 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold Hypothesis in Data Analysis: Double Geometrically-Probabilistic Approach to Manifold Dimension Estimation
Jul 08, 2021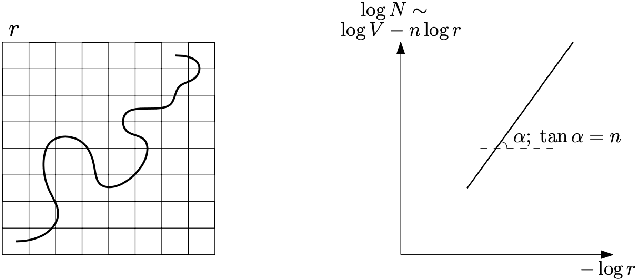
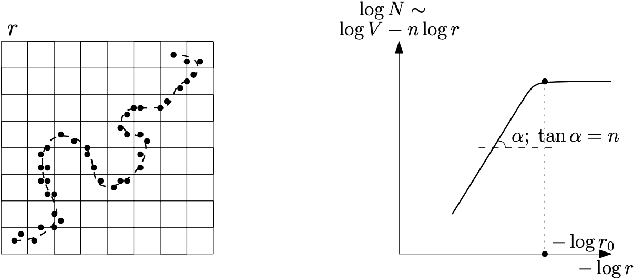

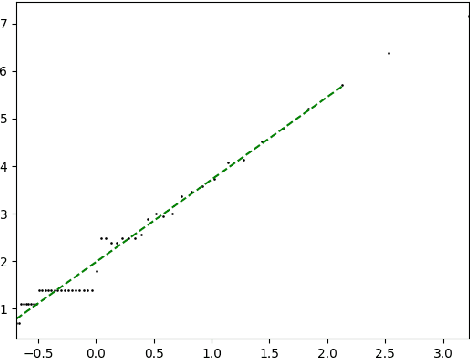
Manifold hypothesis states that data points in high-dimensional space actually lie in close vicinity of a manifold of much lower dimension. In many cases this hypothesis was empirically verified and used to enhance unsupervised and semi-supervised learning. Here we present new approach to manifold hypothesis checking and underlying manifold dimension estimation. In order to do it we use two very different methods simultaneously - one geometric, another probabilistic - and check whether they give the same result. Our geometrical method is a modification for sparse data of a well-known box-counting algorithm for Minkowski dimension calculation. The probabilistic method is new. Although it exploits standard nearest neighborhood distance, it is different from methods which were previously used in such situations. This method is robust, fast and includes special preliminary data transformation. Experiments on real datasets show that the suggested approach based on two methods combination is powerful and effective.
MDMMT: Multidomain Multimodal Transformer for Video Retrieval
Mar 19, 2021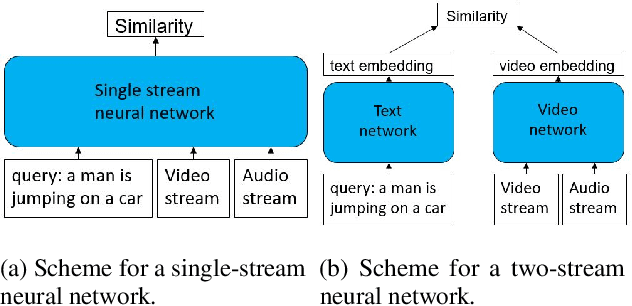
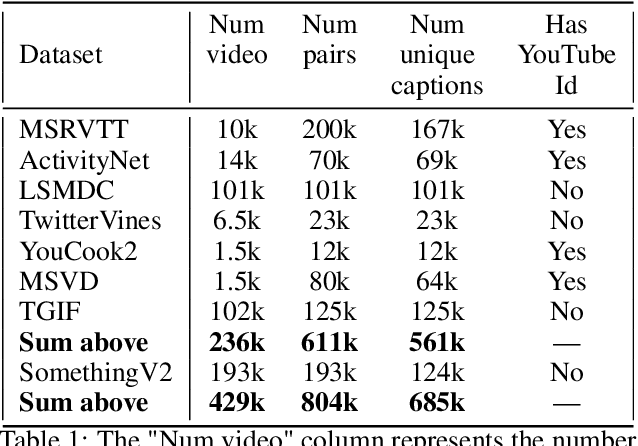
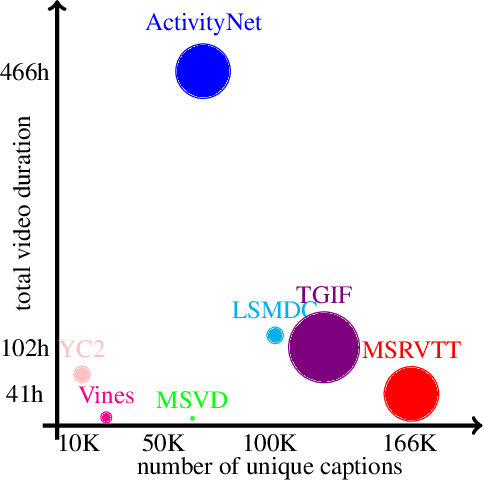

We present a new state-of-the-art on the text to video retrieval task on MSRVTT and LSMDC benchmarks where our model outperforms all previous solutions by a large margin. Moreover, state-of-the-art results are achieved with a single model on two datasets without finetuning. This multidomain generalisation is achieved by a proper combination of different video caption datasets. We show that training on different datasets can improve test results of each other. Additionally we check intersection between many popular datasets and found that MSRVTT has a significant overlap between the test and the train parts, and the same situation is observed for ActivityNet.
Mutual Modality Learning for Video Action Classification
Nov 04, 2020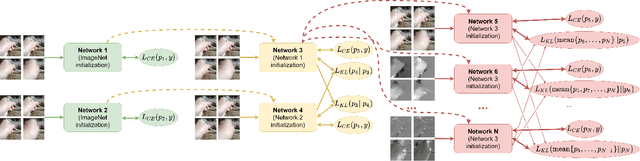
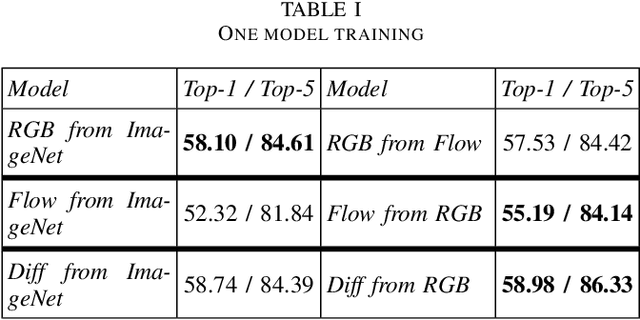
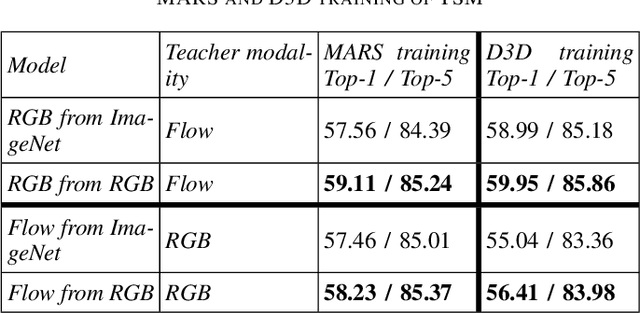

The construction of models for video action classification progresses rapidly. However, the performance of those models can still be easily improved by ensembling with the same models trained on different modalities (e.g. Optical flow). Unfortunately, it is computationally expensive to use several modalities during inference. Recent works examine the ways to integrate advantages of multi-modality into a single RGB-model. Yet, there is still a room for improvement. In this paper, we explore the various methods to embed the ensemble power into a single model. We show that proper initialization, as well as mutual modality learning, enhances single-modality models. As a result, we achieve state-of-the-art results in the Something-Something-v2 benchmark.
AdvHat: Real-world adversarial attack on ArcFace Face ID system
Aug 23, 2019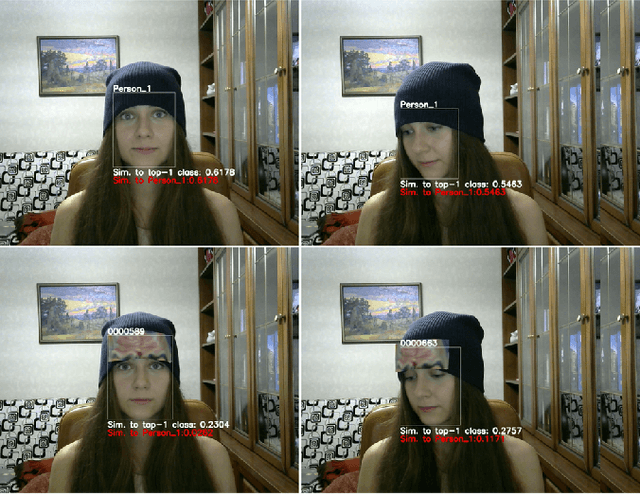



In this paper we propose a novel easily reproducible technique to attack the best public Face ID system ArcFace in different shooting conditions. To create an attack, we print the rectangular paper sticker on a common color printer and put it on the hat. The adversarial sticker is prepared with a novel algorithm for off-plane transformations of the image which imitates sticker location on the hat. Such an approach confuses the state-of-the-art public Face ID model LResNet100E-IR, ArcFace@ms1m-refine-v2 and is transferable to other Face ID models.