 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair and Diverse DPP-based Data Summarization
Feb 12, 2018



Sampling methods that choose a subset of the data proportional to its diversity in the feature space are popular for data summarization. However, recent studies have noted the occurrence of bias (under- or over-representation of a certain gender or race) in such data summarization methods. In this paper we initiate a study of the problem of outputting a diverse and fair summary of a given dataset. We work with a well-studied determinantal measure of diversity and corresponding distributions (DPPs) and present a framework that allows us to incorporate a general class of fairness constraints into such distributions. Coming up with efficient algorithms to sample from these constrained determinantal distributions, however, suffers from a complexity barrier and we present a fast sampler that is provably good when the input vectors satisfy a natural property. Our experimental results on a real-world and an image dataset show that the diversity of the samples produced by adding fairness constraints is not too far from the unconstrained case, and we also provide a theoretical explanation of it.
On the Complexity of Constrained Determinantal Point Processes
Apr 24, 2017Determinantal Point Processes (DPPs) are probabilistic models that arise in quantum physics and random matrix theory and have recently found numerous applications in computer science. DPPs define distributions over subsets of a given ground set, they exhibit interesting properties such as negative correlation, and, unlike other models, have efficient algorithms for sampling. When applied to kernel methods in machine learning, DPPs favor subsets of the given data with more diverse features. However, many real-world applications require efficient algorithms to sample from DPPs with additional constraints on the subset, e.g., partition or matroid constraints that are important to ensure priors, resource or fairness constraints on the sampled subset. Whether one can efficiently sample from DPPs in such constrained settings is an important problem that was first raised in a survey of DPPs by \cite{KuleszaTaskar12} and studied in some recent works in the machine learning literature. The main contribution of our paper is the first resolution of the complexity of sampling from DPPs with constraints. We give exact efficient algorithms for sampling from constrained DPPs when their description is in unary. Furthermore, we prove that when the constraints are specified in binary, this problem is #P-hard via a reduction from the problem of computing mixed discriminants implying that it may be unlikely that there is an FPRAS. Our results benefit from viewing the constrained sampling problem via the lens of polynomials. Consequently, we obtain a few algorithms of independent interest: 1) to count over the base polytope of regular matroids when there are additional (succinct) budget constraints and, 2) to evaluate and compute the mixed characteristic polynomials, that played a central role in the resolution of the Kadison-Singer problem, for certain special cases.
Batched Gaussian Process Bandit Optimization via Determinantal Point Processes
Nov 13, 2016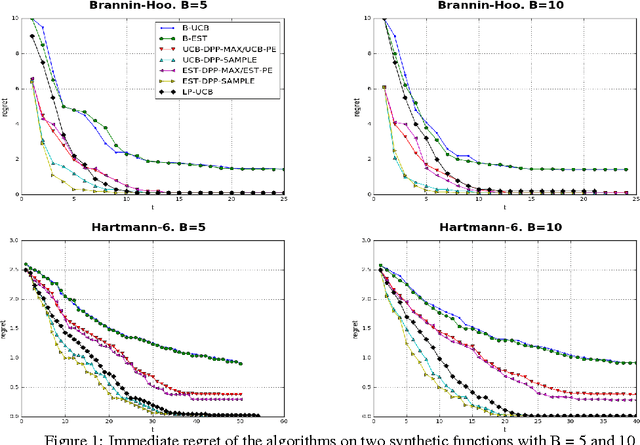

Gaussian Process bandit optimization has emerged as a powerful tool for optimizing noisy black box functions. One example in machine learning is hyper-parameter optimization where each evaluation of the target function requires training a model which may involve days or even weeks of computation. Most methods for this so-called "Bayesian optimization" only allow sequential exploration of the parameter space. However, it is often desirable to propose batches or sets of parameter values to explore simultaneously, especially when there are large parallel processing facilities at our disposal. Batch methods require modeling the interaction between the different evaluations in the batch, which can be expensive in complex scenarios. In this paper, we propose a new approach for parallelizing Bayesian optimization by modeling the diversity of a batch via Determinantal point processes (DPPs) whose kernels are learned automatically. This allows us to generalize a previous result as well as prove better regret bounds based on DPP sampling. Our experiments on a variety of synthetic and real-world robotics and hyper-parameter optimization tasks indicate that our DPP-based methods, especially those based on DPP sampling, outperform state-of-the-art methods.
How to be Fair and Diverse?
Oct 23, 2016

Due to the recent cases of algorithmic bias in data-driven decision-making, machine learning methods are being put under the microscope in order to understand the root cause of these biases and how to correct them. Here, we consider a basic algorithmic task that is central in machine learning: subsampling from a large data set. Subsamples are used both as an end-goal in data summarization (where fairness could either be a legal, political or moral requirement) and to train algorithms (where biases in the samples are often a source of bias in the resulting model). Consequently, there is a growing effort to modify either the subsampling methods or the algorithms themselves in order to ensure fairness. However, in doing so, a question that seems to be overlooked is whether it is possible to produce fair subsamples that are also adequately representative of the feature space of the data set - an important and classic requirement in machine learning. Can diversity and fairness be simultaneously ensured? We start by noting that, in some applications, guaranteeing one does not necessarily guarantee the other, and a new approach is required. Subsequently, we present an algorithmic framework which allows us to produce both fair and diverse samples. Our experimental results on an image summarization task show marked improvements in fairness without compromising feature diversity by much, giving us the best of both the worlds.
On Sampling and Greedy MAP Inference of Constrained Determinantal Point Processes
Jul 06, 2016


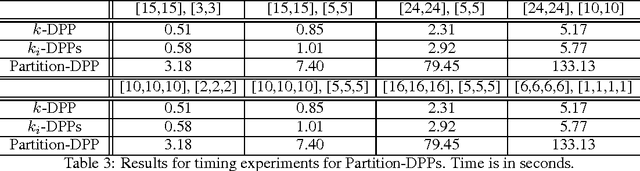
Subset selection problems ask for a small, diverse yet representative subset of the given data. When pairwise similarities are captured by a kernel, the determinants of submatrices provide a measure of diversity or independence of items within a subset. Matroid theory gives another notion of independence, thus giving rise to optimization and sampling questions about Determinantal Point Processes (DPPs) under matroid constraints. Partition constraints, as a special case, arise naturally when incorporating additional labeling or clustering information, besides the kernel, in DPPs. Finding the maximum determinant submatrix under matroid constraints on its row/column indices has been previously studied. However, the corresponding question of sampling from DPPs under matroid constraints has been unresolved, beyond the simple cardinality constrained k-DPPs. We give the first polynomial time algorithm to sample exactly from DPPs under partition constraints, for any constant number of partitions. We complement this by a complexity theoretic barrier that rules out such a result under general matroid constraints. Our experiments indicate that partition-constrained DPPs offer more flexibility and more diversity than k-DPPs and their naive extensions, while being reasonably efficient in running time. We also show that a simple greedy initialization followed by local search gives improved approximation guarantees for the problem of MAP inference from k- DPPs on well-conditioned kernels. Our experiments show that this improvement is significant for larger values of k, supporting our theoretical result.