 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Frame Reconstruction with Conditional GAN
Paper and Code
Sep 27, 2018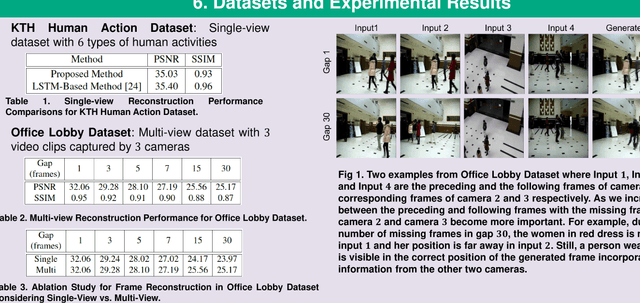
Multi-view frame reconstruction is an important problem particularly when multiple frames are missing and past and future frames within the camera are far apart from the missing ones. Realistic coherent frames can still be reconstructed using corresponding frames from other overlapping cameras. We propose an adversarial approach to learn the spatio-temporal representation of the missing frame using conditional Generative Adversarial Network (cGAN). The conditional input to each cGAN is the preceding or following frames within the camera or the corresponding frames in other overlapping cameras, all of which are merged together using a weighted average. Representations learned from frames within the camera are given more weight compared to the ones learned from other cameras when they are close to the missing frames and vice versa. Experiments on two challenging datasets demonstrate that our framework produces comparable results with the state-of-the-art reconstruction method in a single camera and achieves promising performance in multi-camera scenario.