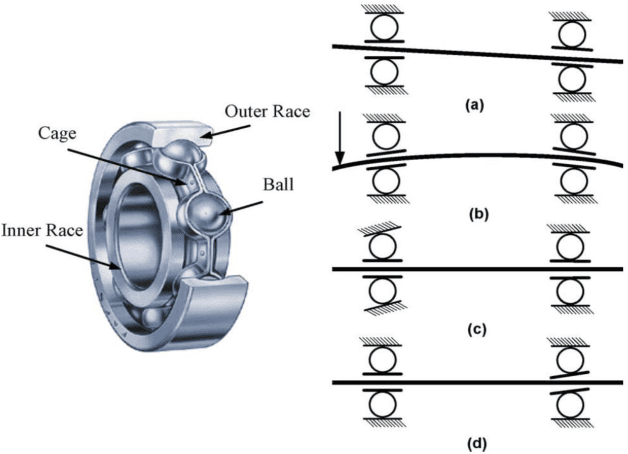
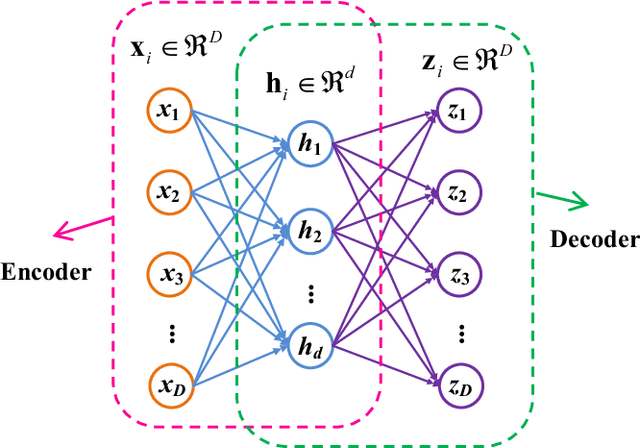
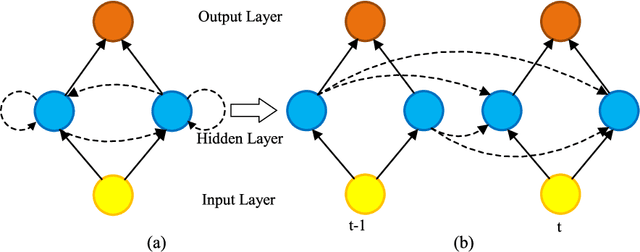
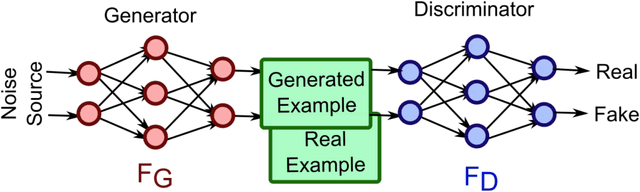
In this survey paper, we systematically summarize the current literature on studies that apply machine learning (ML) and data mining techniques to bearing fault diagnostics. Conventional ML methods, including artificial neural network (ANN), principal component analysis (PCA), support vector machines (SVM), etc., have been successfully applied to detecting and categorizing bearing faults since the last decade, while the application of deep learning (DL) methods has sparked great interest in both the industry and academia in the last five years. In this paper, we will first review the conventional ML methods, before taking a deep dive into the latest developments in DL algorithms for bearing fault applications. Specifically, the superiority of the DL based methods over the conventional ML methods are analyzed in terms of metrics directly related to fault feature extraction and classifier performances; the new functionalities offered by DL techniques that cannot be accomplished before are also summarized. In addition, to obtain a more intuitive insight, a comparative study is performed on the classifier performance and accuracy for a number of papers utilizing the open source Case Western Reserve University (CWRU) bearing data set. Finally, based on the nature of the time-series 1-D data obtained from sensors monitoring the bearing conditions, recommendations and suggestions are provided to applying DL algorithms on bearing fault diagnostics based on specific applications, as well as future research directions to further improve its performance.