 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIIITDWD-ShankarB@ Dravidian-CodeMixi-HASOC2021: mBERT based model for identification of offensive content in south Indian languages
Paper and Code
Apr 13, 2022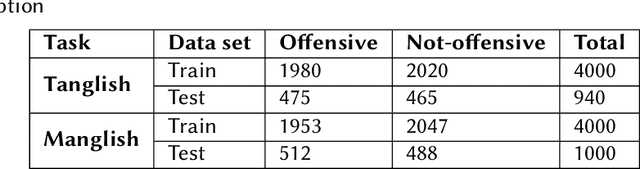


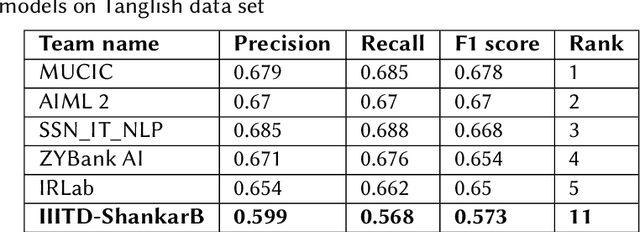
In recent years, there has been a lot of focus on offensive content. The amount of offensive content generated by social media is increasing at an alarming rate. This created a greater need to address this issue than ever before. To address these issues, the organizers of "Dravidian-Code Mixed HASOC-2020" have created two challenges. Task 1 involves identifying offensive content in Malayalam data, whereas Task 2 includes Malayalam and Tamil Code Mixed Sentences. Our team participated in Task 2. In our suggested model, we experiment with multilingual BERT to extract features, and three different classifiers are used on extracted features. Our model received a weighted F1 score of 0.70 for Malayalam data and was ranked fifth; we also received a weighted F1 score of 0.573 for Tamil Code Mixed data and were ranked eleventh.