 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Feature Elimination for the LASSO and Sparse Supervised Learning Problems
May 18, 2011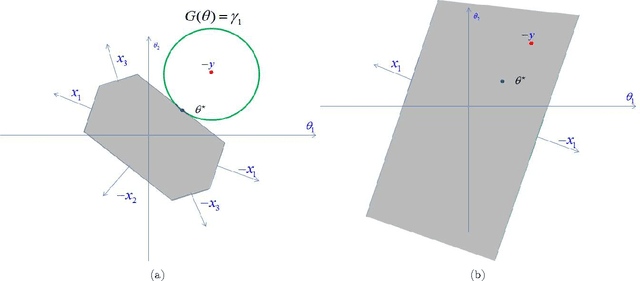
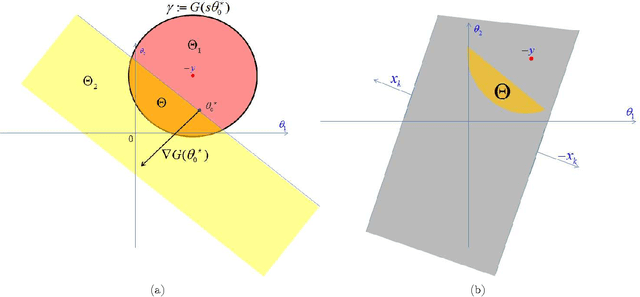
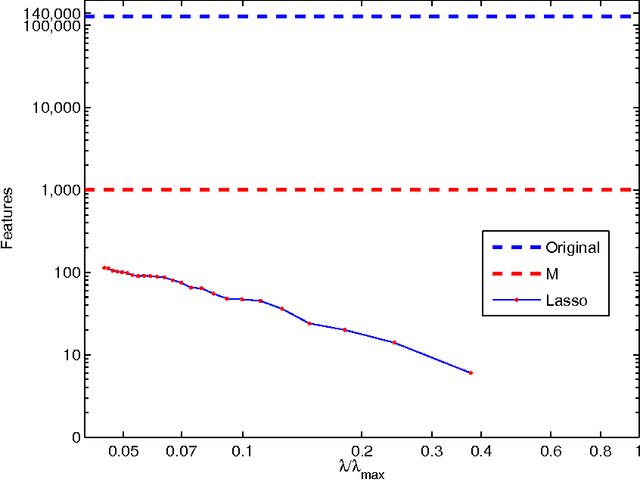
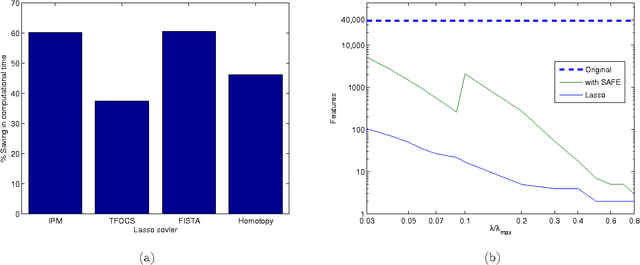
We describe a fast method to eliminate features (variables) in l1 -penalized least-square regression (or LASSO) problems. The elimination of features leads to a potentially substantial reduction in running time, specially for large values of the penalty parameter. Our method is not heuristic: it only eliminates features that are guaranteed to be absent after solving the LASSO problem. The feature elimination step is easy to parallelize and can test each feature for elimination independently. Moreover, the computational effort of our method is negligible compared to that of solving the LASSO problem - roughly it is the same as single gradient step. Our method extends the scope of existing LASSO algorithms to treat larger data sets, previously out of their reach. We show how our method can be extended to general l1 -penalized convex problems and present preliminary results for the Sparse Support Vector Machine and Logistic Regression problems.
Safe Feature Elimination in Sparse Supervised Learning
Oct 26, 2010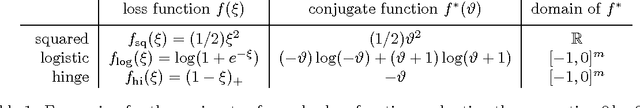
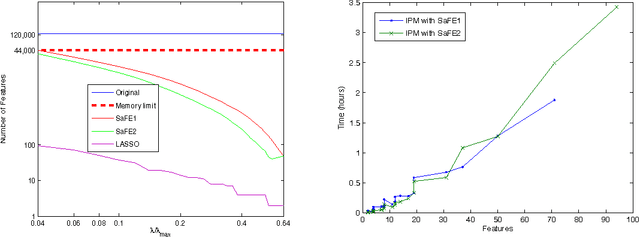
We investigate fast methods that allow to quickly eliminate variables (features) in supervised learning problems involving a convex loss function and a $l_1$-norm penalty, leading to a potentially substantial reduction in the number of variables prior to running the supervised learning algorithm. The methods are not heuristic: they only eliminate features that are {\em guaranteed} to be absent after solving the learning problem. Our framework applies to a large class of problems, including support vector machine classification, logistic regression and least-squares. The complexity of the feature elimination step is negligible compared to the typical computational effort involved in the sparse supervised learning problem: it grows linearly with the number of features times the number of examples, with much better count if data is sparse. We apply our method to data sets arising in text classification and observe a dramatic reduction of the dimensionality, hence in computational effort required to solve the learning problem, especially when very sparse classifiers are sought. Our method allows to immediately extend the scope of existing algorithms, allowing us to run them on data sets of sizes that were out of their reach before.