Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDMMT-2: Multidomain Multimodal Transformer for Video Retrieval, One More Step Towards Generalization
Paper and Code
Mar 14, 2022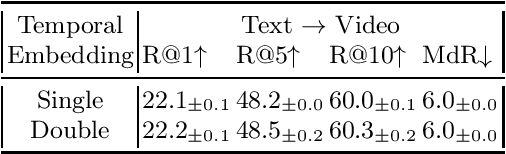
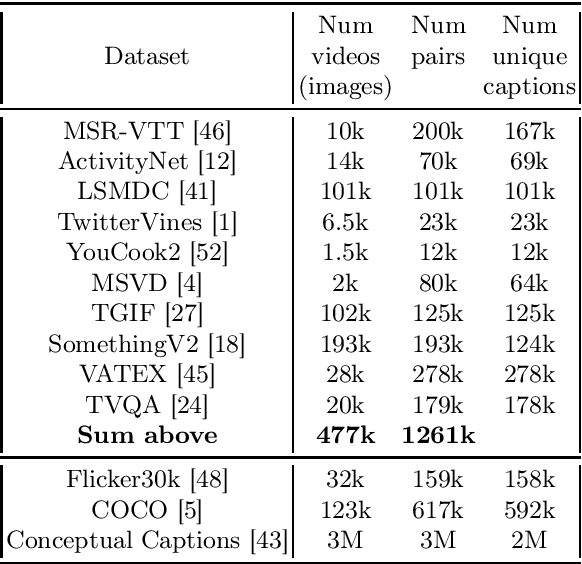


In this work we present a new State-of-The-Art on the text-to-video retrieval task on MSR-VTT, LSMDC, MSVD, YouCook2 and TGIF obtained by a single model. Three different data sources are combined: weakly-supervised videos, crowd-labeled text-image pairs and text-video pairs. A careful analysis of available pre-trained networks helps to choose the best prior-knowledge ones. We introduce three-stage training procedure that provides high transfer knowledge efficiency and allows to use noisy datasets during training without prior knowledge degradation. Additionally, double positional encoding is used for better fusion of different modalities and a simple method for non-square inputs processing is suggested.
View paper on