 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Universal Predictors? An Empirical Study on Small Tabular Datasets
Aug 24, 2025Large Language Models (LLMs), originally developed for natural language processing (NLP), have demonstrated the potential to generalize across modalities and domains. With their in-context learning (ICL) capabilities, LLMs can perform predictive tasks over structured inputs without explicit fine-tuning on downstream tasks. In this work, we investigate the empirical function approximation capability of LLMs on small-scale structured datasets for classification, regression and clustering tasks. We evaluate the performance of state-of-the-art LLMs (GPT-5, GPT-4o, GPT-o3, Gemini-2.5-Flash, DeepSeek-R1) under few-shot prompting and compare them against established machine learning (ML) baselines, including linear models, ensemble methods and tabular foundation models (TFMs). Our results show that LLMs achieve strong performance in classification tasks under limited data availability, establishing practical zero-training baselines. In contrast, the performance in regression with continuous-valued outputs is poor compared to ML models, likely because regression demands outputs in a large (often infinite) space, and clustering results are similarly limited, which we attribute to the absence of genuine ICL in this setting. Nonetheless, this approach enables rapid, low-overhead data exploration and offers a viable alternative to traditional ML pipelines in business intelligence and exploratory analytics contexts. We further analyze the influence of context size and prompt structure on approximation quality, identifying trade-offs that affect predictive performance. Our findings suggest that LLMs can serve as general-purpose predictive engines for structured data, with clear strengths in classification and significant limitations in regression and clustering.
ASPIRE: Assistive System for Performance Evaluation in IR
Dec 20, 2024

Information Retrieval (IR) evaluation involves far more complexity than merely presenting performance measures in a table. Researchers often need to compare multiple models across various dimensions, such as the Precision-Recall trade-off and response time, to understand the reasons behind the varying performance of specific queries for different models. We introduce ASPIRE (Assistive System for Performance Evaluation in IR), a visual analytics tool designed to address these complexities by providing an extensive and user-friendly interface for in-depth analysis of IR experiments. ASPIRE supports four key aspects of IR experiment evaluation and analysis: single/multi-experiment comparisons, query-level analysis, query characteristics-performance interplay, and collection-based retrieval analysis. We showcase the functionality of ASPIRE using the TREC Clinical Trials collection. ASPIRE is an open-source toolkit available online: https://github.com/GiorgosPeikos/ASPIRE
Utilizing ChatGPT to Enhance Clinical Trial Enrollment
Jun 03, 2023Clinical trials are a critical component of evaluating the effectiveness of new medical interventions and driving advancements in medical research. Therefore, timely enrollment of patients is crucial to prevent delays or premature termination of trials. In this context, Electronic Health Records (EHRs) have emerged as a valuable tool for identifying and enrolling eligible participants. In this study, we propose an automated approach that leverages ChatGPT, a large language model, to extract patient-related information from unstructured clinical notes and generate search queries for retrieving potentially eligible clinical trials. Our empirical evaluation, conducted on two benchmark retrieval collections, shows improved retrieval performance compared to existing approaches when several general-purposed and task-specific prompts are used. Notably, ChatGPT-generated queries also outperform human-generated queries in terms of retrieval performance. These findings highlight the potential use of ChatGPT to enhance clinical trial enrollment while ensuring the quality of medical service and minimizing direct risks to patients.
DUTH at SemEval-2020 Task 11: BERT with Entity Mapping for Propaganda Classification
Aug 25, 2020
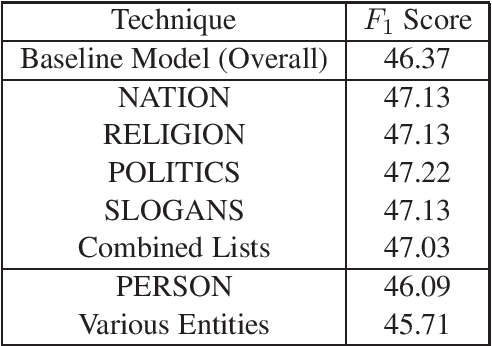
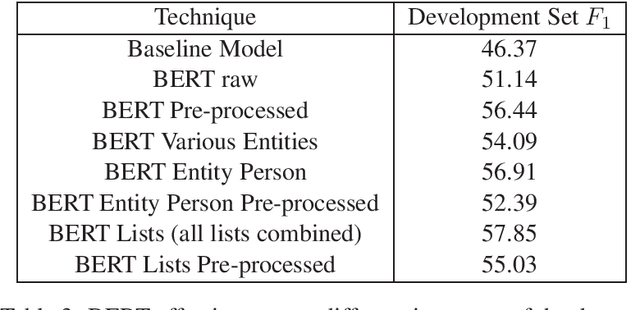
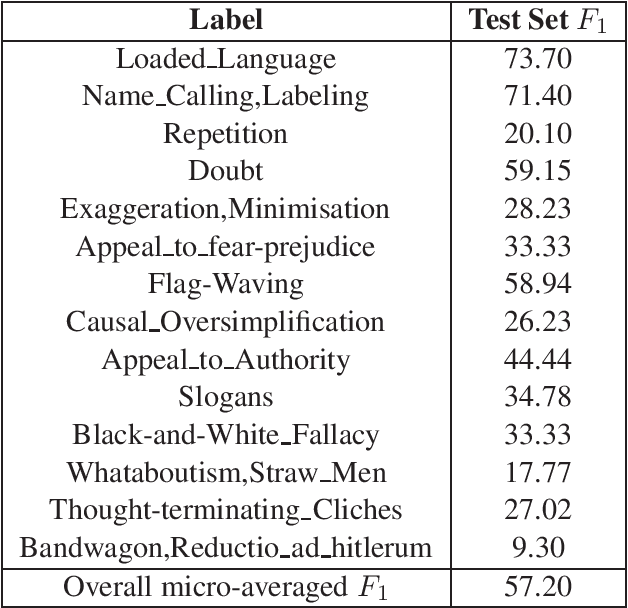
This report describes the methods employed by the Democritus University of Thrace (DUTH) team for participating in SemEval-2020 Task 11: Detection of Propaganda Techniques in News Articles. Our team dealt with Subtask 2: Technique Classification. We used shallow Natural Language Processing (NLP) preprocessing techniques to reduce the noise in the dataset, feature selection methods, and common supervised machine learning algorithms. Our final model is based on using the BERT system with entity mapping. To improve our model's accuracy, we mapped certain words into five distinct categories by employing word-classes and entity recognition.