 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic uncertainty analysis of gravity gradient tensor components and their combinations
May 18, 2022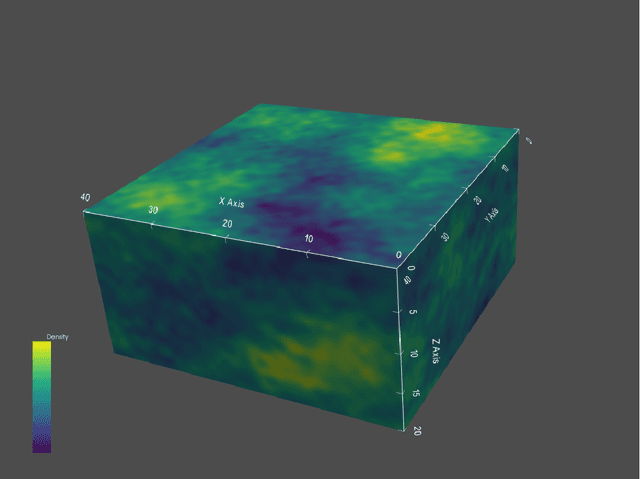


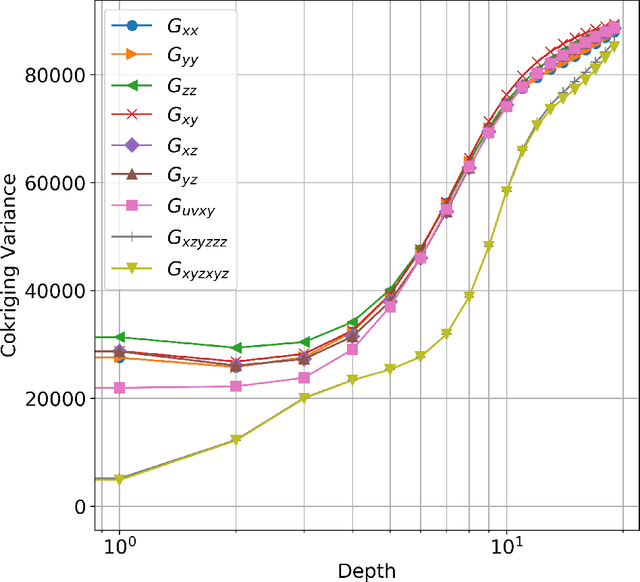
Full tensor gravity (FTG) devices provide up to five independent components of the gravity gradient tensor. However, we do not yet have a quantitative understanding of which tensor components or combinations of components are more important to recover a subsurface density model by gravity inversion. This is mainly because different components may be more appropriate in different scenarios or purposes. Knowledge of these components in different environments can aid with selection of optimal selection of component combinations. In this work, we propose to apply stochastic inversion to assess the uncertainty of gravity gradient tensor components and their combinations. The method is therefore a quantitative approach. The applied method here is based on the geostatistical inversion (Gaussian process regression) concept using cokriging. The cokriging variances (variance function of the GP) are found to be a useful indicator for distinguishing the gravity gradient tensor components. This approach is applied to the New Found dataset to demonstrate its effectiveness in real-world applications.
FluentNet: End-to-End Detection of Speech Disfluency with Deep Learning
Sep 23, 2020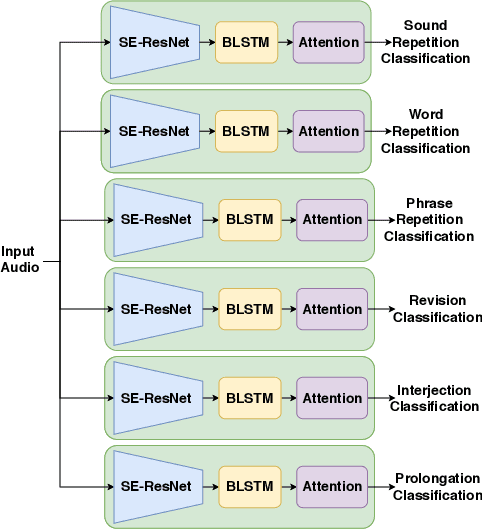
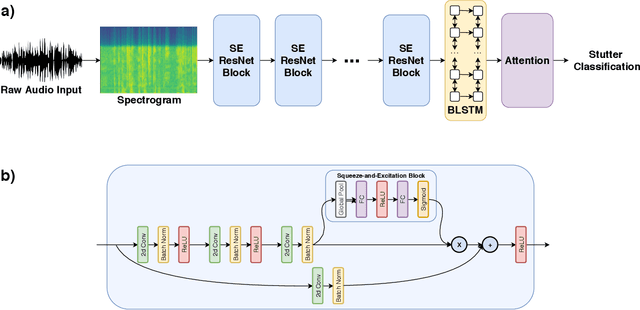
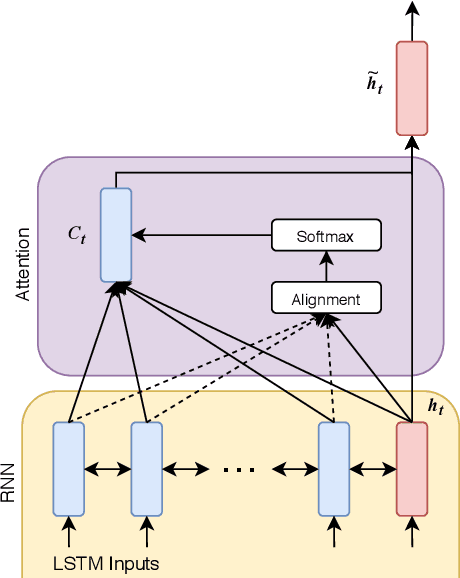
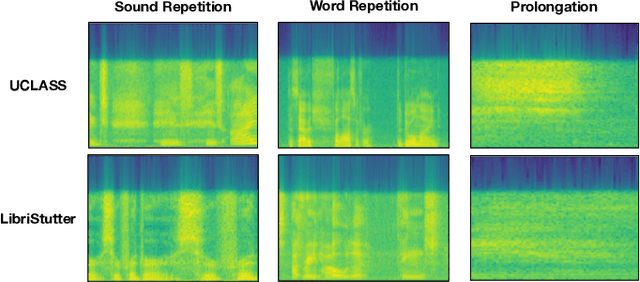
Strong presentation skills are valuable and sought-after in workplace and classroom environments alike. Of the possible improvements to vocal presentations, disfluencies and stutters in particular remain one of the most common and prominent factors of someone's demonstration. Millions of people are affected by stuttering and other speech disfluencies, with the majority of the world having experienced mild stutters while communicating under stressful conditions. While there has been much research in the field of automatic speech recognition and language models, there lacks the sufficient body of work when it comes to disfluency detection and recognition. To this end, we propose an end-to-end deep neural network, FluentNet, capable of detecting a number of different disfluency types. FluentNet consists of a Squeeze-and-Excitation Residual convolutional neural network which facilitate the learning of strong spectral frame-level representations, followed by a set of bidirectional long short-term memory layers that aid in learning effective temporal relationships. Lastly, FluentNet uses an attention mechanism to focus on the important parts of speech to obtain a better performance. We perform a number of different experiments, comparisons, and ablation studies to evaluate our model. Our model achieves state-of-the-art results by outperforming other solutions in the field on the publicly available UCLASS dataset. Additionally, we present LibriStutter: a disfluency dataset based on the public LibriSpeech dataset with synthesized stutters. We also evaluate FluentNet on this dataset, showing the strong performance of our model versus a number of benchmark techniques.
Detecting Multiple Speech Disfluencies using a Deep Residual Network with Bidirectional Long Short-Term Memory
Oct 17, 2019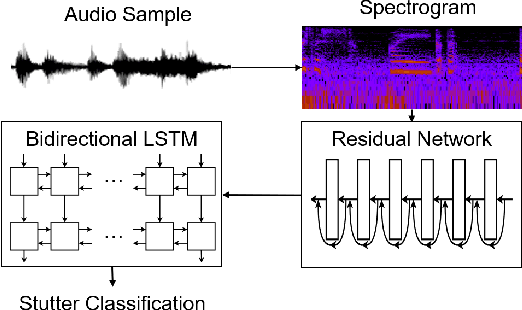
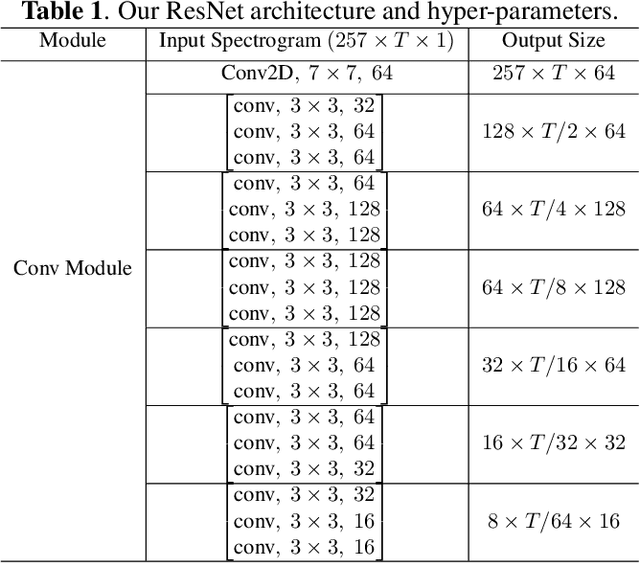


Stuttering is a speech impediment affecting tens of millions of people on an everyday basis. Even with its commonality, there is minimal data and research on the identification and classification of stuttered speech. This paper tackles the problem of detection and classification of different forms of stutter. As opposed to most existing works that identify stutters with language models, our work proposes a model that relies solely on acoustic features, allowing for identification of several variations of stutter disfluencies without the need for speech recognition. Our model uses a deep residual network and bidirectional long short-term memory layers to classify different types of stutters and achieves an average miss rate of 10.03%, outperforming the state-of-the-art by almost 27%