 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural FOXP2 -- Language Specific Neuron Steering for Targeted Language Improvement in LLMs
Feb 01, 2026LLMs are multilingual by training, yet their lingua franca is often English, reflecting English language dominance in pretraining. Other languages remain in parametric memory but are systematically suppressed. We argue that language defaultness is governed by a sparse, low-rank control circuit, language neurons, that can be mechanistically isolated and safely steered. We introduce Neural FOXP2, that makes a chosen language (Hindi or Spanish) primary in a model by steering language-specific neurons. Neural FOXP2 proceeds in three stages: (i) Localize: We train per-layer SAEs so each activation decomposes into a small set of active feature components. For every feature, we quantify English vs. Hindi/Spanish selectivity overall logit-mass lift toward the target-language token set. Tracing the top-ranked features back to their strongest contributing units yields a compact language-neuron set. (ii) Steering directions: We localize controllable language-shift geometry via a spectral low-rank analysis. For each layer, we build English to target activation-difference matrices and perform layerwise SVD to extract the dominant singular directions governing language change. The eigengap and effective-rank spectra identify a compact steering subspace and an empirically chosen intervention window (where these directions are strongest and most stable). (iii) Steer: We apply a signed, sparse activation shift targeted to the language neurons. Concretely, within low to mid layers we add a positive steering along the target-language dominant directions and a compensating negative shift toward the null space for the English neurons, yielding controllable target-language defaultness.
Stochastic CHAOS: Why Deterministic Inference Kills, and Distributional Variability Is the Heartbeat of Artifical Cognition
Jan 12, 2026Deterministic inference is a comforting ideal in classical software: the same program on the same input should always produce the same output. As large language models move into real-world deployment, this ideal has been imported wholesale into inference stacks. Recent work from the Thinking Machines Lab has presented a detailed analysis of nondeterminism in LLM inference, showing how batch-invariant kernels and deterministic attention can enforce bitwise-identical outputs, positioning deterministic inference as a prerequisite for reproducibility and enterprise reliability. In this paper, we take the opposite stance. We argue that, for LLMs, deterministic inference kills. It kills the ability to model uncertainty, suppresses emergent abilities, collapses reasoning into a single brittle path, and weakens safety alignment by hiding tail risks. LLMs implement conditional distributions over outputs, not fixed functions. Collapsing these distributions to a single canonical completion may appear reassuring, but it systematically conceals properties central to artificial cognition. We instead advocate Stochastic CHAOS, treating distributional variability as a signal to be measured and controlled. Empirically, we show that deterministic inference is systematically misleading. Single-sample deterministic evaluation underestimates both capability and fragility, masking failure probability under paraphrases and noise. Phase-like transitions associated with emergent abilities disappear under greedy decoding. Multi-path reasoning degrades when forced onto deterministic backbones, reducing accuracy and diagnostic insight. Finally, deterministic evaluation underestimates safety risk by hiding rare but dangerous behaviors that appear only under multi-sample evaluation.
KBCNMUJAL@HASOC-Dravidian-CodeMix-FIRE2020: Using Machine Learning for Detection of Hate Speech and Offensive Code-Mixed Social Media text
Feb 19, 2021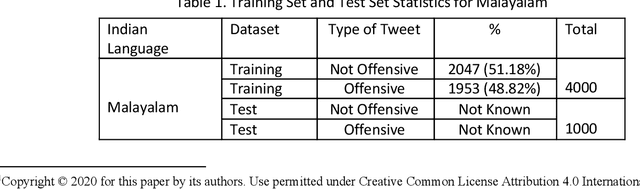
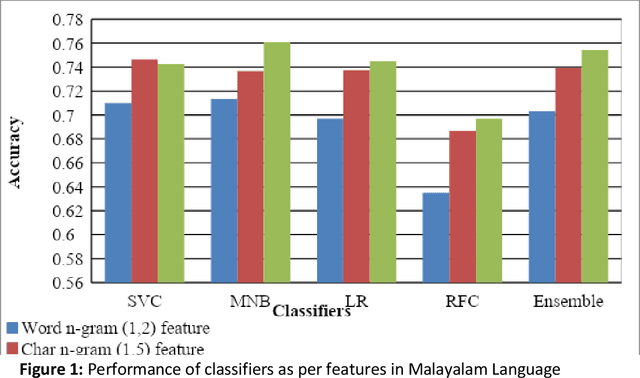

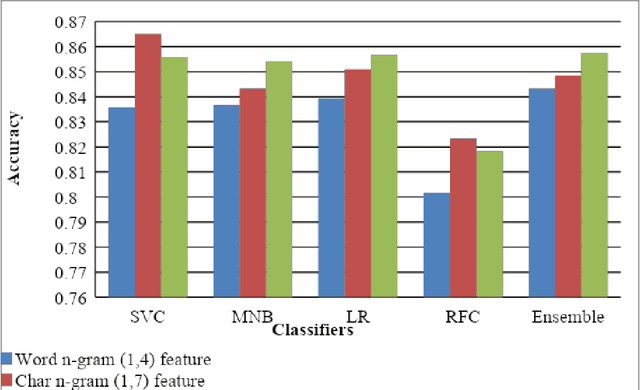
This paper describes the system submitted by our team, KBCNMUJAL, for Task 2 of the shared task Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC), at Forum for Information Retrieval Evaluation, December 16-20, 2020, Hyderabad, India. The datasets of two Dravidian languages Viz. Malayalam and Tamil of size 4000 observations, each were shared by the HASOC organizers. These datasets are used to train the machine using different machine learning algorithms, based on classification and regression models. The datasets consist of tweets or YouTube comments with two class labels offensive and not offensive. The machine is trained to classify such social media messages in these two categories. Appropriate n-gram feature sets are extracted to learn the specific characteristics of the Hate Speech text messages. These feature models are based on TFIDF weights of n-gram. The referred work and respective experiments show that the features such as word, character and combined model of word and character n-grams could be used to identify the term patterns of offensive text contents. As a part of the HASOC shared task, the test data sets are made available by the HASOC track organizers. The best performing classification models developed for both languages are applied on test datasets. The model which gives the highest accuracy result on training dataset for Malayalam language was experimented to predict the categories of respective test data. This system has obtained an F1 score of 0.77. Similarly the best performing model for Tamil language has obtained an F1 score of 0.87. This work has received 2nd and 3rd rank in this shared Task 2 for Malayalam and Tamil language respectively. The proposed system is named HASOC_kbcnmujal.