 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Nearest Neighbor Graph via Continuous CRF for Visual Re-ranking without Fine-tuning
Dec 18, 2024



Visual re-ranking using Nearest Neighbor graph~(NN graph) has been adapted to yield high retrieval accuracy, since it is beneficial to exploring an high-dimensional manifold and applicable without additional fine-tuning. The quality of visual re-ranking using NN graph, however, is limited to that of connectivity, i.e., edges of the NN graph. Some edges can be misconnected with negative images. This is known as a noisy edge problem, resulting in a degradation of the retrieval quality. To address this, we propose a complementary denoising method based on Continuous Conditional Random Field (C-CRF) that uses a statistical distance of our similarity-based distribution. This method employs the concept of cliques to make the process computationally feasible. We demonstrate the complementarity of our method through its application to three visual re-ranking methods, observing quality boosts in landmark retrieval and person re-identification (re-ID).
Deep learning-based modularized loading protocol for parameter estimation of Bouc-Wen class models
Nov 05, 2024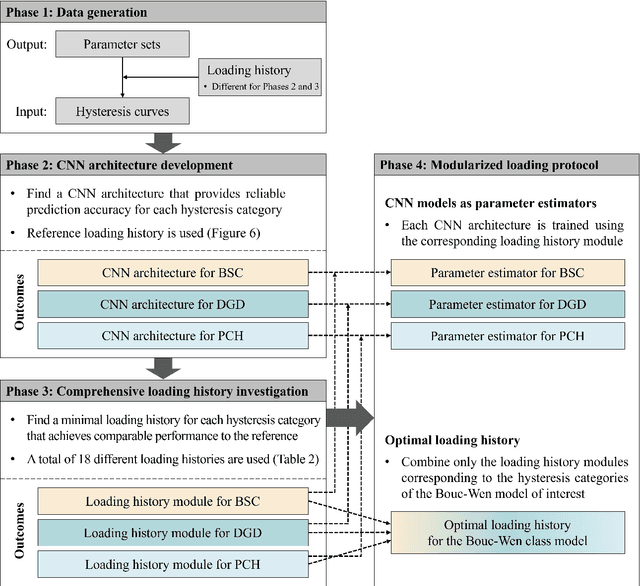


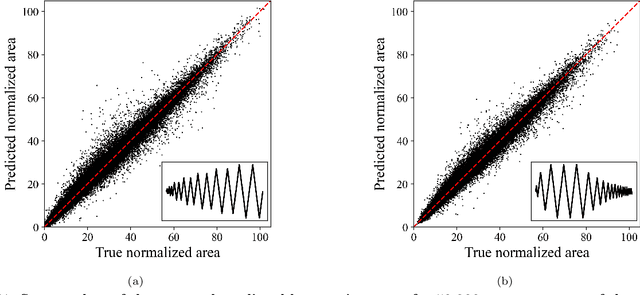
This study proposes a modularized deep learning-based loading protocol for optimal parameter estimation of Bouc-Wen (BW) class models. The protocol consists of two key components: optimal loading history construction and CNN-based rapid parameter estimation. Each component is decomposed into independent sub-modules tailored to distinct hysteretic behaviors-basic hysteresis, structural degradation, and pinching effect-making the protocol adaptable to diverse hysteresis models. Three independent CNN architectures are developed to capture the path-dependent nature of these hysteretic behaviors. By training these CNN architectures on diverse loading histories, minimal loading sequences, termed \textit{loading history modules}, are identified and then combined to construct an optimal loading history. The three CNN models, trained on the respective loading history modules, serve as rapid parameter estimators. Numerical evaluation of the protocol, including nonlinear time history analysis of a 3-story steel moment frame and fragility curve construction for a 3-story reinforced concrete frame, demonstrates that the proposed protocol significantly reduces total analysis time while maintaining or improving estimation accuracy. The proposed protocol can be extended to other hysteresis models, suggesting a systematic approach for identifying general hysteresis models.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.