 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoencoder for Synthetic to Real Generalization: From Simple to More Complex Scenes
Apr 01, 2022

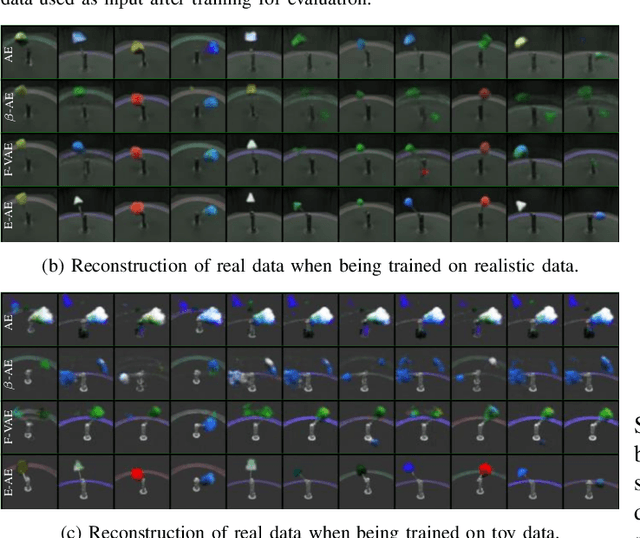
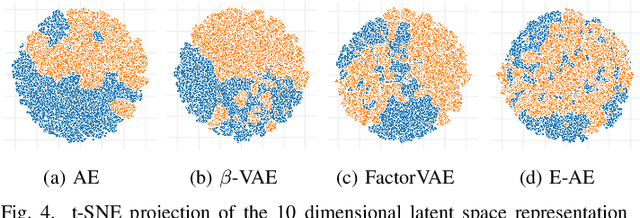
Learning on synthetic data and transferring the resulting properties to their real counterparts is an important challenge for reducing costs and increasing safety in machine learning. In this work, we focus on autoencoder architectures and aim at learning latent space representations that are invariant to inductive biases caused by the domain shift between simulated and real images showing the same scenario. We train on synthetic images only, present approaches to increase generalizability and improve the preservation of the semantics to real datasets of increasing visual complexity. We show that pre-trained feature extractors (e.g. VGG) can be sufficient for generalization on images of lower complexity, but additional improvements are required for visually more complex scenes. To this end, we demonstrate a new sampling technique, which matches semantically important parts of the image, while randomizing the other parts, leads to salient feature extraction and a neglection of unimportant parts. This helps the generalization to real data and we further show that our approach outperforms fine-tuned classification models.
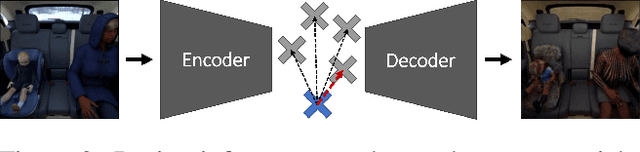
Autoencoder Attractors for Uncertainty Estimation
Apr 01, 2022


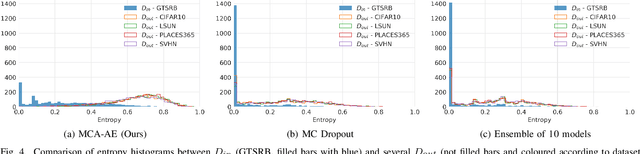
The reliability assessment of a machine learning model's prediction is an important quantity for the deployment in safety critical applications. Not only can it be used to detect novel sceneries, either as out-of-distribution or anomaly sample, but it also helps to determine deficiencies in the training data distribution. A lot of promising research directions have either proposed traditional methods like Gaussian processes or extended deep learning based approaches, for example, by interpreting them from a Bayesian point of view. In this work we propose a novel approach for uncertainty estimation based on autoencoder models: The recursive application of a previously trained autoencoder model can be interpreted as a dynamical system storing training examples as attractors. While input images close to known samples will converge to the same or similar attractor, input samples containing unknown features are unstable and converge to different training samples by potentially removing or changing characteristic features. The use of dropout during training and inference leads to a family of similar dynamical systems, each one being robust on samples close to the training distribution but unstable on new features. Either the model reliably removes these features or the resulting instability can be exploited to detect problematic input samples. We evaluate our approach on several dataset combinations as well as on an industrial application for occupant classification in the vehicle interior for which we additionally release a new synthetic dataset.
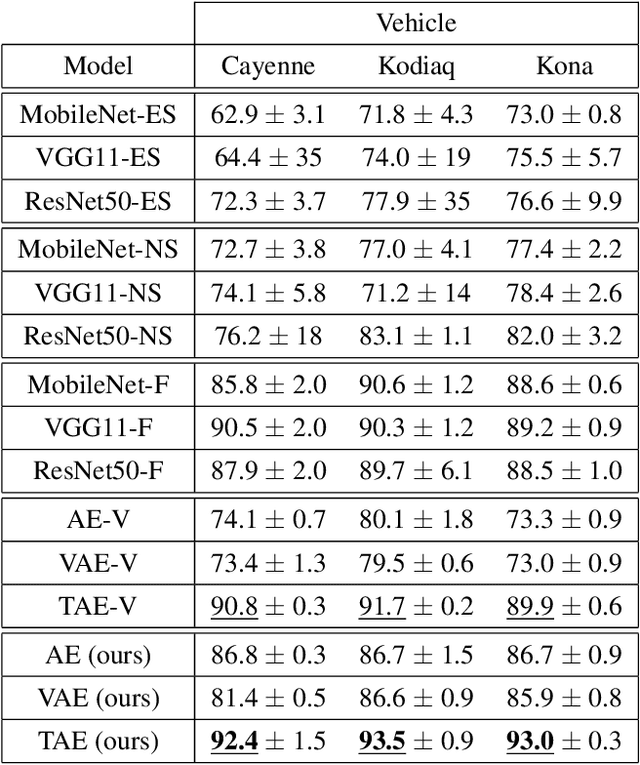
Autoencoder Based Inter-Vehicle Generalization for In-Cabin Occupant Classification
May 07, 2021
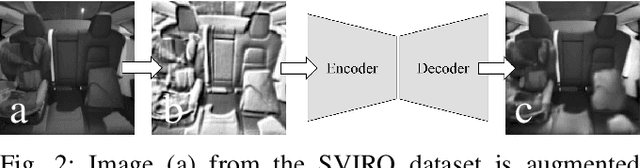
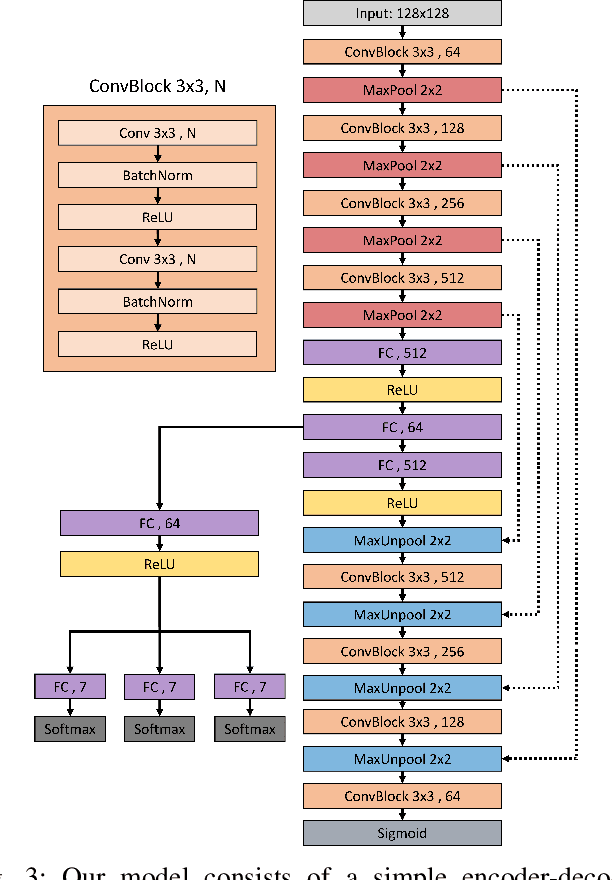
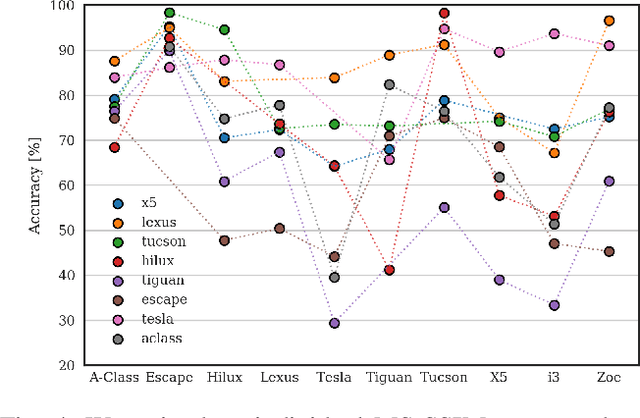
Common domain shift problem formulations consider the integration of multiple source domains, or the target domain during training. Regarding the generalization of machine learning models between different car interiors, we formulate the criterion of training in a single vehicle: without access to the target distribution of the vehicle the model would be deployed to, neither with access to multiple vehicles during training. We performed an investigation on the SVIRO dataset for occupant classification on the rear bench and propose an autoencoder based approach to improve the transferability. The autoencoder is on par with commonly used classification models when trained from scratch and sometimes out-performs models pre-trained on a large amount of data. Moreover, the autoencoder can transform images from unknown vehicles into the vehicle it was trained on. These results are corroborated by an evaluation on real infrared images from two vehicle interiors.
Expressiveness of Neural Networks Having Width Equal or Below the Input Dimension
Nov 10, 2020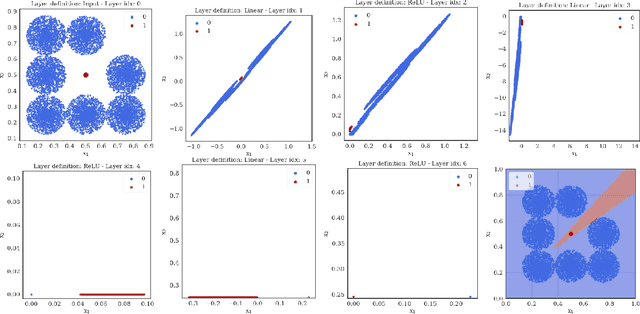
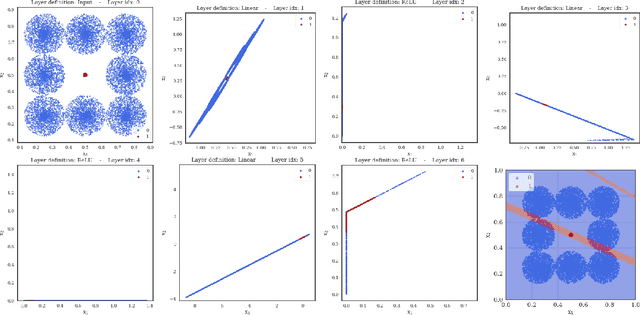
The expressiveness of deep neural networks of bounded width has recently been investigated in a series of articles. The understanding about the minimum width needed to ensure universal approximation for different kind of activation functions has progressively been extended (Park et al., 2020). In particular, it turned out that, with respect to approximation on general compact sets in the input space, a network width less than or equal to the input dimension excludes universal approximation. In this work, we focus on network functions of width less than or equal to the latter critical bound. We prove that in this regime the exact fit of partially constant functions on disjoint compact sets is still possible for ReLU network functions under some conditions on the mutual location of these components. Conversely, we conclude from a maximum principle that for all continuous and monotonic activation functions, universal approximation of arbitrary continuous functions is impossible on sets that coincide with the boundary of an open set plus an inner point of that set. We also show that some network functions of maximum width two, respectively one, allow universal approximation on finite sets.
Illumination Normalization by Partially Impossible Encoder-Decoder Cost Function
Nov 09, 2020
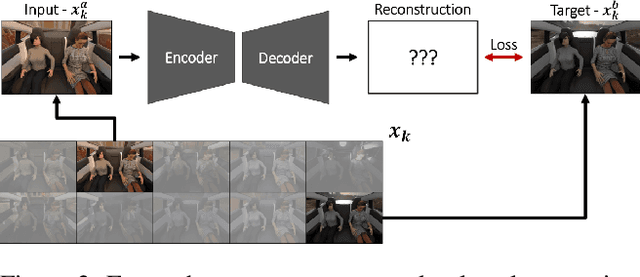
Images recorded during the lifetime of computer vision based systems undergo a wide range of illumination and environmental conditions affecting the reliability of previously trained machine learning models. Image normalization is hence a valuable preprocessing component to enhance the models' robustness. To this end, we introduce a new strategy for the cost function formulation of encoder-decoder networks to average out all the unimportant information in the input images (e.g. environmental features and illumination changes) to focus on the reconstruction of the salient features (e.g. class instances). Our method exploits the availability of identical sceneries under different illumination and environmental conditions for which we formulate a partially impossible reconstruction target: the input image will not convey enough information to reconstruct the target in its entirety. Its applicability is assessed on three publicly available datasets. We combine the triplet loss as a regularizer in the latent space representation and a nearest neighbour search to improve the generalization to unseen illuminations and class instances. The importance of the aforementioned post-processing is highlighted on an automotive application. To this end, we release a synthetic dataset of sceneries from three different passenger compartments where each scenery is rendered under ten different illumination and environmental conditions: see https://sviro.kl.dfki.de
SVIRO: Synthetic Vehicle Interior Rear Seat Occupancy Dataset and Benchmark
Jan 10, 2020
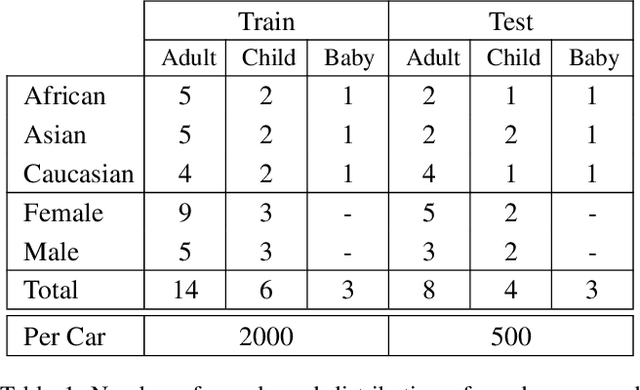


We release SVIRO, a synthetic dataset for sceneries in the passenger compartment of ten different vehicles, in order to analyze machine learning-based approaches for their generalization capacities and reliability when trained on a limited number of variations (e.g. identical backgrounds and textures, few instances per class). This is in contrast to the intrinsically high variability of common benchmark datasets, which focus on improving the state-of-the-art of general tasks. Our dataset contains bounding boxes for object detection, instance segmentation masks, keypoints for pose estimation and depth images for each synthetic scenery as well as images for each individual seat for classification. The advantage of our use-case is twofold: The proximity to a realistic application to benchmark new approaches under novel circumstances while reducing the complexity to a more tractable environment, such that applications and theoretical questions can be tested on a more challenging dataset as toy problems. The data and evaluation server are available under https://sviro.kl.dfki.de.
On decision regions of narrow deep neural networks
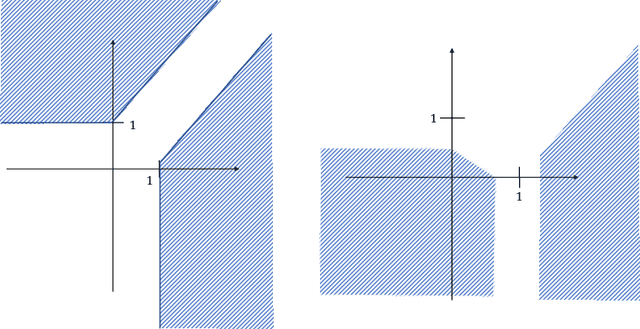
Jul 03, 2018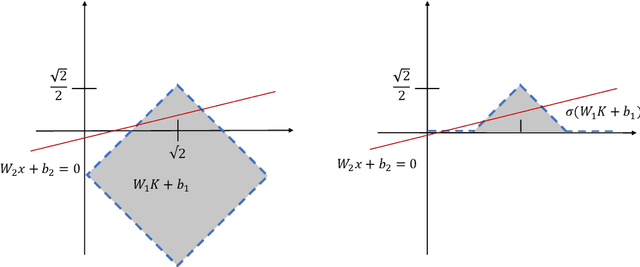


We show that for neural network functions that have width less or equal to the input dimension all connected components of decision regions are unbounded. The result holds for continuous and strictly monotonic activation functions as well as for ReLU activation. This complements recent results on approximation capabilities of [Hanin 2017 Approximating] and connectivity of decision regions of [Nguyen 2018 Neural] for such narrow neural networks. Further, we give an example that negatively answers the question posed in [Nguyen 2018 Neural] whether one of their main results still holds for ReLU activation. Our results are illustrated by means of numerical experiments.