 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEFT: Detection Embeddings for Tracking
Feb 03, 2021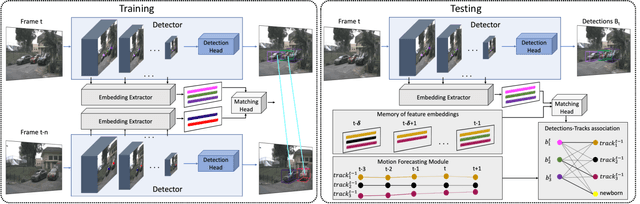
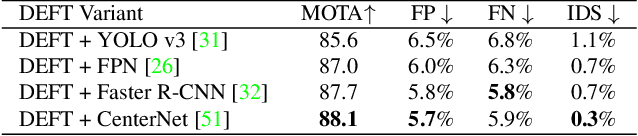

Most modern multiple object tracking (MOT) systems follow the tracking-by-detection paradigm, consisting of a detector followed by a method for associating detections into tracks. There is a long history in tracking of combining motion and appearance features to provide robustness to occlusions and other challenges, but typically this comes with the trade-off of a more complex and slower implementation. Recent successes on popular 2D tracking benchmarks indicate that top-scores can be achieved using a state-of-the-art detector and relatively simple associations relying on single-frame spatial offsets -- notably outperforming contemporary methods that leverage learned appearance features to help re-identify lost tracks. In this paper, we propose an efficient joint detection and tracking model named DEFT, or "Detection Embeddings for Tracking." Our approach relies on an appearance-based object matching network jointly-learned with an underlying object detection network. An LSTM is also added to capture motion constraints. DEFT has comparable accuracy and speed to the top methods on 2D online tracking leaderboards while having significant advantages in robustness when applied to more challenging tracking data. DEFT raises the bar on the nuScenes monocular 3D tracking challenge, more than doubling the performance of the previous top method. Code is publicly available.
End-to-end Learning Improves Static Object Geo-localization in Monocular Video
Apr 10, 2020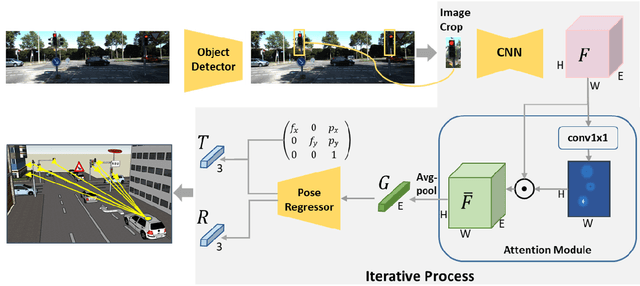
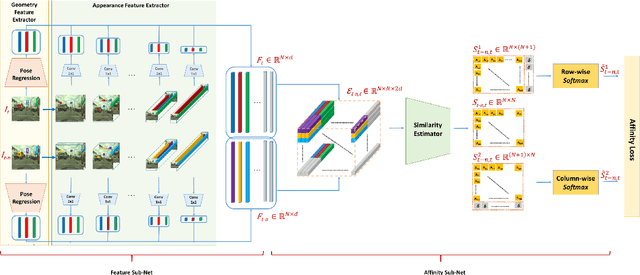
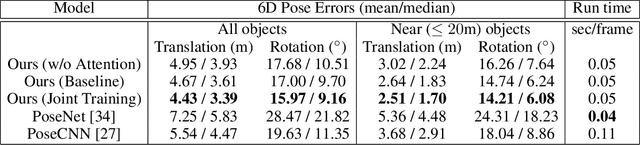
Accurately estimating the position of static objects, such as traffic lights, from the moving camera of a self-driving car is a challenging problem. In this work, we present a system that improves the localization of static objects by jointly-optimizing the components of the system via learning. Our system is comprised of networks that perform: 1) 6DoF object pose estimation from a single image, 2) association of objects between pairs of frames, and 3) multi-object tracking to produce the final geo-localization of the static objects within the scene. We evaluate our approach using a publicly-available data set, focusing on traffic lights due to data availability. For each component, we compare against contemporary alternatives and show significantly-improved performance. We also show that the end-to-end system performance is further improved via joint-training of the constituent models.
Introduction to the Bag of Features Paradigm for Image Classification and Retrieval
Jan 17, 2011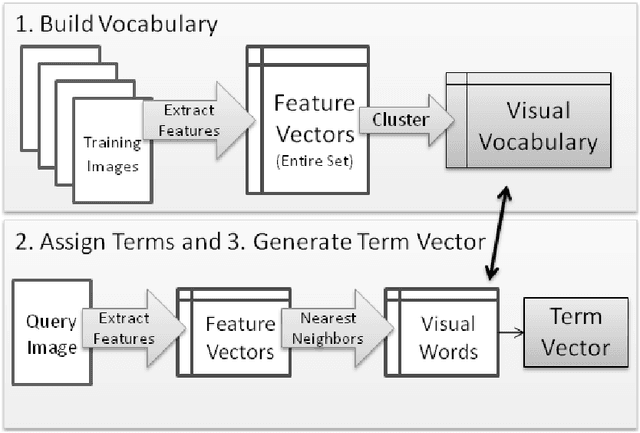
The past decade has seen the growing popularity of Bag of Features (BoF) approaches to many computer vision tasks, including image classification, video search, robot localization, and texture recognition. Part of the appeal is simplicity. BoF methods are based on orderless collections of quantized local image descriptors; they discard spatial information and are therefore conceptually and computationally simpler than many alternative methods. Despite this, or perhaps because of this, BoF-based systems have set new performance standards on popular image classification benchmarks and have achieved scalability breakthroughs in image retrieval. This paper presents an introduction to BoF image representations, describes critical design choices, and surveys the BoF literature. Emphasis is placed on recent techniques that mitigate quantization errors, improve feature detection, and speed up image retrieval. At the same time, unresolved issues and fundamental challenges are raised. Among the unresolved issues are determining the best techniques for sampling images, describing local image features, and evaluating system performance. Among the more fundamental challenges are how and whether BoF methods can contribute to localizing objects in complex images, or to associating high-level semantics with natural images. This survey should be useful both for introducing new investigators to the field and for providing existing researchers with a consolidated reference to related work.
Video Event Recognition for Surveillance Applications (VERSA)
Jul 21, 2010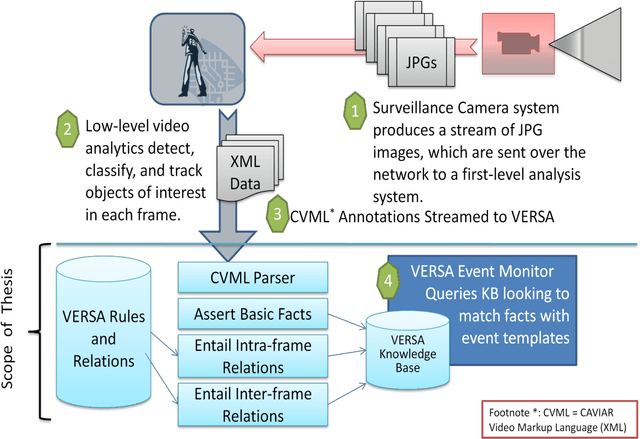


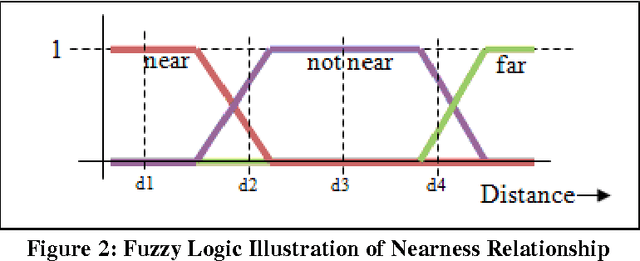
VERSA provides a general-purpose framework for defining and recognizing events in live or recorded surveillance video streams. The approach for event recognition in VERSA is using a declarative logic language to define the spatial and temporal relationships that characterize a given event or activity. Doing so requires the definition of certain fundamental spatial and temporal relationships and a high-level syntax for specifying frame templates and query parameters. Although the handling of uncertainty in the current VERSA implementation is simplistic, the language and architecture is amenable to extending using Fuzzy Logic or similar approaches. VERSA's high-level architecture is designed to work in XML-based, services- oriented environments. VERSA can be thought of as subscribing to the XML annotations streamed by a lower-level video analytics service that provides basic entity detection, labeling, and tracking. One or many VERSA Event Monitors could thus analyze video streams and provide alerts when certain events are detected.