 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Querying of Vector Spaces: Probabilistic Databases Meets Relational Embeddings
Paper and Code



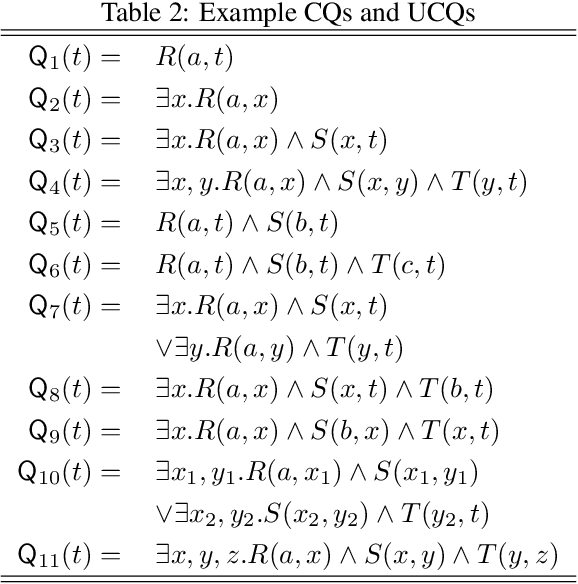
To deal with increasing amounts of uncertainty and incompleteness in relational data, we propose unifying techniques from probabilistic databases and relational embedding models. We use probabilistic databases as our formalism to define the probabilistic model with respect to which all queries are done. This allows us to leverage the rich literature of theory and algorithms from probabilistic databases for solving problems. While this formalization can be used with any relational embedding model, the lack of a well defined joint probability distribution causes simple problems to become provably hard. With this in mind, we introduce \TO, a relational embedding model designed in terms of probabilistic databases to exploit typical embedding assumptions within the probabilistic framework. Using principled, efficient inference algorithms that can be derived from its definition, we empirically demonstrate that \TOs is an effective and general model for these tasks.