 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Multiple Speech Disfluencies using a Deep Residual Network with Bidirectional Long Short-Term Memory
Paper and Code
Oct 17, 2019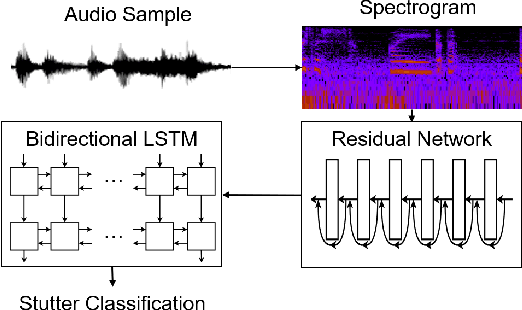
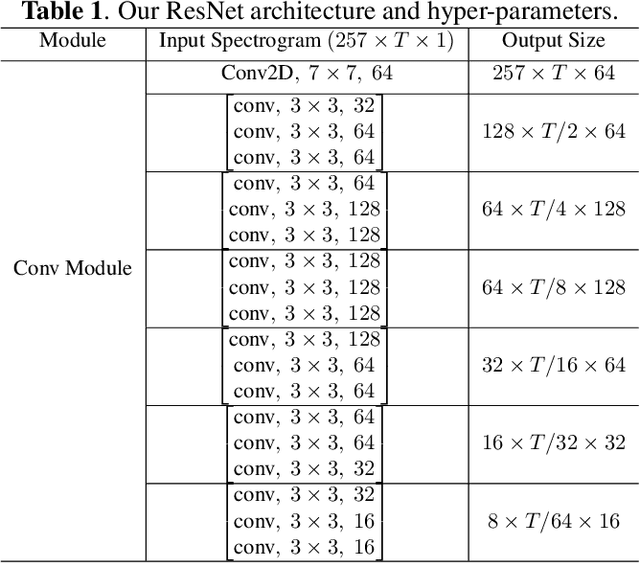


Stuttering is a speech impediment affecting tens of millions of people on an everyday basis. Even with its commonality, there is minimal data and research on the identification and classification of stuttered speech. This paper tackles the problem of detection and classification of different forms of stutter. As opposed to most existing works that identify stutters with language models, our work proposes a model that relies solely on acoustic features, allowing for identification of several variations of stutter disfluencies without the need for speech recognition. Our model uses a deep residual network and bidirectional long short-term memory layers to classify different types of stutters and achieves an average miss rate of 10.03%, outperforming the state-of-the-art by almost 27%