 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeceptive Humor: A Synthetic Multilingual Benchmark Dataset for Bridging Fabricated Claims with Humorous Content
Mar 20, 2025



This paper presents the Deceptive Humor Dataset (DHD), a novel resource for studying humor derived from fabricated claims and misinformation. In an era of rampant misinformation, understanding how humor intertwines with deception is essential. DHD consists of humor-infused comments generated from false narratives, incorporating fabricated claims and manipulated information using the ChatGPT-4o model. Each instance is labeled with a Satire Level, ranging from 1 for subtle satire to 3 for high-level satire and classified into five distinct Humor Categories: Dark Humor, Irony, Social Commentary, Wordplay, and Absurdity. The dataset spans multiple languages including English, Telugu, Hindi, Kannada, Tamil, and their code-mixed variants (Te-En, Hi-En, Ka-En, Ta-En), making it a valuable multilingual benchmark. By introducing DHD, we establish a structured foundation for analyzing humor in deceptive contexts, paving the way for a new research direction that explores how humor not only interacts with misinformation but also influences its perception and spread. We establish strong baselines for the proposed dataset, providing a foundation for future research to benchmark and advance deceptive humor detection models.
IIITDWD-ShankarB@ Dravidian-CodeMixi-HASOC2021: mBERT based model for identification of offensive content in south Indian languages
Apr 13, 2022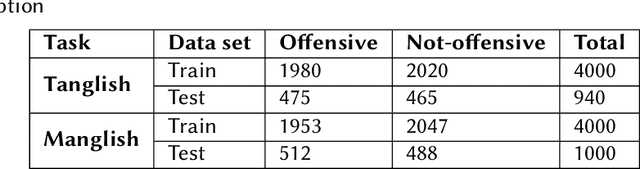


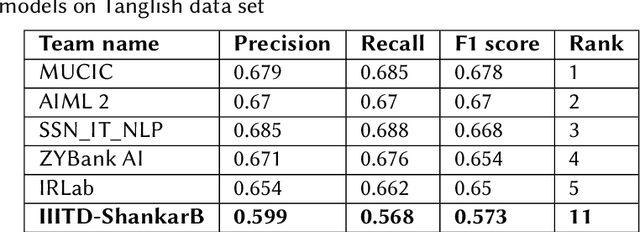
In recent years, there has been a lot of focus on offensive content. The amount of offensive content generated by social media is increasing at an alarming rate. This created a greater need to address this issue than ever before. To address these issues, the organizers of "Dravidian-Code Mixed HASOC-2020" have created two challenges. Task 1 involves identifying offensive content in Malayalam data, whereas Task 2 includes Malayalam and Tamil Code Mixed Sentences. Our team participated in Task 2. In our suggested model, we experiment with multilingual BERT to extract features, and three different classifiers are used on extracted features. Our model received a weighted F1 score of 0.70 for Malayalam data and was ranked fifth; we also received a weighted F1 score of 0.573 for Tamil Code Mixed data and were ranked eleventh.