 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Gut Microbiome Metaomic data: A preliminary work
Jun 28, 2024

The gut microbiome, crucial for human health, presents challenges in analyzing its complex metaomic data due to high dimensionality and sparsity. Traditional methods struggle to capture its intricate relationships. We investigate graph neural networks (GNNs) for this task, aiming to derive meaningful representations of individual gut microbiomes. Unlike methods relying solely on taxa abundance, we directly leverage phylogenetic relationships, in order to obtain a generalized encoder for taxa networks. The representation learnt from the encoder are then used to train a model for phenotype prediction such as Inflammatory Bowel Disease (IBD).
Structural Positional Encoding for knowledge integration in transformer-based medical process monitoring
Mar 13, 2024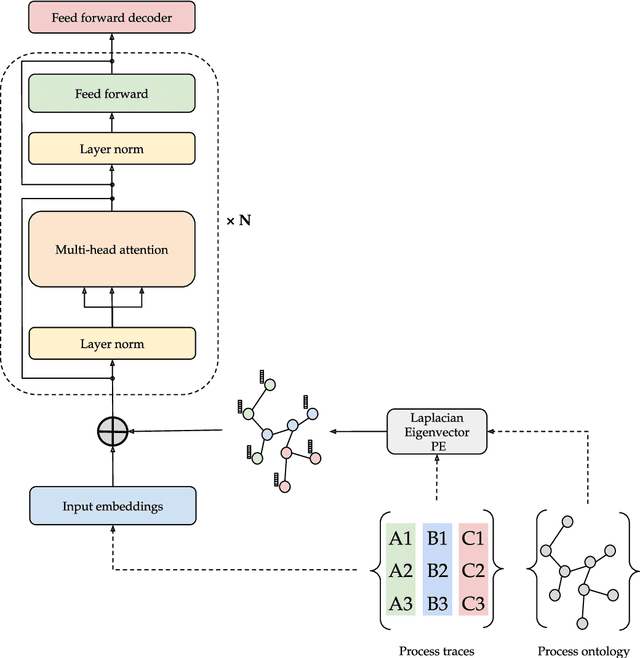



Predictive process monitoring is a process mining task aimed at forecasting information about a running process trace, such as the most correct next activity to be executed. In medical domains, predictive process monitoring can provide valuable decision support in atypical and nontrivial situations. Decision support and quality assessment in medicine cannot ignore domain knowledge, in order to be grounded on all the available information (which is not limited to data) and to be really acceptable by end users. In this paper, we propose a predictive process monitoring approach relying on the use of a {\em transformer}, a deep learning architecture based on the attention mechanism. A major contribution of our work lies in the incorporation of ontological domain-specific knowledge, carried out through a graph positional encoding technique. The paper presents and discusses the encouraging experimental result we are collecting in the domain of stroke management.
Towards an educational tool for supporting neonatologists in the delivery room
Mar 11, 2024Nowadays, there is evidence that several factors may increase the risk, for an infant, to require stabilisation or resuscitation manoeuvres at birth. However, this risk factors are not completely known, and a universally applicable model for predicting high-risk situations is not available yet. Considering both these limitations and the fact that the need for resuscitation at birth is a rare event, periodic training of the healthcare personnel responsible for newborn caring in the delivery room is mandatory. In this paper, we propose a machine learning approach for identifying risk factors and their impact on the birth event from real data, which can be used by personnel to progressively increase and update their knowledge. Our final goal will be the one of designing a user-friendly mobile application, able to improve the recognition rate and the planning of the appropriate interventions on high-risk patients.
Parametric Dependability Analysis through Probabilistic Horn Abduction
Oct 19, 2012
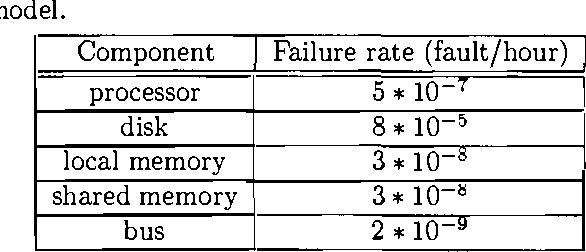
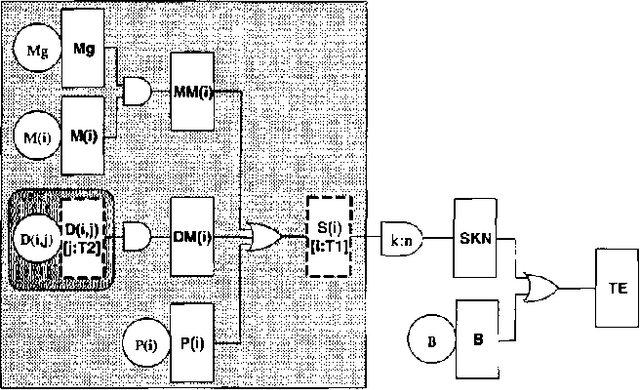
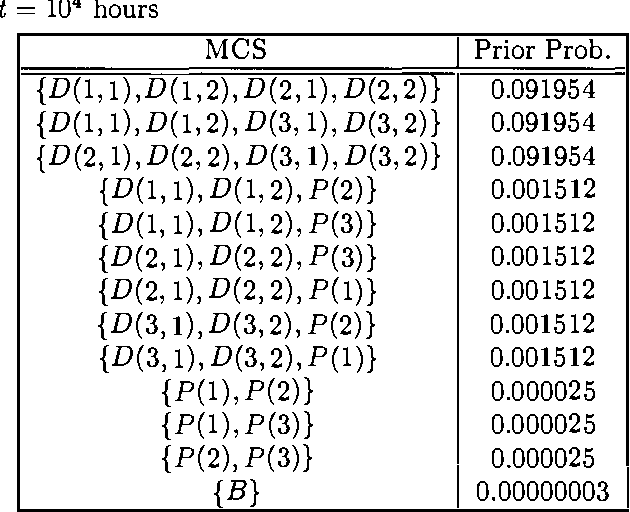
Dependability modeling and evaluation is aimed at investigating that a system performs its function correctly in time. A usual way to achieve a high reliability, is to design redundant systems that contain several replicas of the same subsystem or component. State space methods for dependability analysis may suffer of the state space explosion problem in such a kind of situation. Combinatorial models, on the other hand, require the simplified assumption of statistical independence; however, in case of redundant systems, this does not guarantee a reduced number of modeled elements. In order to provide a more compact system representation, parametric system modeling has been investigated in the literature, in such a way that a set of replicas of a given subsystem is parameterized so that only one representative instance is explicitly included. While modeling aspects can be suitably addressed by these approaches, analytical tools working on parametric characterizations are often more difficult to be defined and the standard approach is to 'unfold' the parametric model, in order to exploit standard analysis algorithms working at the unfolded 'ground' level. Moreover, parameterized combinatorial methods still require the statistical independence assumption. In the present paper we consider the formalism of Parametric Fault Tree (PFT) and we show how it can be related to Probabilistic Horn Abduction (PHA). Since PHA is a framework where both modeling and analysis can be performed in a restricted first-order language, we aim at showing that converting a PFT into a PHA knowledge base will allow an approach to dependability analysis directly exploiting parametric representation. We will show that classical qualitative and quantitative dependability measures can be characterized within PHA. Furthermore, additional modeling aspects (such as noisy gates and local dependencies) as well as additional reliability measures (such as posterior probability analysis) can be naturally addressed by this conversion. A simple example of a multi-processor system with several replicated units is used to illustrate the approach.