Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLRM: Vision-Language Models act as Reward Models for Image Captioning
Paper and Code
Apr 02, 2024
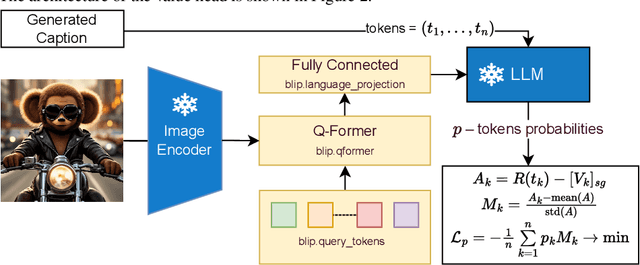
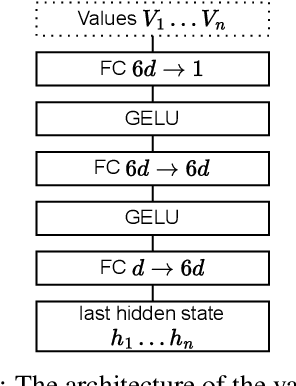
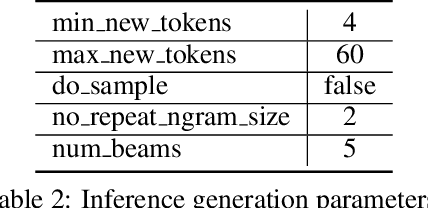
In this work, we present an unsupervised method for enhancing an image captioning model (in our case, BLIP2) using reinforcement learning and vision-language models like CLIP and BLIP2-ITM as reward models. The RL-tuned model is able to generate longer and more comprehensive descriptions. Our model reaches impressive 0.90 R@1 CLIP Recall score on MS-COCO Carpathy Test Split. Weights are available at https://huggingface.co/sashakunitsyn/vlrm-blip2-opt-2.7b.
View paper on