 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHateMirage: An Explainable Multi-Dimensional Dataset for Decoding Faux Hate and Subtle Online Abuse
Mar 03, 2026Subtle and indirect hate speech remains an underexplored challenge in online safety research, particularly when harmful intent is embedded within misleading or manipulative narratives. Existing hate speech datasets primarily capture overt toxicity, underrepresenting the nuanced ways misinformation can incite or normalize hate. To address this gap, we present HateMirage, a novel dataset of Faux Hate comments designed to advance reasoning and explainability research on hate emerging from fake or distorted narratives. The dataset was constructed by identifying widely debunked misinformation claims from fact-checking sources and tracing related YouTube discussions, resulting in 4,530 user comments. Each comment is annotated along three interpretable dimensions: Target (who is affected), Intent (the underlying motivation or goal behind the comment), and Implication (its potential social impact). Unlike prior explainability datasets such as HateXplain and HARE, which offer token-level or single-dimensional reasoning, HateMirage introduces a multi-dimensional explanation framework that captures the interplay between misinformation, harm, and social consequence. We benchmark multiple open-source language models on HateMirage using ROUGE-L F1 and Sentence-BERT similarity to assess explanation coherence. Results suggest that explanation quality may depend more on pretraining diversity and reasoning-oriented data rather than on model scale alone. By coupling misinformation reasoning with harm attribution, HateMirage establishes a new benchmark for interpretable hate detection and responsible AI research.
Deceptive Humor: A Synthetic Multilingual Benchmark Dataset for Bridging Fabricated Claims with Humorous Content
Mar 20, 2025



This paper presents the Deceptive Humor Dataset (DHD), a novel resource for studying humor derived from fabricated claims and misinformation. In an era of rampant misinformation, understanding how humor intertwines with deception is essential. DHD consists of humor-infused comments generated from false narratives, incorporating fabricated claims and manipulated information using the ChatGPT-4o model. Each instance is labeled with a Satire Level, ranging from 1 for subtle satire to 3 for high-level satire and classified into five distinct Humor Categories: Dark Humor, Irony, Social Commentary, Wordplay, and Absurdity. The dataset spans multiple languages including English, Telugu, Hindi, Kannada, Tamil, and their code-mixed variants (Te-En, Hi-En, Ka-En, Ta-En), making it a valuable multilingual benchmark. By introducing DHD, we establish a structured foundation for analyzing humor in deceptive contexts, paving the way for a new research direction that explores how humor not only interacts with misinformation but also influences its perception and spread. We establish strong baselines for the proposed dataset, providing a foundation for future research to benchmark and advance deceptive humor detection models.
Enabling Quantum Natural Language Processing for Hindi Language
Dec 02, 2023



Quantum Natural Language Processing (QNLP) is taking huge leaps in solving the shortcomings of classical Natural Language Processing (NLP) techniques and moving towards a more "Explainable" NLP system. The current literature around QNLP focuses primarily on implementing QNLP techniques in sentences in the English language. In this paper, we propose to enable the QNLP approach to HINDI, which is the third most spoken language in South Asia. We present the process of building the parameterized quantum circuits required to undertake QNLP on Hindi sentences. We use the pregroup representation of Hindi and the DisCoCat framework to draw sentence diagrams. Later, we translate these diagrams to Parameterised Quantum Circuits based on Instantaneous Quantum Polynomial (IQP) style ansatz. Using these parameterized quantum circuits allows one to train grammar and topic-aware sentence classifiers for the Hindi Language.
IIITDWD-ShankarB@ Dravidian-CodeMixi-HASOC2021: mBERT based model for identification of offensive content in south Indian languages
Apr 13, 2022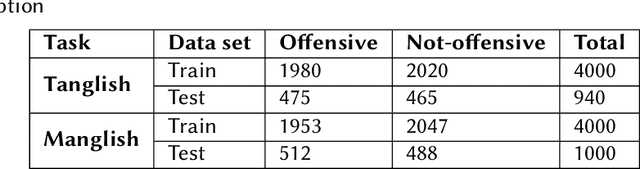


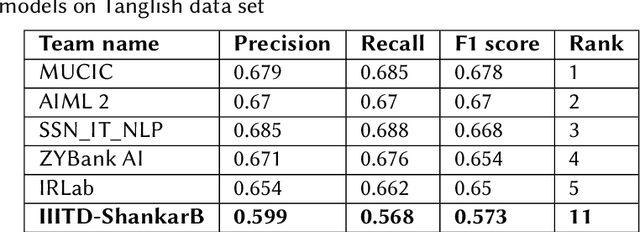
In recent years, there has been a lot of focus on offensive content. The amount of offensive content generated by social media is increasing at an alarming rate. This created a greater need to address this issue than ever before. To address these issues, the organizers of "Dravidian-Code Mixed HASOC-2020" have created two challenges. Task 1 involves identifying offensive content in Malayalam data, whereas Task 2 includes Malayalam and Tamil Code Mixed Sentences. Our team participated in Task 2. In our suggested model, we experiment with multilingual BERT to extract features, and three different classifiers are used on extracted features. Our model received a weighted F1 score of 0.70 for Malayalam data and was ranked fifth; we also received a weighted F1 score of 0.573 for Tamil Code Mixed data and were ranked eleventh.
Ranking Online Consumer Reviews
Jan 17, 2019



The product reviews are posted online in the hundreds and even in the thousands for some popular products. Handling such a large volume of continuously generated online content is a challenging task for buyers, sellers, and even researchers. The purpose of this study is to rank the overwhelming number of reviews using their predicted helpfulness score. The helpfulness score is predicted using features extracted from review text data, product description data and customer question-answer data of a product using random-forest classifier and gradient boosting regressor. The system is made to classify the reviews into low or high quality by random-forest classifier. The helpfulness score of the high-quality reviews is only predicted using gradient boosting regressor. The helpfulness score of the low-quality reviews is not calculated because they are never going to be in the top k reviews. They are just added at the end of the review list to the review-listing website. The proposed system provides fair review placement on review listing pages and making all high-quality reviews visible to customers on the top. The experimental results on data from two popular Indian e-commerce websites validate our claim, as 3-4 new high-quality reviews are placed in the top ten reviews along with 5-6 old reviews based on review helpfulness. Our findings indicate that inclusion of features from product description data and customer question-answer data improves the prediction accuracy of the helpfulness score.