 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLRM: Vision-Language Models act as Reward Models for Image Captioning
Apr 02, 2024
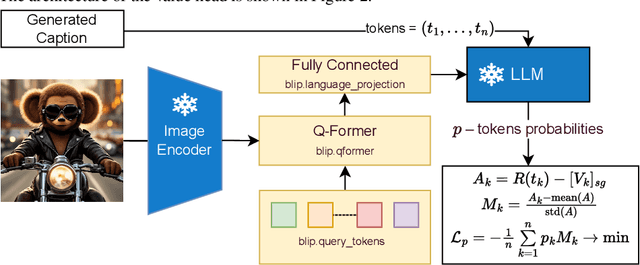
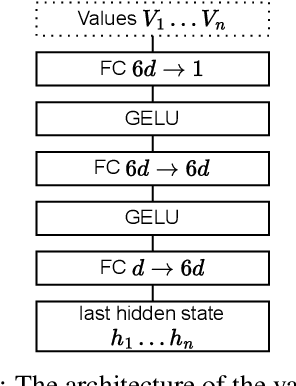
In this work, we present an unsupervised method for enhancing an image captioning model (in our case, BLIP2) using reinforcement learning and vision-language models like CLIP and BLIP2-ITM as reward models. The RL-tuned model is able to generate longer and more comprehensive descriptions. Our model reaches impressive 0.90 R@1 CLIP Recall score on MS-COCO Carpathy Test Split. Weights are available at https://huggingface.co/sashakunitsyn/vlrm-blip2-opt-2.7b.
MDMMT-2: Multidomain Multimodal Transformer for Video Retrieval, One More Step Towards Generalization
Mar 14, 2022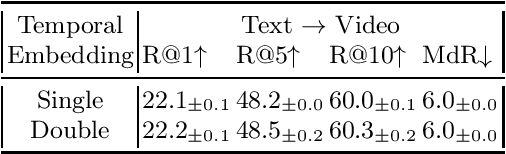
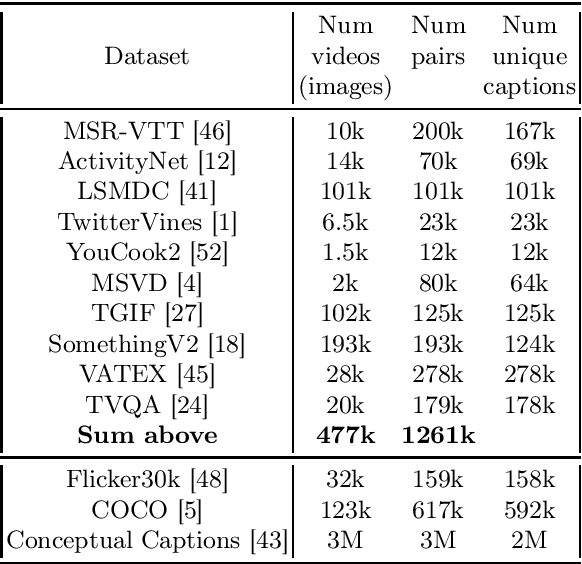


In this work we present a new State-of-The-Art on the text-to-video retrieval task on MSR-VTT, LSMDC, MSVD, YouCook2 and TGIF obtained by a single model. Three different data sources are combined: weakly-supervised videos, crowd-labeled text-image pairs and text-video pairs. A careful analysis of available pre-trained networks helps to choose the best prior-knowledge ones. We introduce three-stage training procedure that provides high transfer knowledge efficiency and allows to use noisy datasets during training without prior knowledge degradation. Additionally, double positional encoding is used for better fusion of different modalities and a simple method for non-square inputs processing is suggested.
MDMMT: Multidomain Multimodal Transformer for Video Retrieval
Mar 19, 2021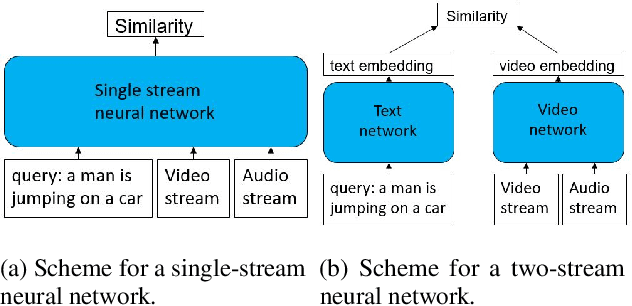
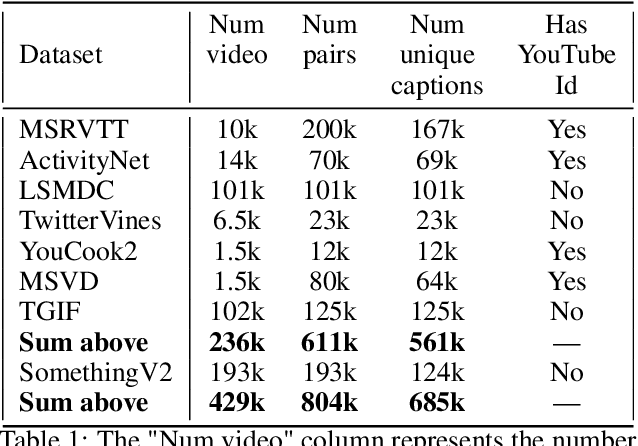
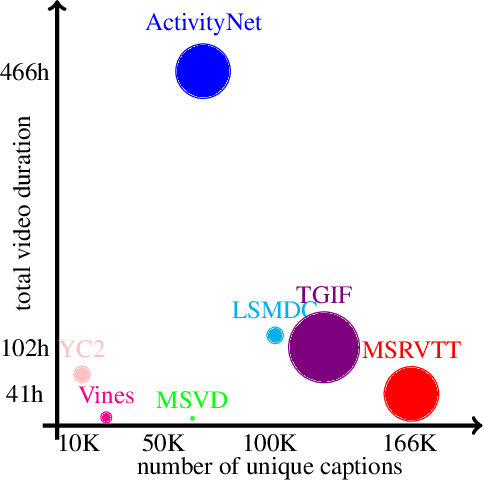

We present a new state-of-the-art on the text to video retrieval task on MSRVTT and LSMDC benchmarks where our model outperforms all previous solutions by a large margin. Moreover, state-of-the-art results are achieved with a single model on two datasets without finetuning. This multidomain generalisation is achieved by a proper combination of different video caption datasets. We show that training on different datasets can improve test results of each other. Additionally we check intersection between many popular datasets and found that MSRVTT has a significant overlap between the test and the train parts, and the same situation is observed for ActivityNet.
Mutual Modality Learning for Video Action Classification
Nov 04, 2020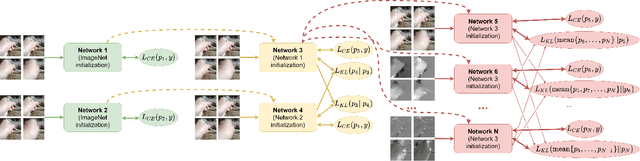
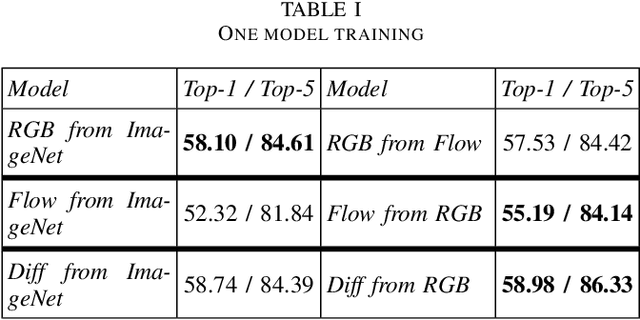
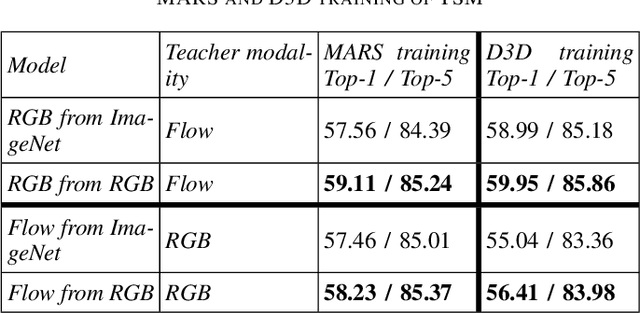

The construction of models for video action classification progresses rapidly. However, the performance of those models can still be easily improved by ensembling with the same models trained on different modalities (e.g. Optical flow). Unfortunately, it is computationally expensive to use several modalities during inference. Recent works examine the ways to integrate advantages of multi-modality into a single RGB-model. Yet, there is still a room for improvement. In this paper, we explore the various methods to embed the ensemble power into a single model. We show that proper initialization, as well as mutual modality learning, enhances single-modality models. As a result, we achieve state-of-the-art results in the Something-Something-v2 benchmark.