 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluentNet: End-to-End Detection of Speech Disfluency with Deep Learning
Paper and Code
Sep 23, 2020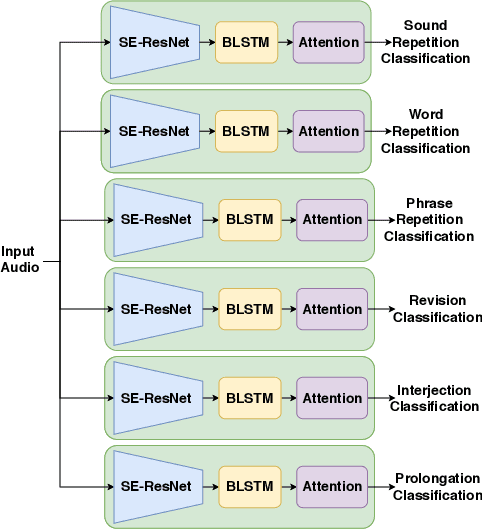
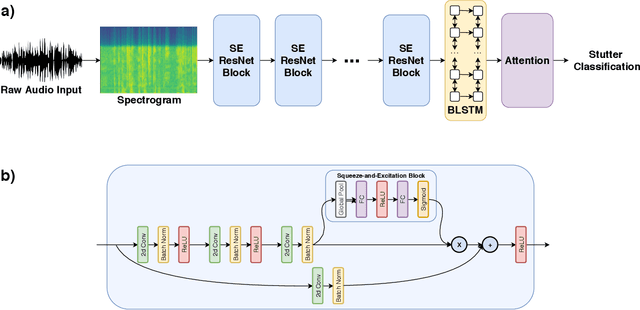
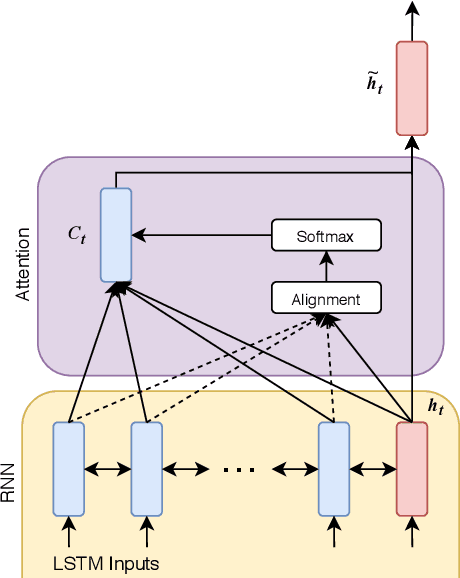
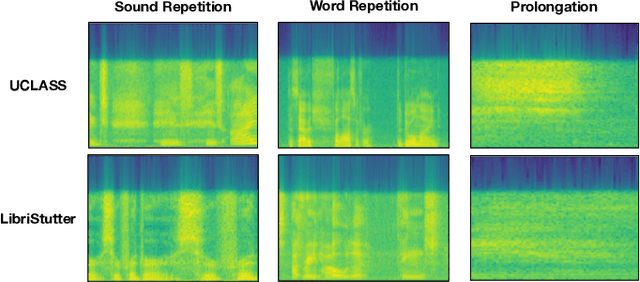
Strong presentation skills are valuable and sought-after in workplace and classroom environments alike. Of the possible improvements to vocal presentations, disfluencies and stutters in particular remain one of the most common and prominent factors of someone's demonstration. Millions of people are affected by stuttering and other speech disfluencies, with the majority of the world having experienced mild stutters while communicating under stressful conditions. While there has been much research in the field of automatic speech recognition and language models, there lacks the sufficient body of work when it comes to disfluency detection and recognition. To this end, we propose an end-to-end deep neural network, FluentNet, capable of detecting a number of different disfluency types. FluentNet consists of a Squeeze-and-Excitation Residual convolutional neural network which facilitate the learning of strong spectral frame-level representations, followed by a set of bidirectional long short-term memory layers that aid in learning effective temporal relationships. Lastly, FluentNet uses an attention mechanism to focus on the important parts of speech to obtain a better performance. We perform a number of different experiments, comparisons, and ablation studies to evaluate our model. Our model achieves state-of-the-art results by outperforming other solutions in the field on the publicly available UCLASS dataset. Additionally, we present LibriStutter: a disfluency dataset based on the public LibriSpeech dataset with synthesized stutters. We also evaluate FluentNet on this dataset, showing the strong performance of our model versus a number of benchmark techniques.