 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFavour: FAst Variance Operator for Uncertainty Rating
Nov 21, 2023Bayesian Neural Networks (BNN) have emerged as a crucial approach for interpreting ML predictions. By sampling from the posterior distribution, data scientists may estimate the uncertainty of an inference. Unfortunately many inference samples are often needed, the overhead of which greatly hinder BNN's wide adoption. To mitigate this, previous work proposed propagating the first and second moments of the posterior directly through the network. However, on its own this method is even slower than sampling, so the propagated variance needs to be approximated such as assuming independence between neural nodes. The resulting trade-off between quality and inference time did not match even plain Monte Carlo sampling. Our contribution is a more principled variance propagation framework based on "spiked covariance matrices", which smoothly interpolates between quality and inference time. This is made possible by a new fast algorithm for updating a diagonal-plus-low-rank matrix approximation under various operations. We tested our algorithm against sampling based MC Dropout and Variational Inference on a number of downstream uncertainty themed tasks, such as calibration and out-of-distribution testing. We find that Favour is as fast as performing 2-3 inference samples, while matching the performance of 10-100 samples. In summary, this work enables the use of BNN in the realm of performance critical tasks where they have previously been out of reach.
Almost Optimal Tensor Sketch
Sep 03, 2019

We construct a matrix $M\in R^{m\otimes d^c}$ with just $m=O(c\,\lambda\,\varepsilon^{-2}\text{poly}\log1/\varepsilon\delta)$ rows, which preserves the norm $\|Mx\|_2=(1\pm\varepsilon)\|x\|_2$ of all $x$ in any given $\lambda$ dimensional subspace of $ R^d$ with probability at least $1-\delta$. This matrix can be applied to tensors $x^{(1)}\otimes\dots\otimes x^{(c)}\in R^{d^c}$ in $O(c\, m \min\{d,m\})$ time -- hence the name "Tensor Sketch". (Here $x\otimes y = \text{asvec}(xy^T) = [x_1y_1, x_1y_2,\dots,x_1y_m,x_2y_1,\dots,x_ny_m]\in R^{nm}$.) This improves upon earlier Tensor Sketch constructions by Pagh and Pham~[TOCT 2013, SIGKDD 2013] and Avron et al.~[NIPS 2014] which require $m=\Omega(3^c\lambda^2\delta^{-1})$ rows for the same guarantees. The factors of $\lambda$, $\varepsilon^{-2}$ and $\log1/\delta$ can all be shown to be necessary making our sketch optimal up to log factors. With another construction we get $\lambda$ times more rows $m=\tilde O(c\,\lambda^2\,\varepsilon^{-2}(\log1/\delta)^3)$, but the matrix can be applied to any vector $x^{(1)}\otimes\dots\otimes x^{(c)}\in R^{d^c}$ in just $\tilde O(c\, (d+m))$ time. This matches the application time of Tensor Sketch while still improving the exponential dependencies in $c$ and $\log1/\delta$. Technically, we show two main lemmas: (1) For many Johnson Lindenstrauss (JL) constructions, if $Q,Q'\in R^{m\times d}$ are independent JL matrices, the element-wise product $Qx \circ Q'y$ equals $M(x\otimes y)$ for some $M\in R^{m\times d^2}$ which is itself a JL matrix. (2) If $M^{(i)}\in R^{m\times md}$ are independent JL matrices, then $M^{(1)}(x \otimes (M^{(2)}y \otimes \dots)) = M(x\otimes y\otimes \dots)$ for some $M\in R^{m\times d^c}$ which is itself a JL matrix. Combining these two results give an efficient sketch for tensors of any size.
On the Complexity of Inner Product Similarity Join
Apr 07, 2016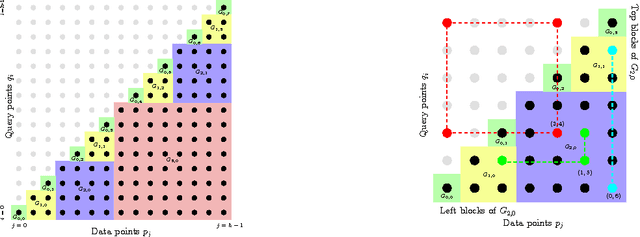
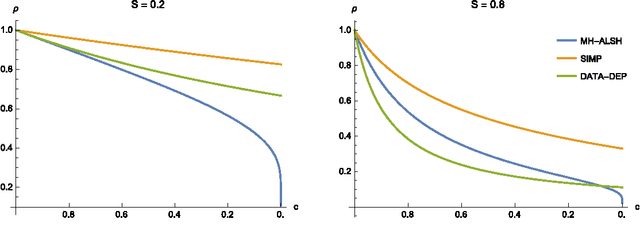
A number of tasks in classification, information retrieval, recommendation systems, and record linkage reduce to the core problem of inner product similarity join (IPS join): identifying pairs of vectors in a collection that have a sufficiently large inner product. IPS join is well understood when vectors are normalized and some approximation of inner products is allowed. However, the general case where vectors may have any length appears much more challenging. Recently, new upper bounds based on asymmetric locality-sensitive hashing (ALSH) and asymmetric embeddings have emerged, but little has been known on the lower bound side. In this paper we initiate a systematic study of inner product similarity join, showing new lower and upper bounds. Our main results are: * Approximation hardness of IPS join in subquadratic time, assuming the strong exponential time hypothesis. * New upper and lower bounds for (A)LSH-based algorithms. In particular, we show that asymmetry can be avoided by relaxing the LSH definition to only consider the collision probability of distinct elements. * A new indexing method for IPS based on linear sketches, implying that our hardness results are not far from being tight. Our technical contributions include new asymmetric embeddings that may be of independent interest. At the conceptual level we strive to provide greater clarity, for example by distinguishing among signed and unsigned variants of IPS join and shedding new light on the effect of asymmetry.