 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Marginal MAP Exactly by Probabilistic Circuit Transformations
Nov 08, 2021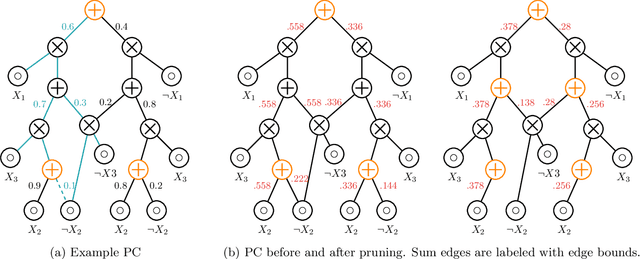
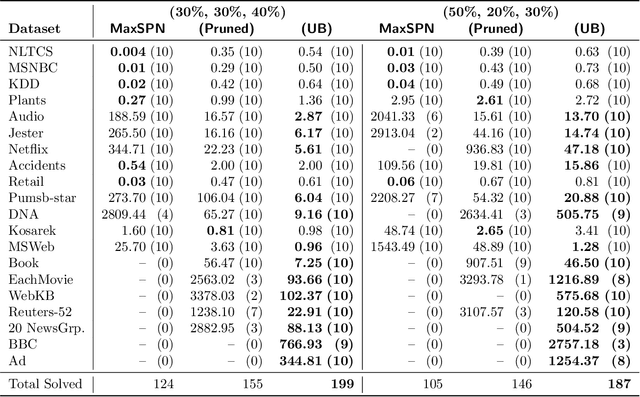
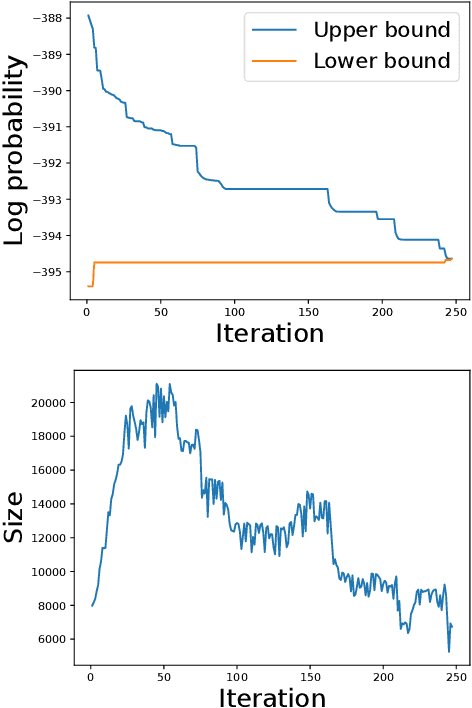
Probabilistic circuits (PCs) are a class of tractable probabilistic models that allow efficient, often linear-time, inference of queries such as marginals and most probable explanations (MPE). However, marginal MAP, which is central to many decision-making problems, remains a hard query for PCs unless they satisfy highly restrictive structural constraints. In this paper, we develop a pruning algorithm that removes parts of the PC that are irrelevant to a marginal MAP query, shrinking the PC while maintaining the correct solution. This pruning technique is so effective that we are able to build a marginal MAP solver based solely on iteratively transforming the circuit -- no search is required. We empirically demonstrate the efficacy of our approach on real-world datasets.
Symbolic Querying of Vector Spaces: Probabilistic Databases Meets Relational Embeddings
Feb 24, 2020


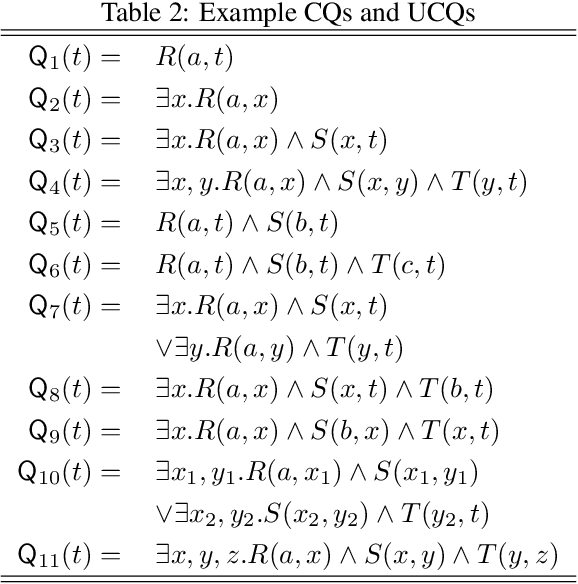
To deal with increasing amounts of uncertainty and incompleteness in relational data, we propose unifying techniques from probabilistic databases and relational embedding models. We use probabilistic databases as our formalism to define the probabilistic model with respect to which all queries are done. This allows us to leverage the rich literature of theory and algorithms from probabilistic databases for solving problems. While this formalization can be used with any relational embedding model, the lack of a well defined joint probability distribution causes simple problems to become provably hard. With this in mind, we introduce \TO, a relational embedding model designed in terms of probabilistic databases to exploit typical embedding assumptions within the probabilistic framework. Using principled, efficient inference algorithms that can be derived from its definition, we empirically demonstrate that \TOs is an effective and general model for these tasks.
On Constrained Open-World Probabilistic Databases
Apr 02, 2019


Increasing amounts of available data have led to a heightened need for representing large-scale probabilistic knowledge bases. One approach is to use a probabilistic database, a model with strong assumptions that allow for efficiently answering many interesting queries. Recent work on open-world probabilistic databases strengthens the semantics of these probabilistic databases by discarding the assumption that any information not present in the data must be false. While intuitive, these semantics are not sufficiently precise to give reasonable answers to queries. We propose overcoming these issues by using constraints to restrict this open world. We provide an algorithm for one class of queries, and establish a basic hardness result for another. Finally, we propose an efficient and tight approximation for a large class of queries.
A Semantic Loss Function for Deep Learning with Symbolic Knowledge
Jun 08, 2018

This paper develops a novel methodology for using symbolic knowledge in deep learning. From first principles, we derive a semantic loss function that bridges between neural output vectors and logical constraints. This loss function captures how close the neural network is to satisfying the constraints on its output. An experimental evaluation shows that it effectively guides the learner to achieve (near-)state-of-the-art results on semi-supervised multi-class classification. Moreover, it significantly increases the ability of the neural network to predict structured objects, such as rankings and paths. These discrete concepts are tremendously difficult to learn, and benefit from a tight integration of deep learning and symbolic reasoning methods.
Approximate Knowledge Compilation by Online Collapsed Importance Sampling
May 31, 2018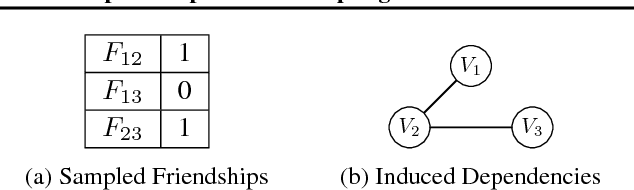
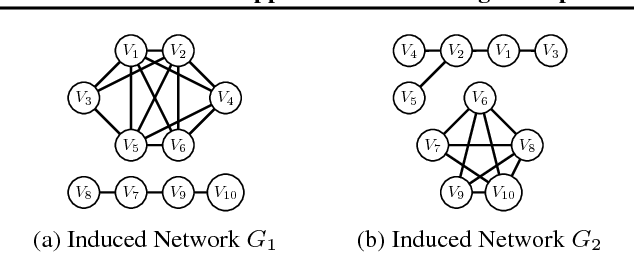


We introduce collapsed compilation, a novel approximate inference algorithm for discrete probabilistic graphical models. It is a collapsed sampling algorithm that incrementally selects which variable to sample next based on the partial sample obtained so far. This online collapsing, together with knowledge compilation inference on the remaining variables, naturally exploits local structure and context- specific independence in the distribution. These properties are naturally exploited in exact inference, but are difficult to harness for approximate inference. More- over, by having a partially compiled circuit available during sampling, collapsed compilation has access to a highly effective proposal distribution for importance sampling. Our experimental evaluation shows that collapsed compilation performs well on standard benchmarks. In particular, when the amount of exact inference is equally limited, collapsed compilation is competitive with the state of the art, and outperforms it on several benchmarks.