 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKBCNMUJAL@HASOC-Dravidian-CodeMix-FIRE2020: Using Machine Learning for Detection of Hate Speech and Offensive Code-Mixed Social Media text
Paper and Code
Feb 19, 2021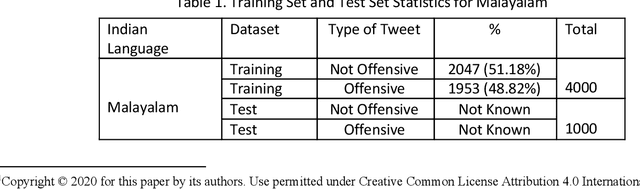
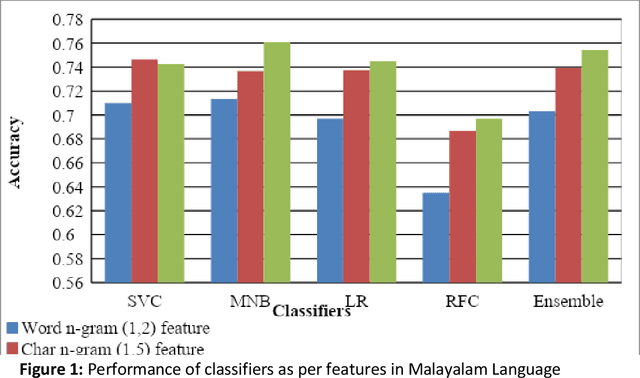

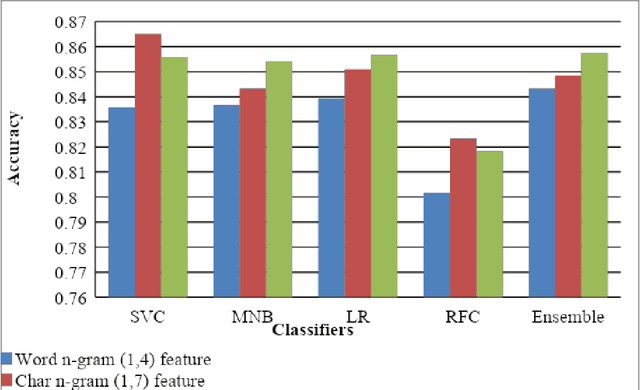
This paper describes the system submitted by our team, KBCNMUJAL, for Task 2 of the shared task Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC), at Forum for Information Retrieval Evaluation, December 16-20, 2020, Hyderabad, India. The datasets of two Dravidian languages Viz. Malayalam and Tamil of size 4000 observations, each were shared by the HASOC organizers. These datasets are used to train the machine using different machine learning algorithms, based on classification and regression models. The datasets consist of tweets or YouTube comments with two class labels offensive and not offensive. The machine is trained to classify such social media messages in these two categories. Appropriate n-gram feature sets are extracted to learn the specific characteristics of the Hate Speech text messages. These feature models are based on TFIDF weights of n-gram. The referred work and respective experiments show that the features such as word, character and combined model of word and character n-grams could be used to identify the term patterns of offensive text contents. As a part of the HASOC shared task, the test data sets are made available by the HASOC track organizers. The best performing classification models developed for both languages are applied on test datasets. The model which gives the highest accuracy result on training dataset for Malayalam language was experimented to predict the categories of respective test data. This system has obtained an F1 score of 0.77. Similarly the best performing model for Tamil language has obtained an F1 score of 0.87. This work has received 2nd and 3rd rank in this shared Task 2 for Malayalam and Tamil language respectively. The proposed system is named HASOC_kbcnmujal.