Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUTH at SemEval-2020 Task 11: BERT with Entity Mapping for Propaganda Classification
Paper and Code

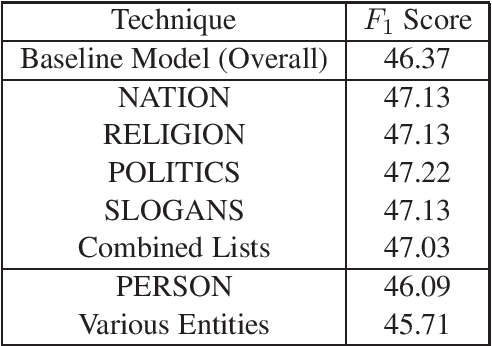
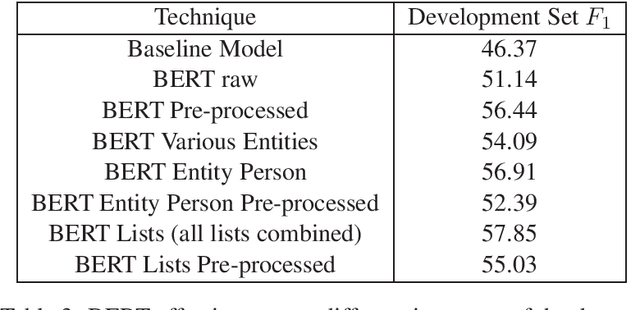
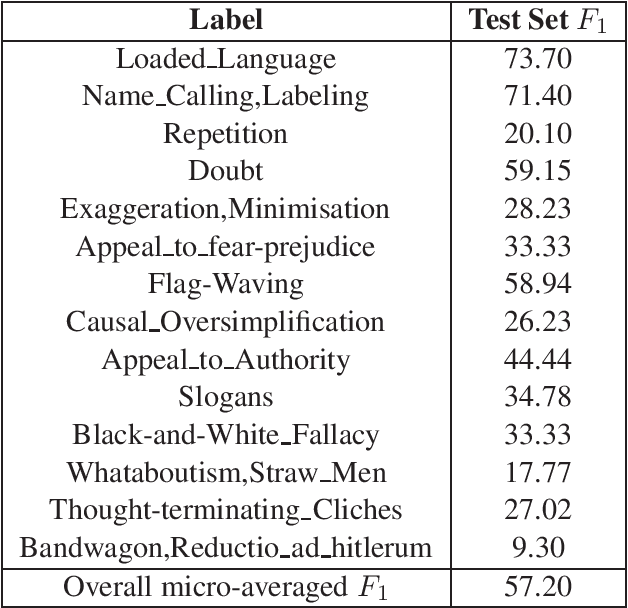
This report describes the methods employed by the Democritus University of Thrace (DUTH) team for participating in SemEval-2020 Task 11: Detection of Propaganda Techniques in News Articles. Our team dealt with Subtask 2: Technique Classification. We used shallow Natural Language Processing (NLP) preprocessing techniques to reduce the noise in the dataset, feature selection methods, and common supervised machine learning algorithms. Our final model is based on using the BERT system with entity mapping. To improve our model's accuracy, we mapped certain words into five distinct categories by employing word-classes and entity recognition.
View paper on