 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaptioning Near-Future Activity Sequences
Aug 02, 2019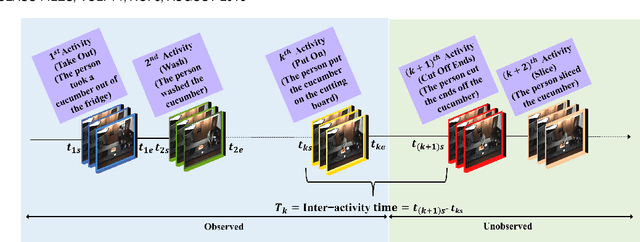
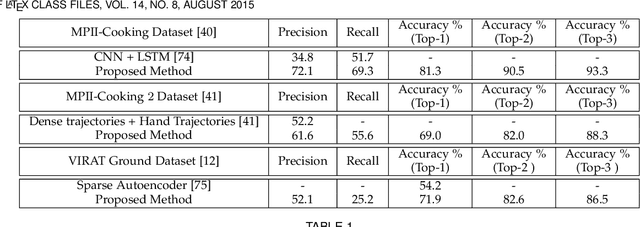

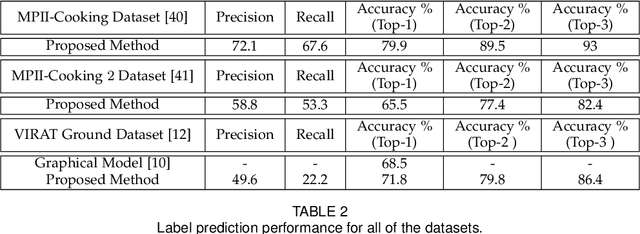
Most of the existing works on human activity analysis focus on recognition or early recognition of the activity labels from complete or partial observations. Similarly, existing video captioning approaches focus on the observed events in videos. Predicting the labels and the captions of future activities where no frames of the predicted activities have been observed is a challenging problem, with important applications that require anticipatory response. In this work, we propose a system that can infer the labels and the captions of a sequence of future activities. Our proposed network for label prediction of a future activity sequence is similar to a hybrid Siamese network with three branches where the first branch takes visual features from the objects present in the scene, the second branch takes observed activity features and the third branch captures the last observed activity features. The predicted labels and the observed scene context are then mapped to meaningful captions using a sequence-to-sequence learning based method. Experiments on three challenging activity analysis datasets and a video description dataset demonstrate that both our label prediction framework and captioning framework outperforms the state-of-the-arts.
Multi-View Frame Reconstruction with Conditional GAN
Sep 27, 2018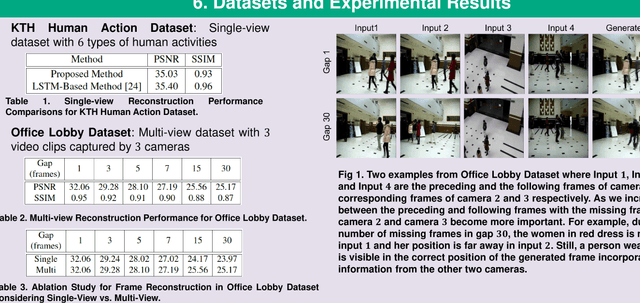
Multi-view frame reconstruction is an important problem particularly when multiple frames are missing and past and future frames within the camera are far apart from the missing ones. Realistic coherent frames can still be reconstructed using corresponding frames from other overlapping cameras. We propose an adversarial approach to learn the spatio-temporal representation of the missing frame using conditional Generative Adversarial Network (cGAN). The conditional input to each cGAN is the preceding or following frames within the camera or the corresponding frames in other overlapping cameras, all of which are merged together using a weighted average. Representations learned from frames within the camera are given more weight compared to the ones learned from other cameras when they are close to the missing frames and vice versa. Experiments on two challenging datasets demonstrate that our framework produces comparable results with the state-of-the-art reconstruction method in a single camera and achieves promising performance in multi-camera scenario.