 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation reference identification from tweets during emergencies: A deep learning approach
Jan 24, 2019
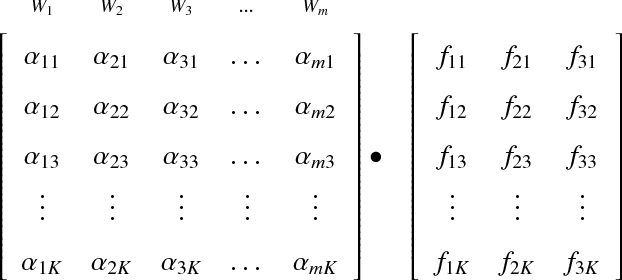

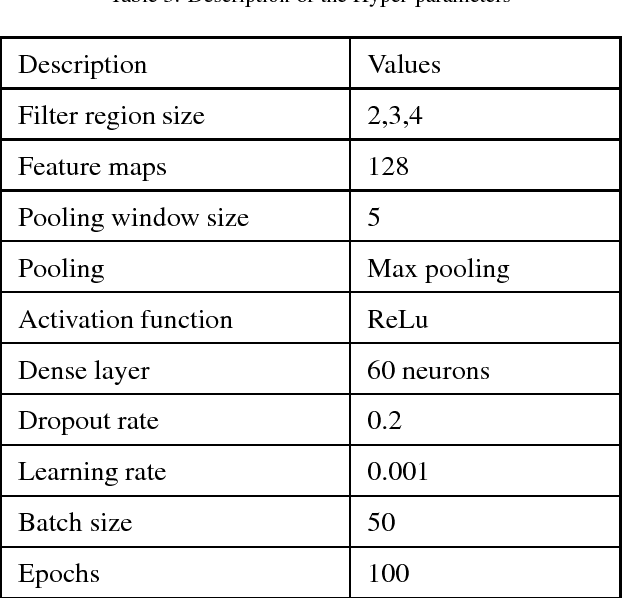
Twitter is recently being used during crises to communicate with officials and provide rescue and relief operation in real time. The geographical location information of the event, as well as users, are vitally important in such scenarios. The identification of geographic location is one of the challenging tasks as the location information fields, such as user location and place name of tweets are not reliable. The extraction of location information from tweet text is difficult as it contains a lot of non-standard English, grammatical errors, spelling mistakes, non-standard abbreviations, and so on. This research aims to extract location words used in the tweet using a Convolutional Neural Network (CNN) based model. We achieved the exact matching score of 0.929, Hamming loss of 0.002, and $F_1$-score of 0.96 for the tweets related to the earthquake. Our model was able to extract even three- to four-word long location references which is also evident from the exact matching score of over 92\%. The findings of this paper can help in early event localization, emergency situations, real-time road traffic management, localized advertisement, and in various location-based services.
Ranking Online Consumer Reviews
Jan 17, 2019



The product reviews are posted online in the hundreds and even in the thousands for some popular products. Handling such a large volume of continuously generated online content is a challenging task for buyers, sellers, and even researchers. The purpose of this study is to rank the overwhelming number of reviews using their predicted helpfulness score. The helpfulness score is predicted using features extracted from review text data, product description data and customer question-answer data of a product using random-forest classifier and gradient boosting regressor. The system is made to classify the reviews into low or high quality by random-forest classifier. The helpfulness score of the high-quality reviews is only predicted using gradient boosting regressor. The helpfulness score of the low-quality reviews is not calculated because they are never going to be in the top k reviews. They are just added at the end of the review list to the review-listing website. The proposed system provides fair review placement on review listing pages and making all high-quality reviews visible to customers on the top. The experimental results on data from two popular Indian e-commerce websites validate our claim, as 3-4 new high-quality reviews are placed in the top ten reviews along with 5-6 old reviews based on review helpfulness. Our findings indicate that inclusion of features from product description data and customer question-answer data improves the prediction accuracy of the helpfulness score.