 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Labels: A Self-Supervised Framework with Masked Autoencoders and Random Cropping for Breast Cancer Subtype Classification
Oct 15, 2024


This work contributes to breast cancer sub-type classification using histopathological images. We utilize masked autoencoders (MAEs) to learn a self-supervised embedding tailored for computer vision tasks in this domain. This embedding captures informative representations of histopathological data, facilitating feature learning without extensive labeled datasets. During pre-training, we investigate employing a random crop technique to generate a large dataset from WSIs automatically. Additionally, we assess the performance of linear probes for multi-class classification tasks of cancer sub-types using the representations learnt by the MAE. Our approach aims to achieve strong performance on downstream tasks by leveraging the complementary strengths of ViTs and autoencoders. We evaluate our model's performance on the BRACS dataset and compare it with existing benchmarks.
Graph Neural Networks for Gut Microbiome Metaomic data: A preliminary work
Jun 28, 2024

The gut microbiome, crucial for human health, presents challenges in analyzing its complex metaomic data due to high dimensionality and sparsity. Traditional methods struggle to capture its intricate relationships. We investigate graph neural networks (GNNs) for this task, aiming to derive meaningful representations of individual gut microbiomes. Unlike methods relying solely on taxa abundance, we directly leverage phylogenetic relationships, in order to obtain a generalized encoder for taxa networks. The representation learnt from the encoder are then used to train a model for phenotype prediction such as Inflammatory Bowel Disease (IBD).
Approaching Adaptation Guided Retrieval in Case-Based Reasoning through Inference in Undirected Graphical Models
May 29, 2019
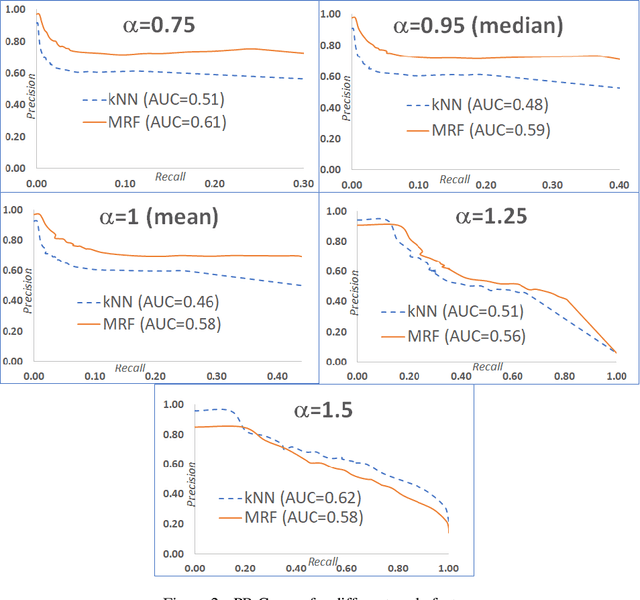


In Case-Based Reasoning, when the similarity assumption does not hold, the retrieval of a set of cases structurally similar to the query does not guarantee to get a reusable or revisable solution. Knowledge about the adaptability of solutions has to be exploited, in order to define a method for adaptation-guided retrieval. We propose a novel approach to address this problem, where knowledge about the adaptability of the solutions is captured inside a metric Markov Random Field (MRF). Nodes of the MRF represent cases and edges connect nodes whose solutions are close in the solution space. States of the nodes represent different adaptation levels with respect to the potential query. Metric-based potentials enforce connected nodes to share the same state, since cases having similar solutions should have the same adaptability level with respect to the query. The main goal is to enlarge the set of potentially adaptable cases that are retrieved without significantly sacrificing the precision and accuracy of retrieval. We will report on some experiments concerning a retrieval architecture where a simple kNN retrieval (on the problem description) is followed by a further retrieval step based on MRF inference.
Modeling Uncertain Temporal Evolutions in Model-Based Diagnosis
Mar 13, 2013
Although the notion of diagnostic problem has been extensively investigated in the context of static systems, in most practical applications the behavior of the modeled system is significantly variable during time. The goal of the paper is to propose a novel approach to the modeling of uncertainty about temporal evolutions of time-varying systems and a characterization of model-based temporal diagnosis. Since in most real world cases knowledge about the temporal evolution of the system to be diagnosed is uncertain, we consider the case when probabilistic temporal knowledge is available for each component of the system and we choose to model it by means of Markov chains. In fact, we aim at exploiting the statistical assumptions underlying reliability theory in the context of the diagnosis of timevarying systems. We finally show how to exploit Markov chain theory in order to discard, in the diagnostic process, very unlikely diagnoses.
Bayesian Networks for Dependability Analysis: an Application to Digital Control Reliability
Jan 23, 2013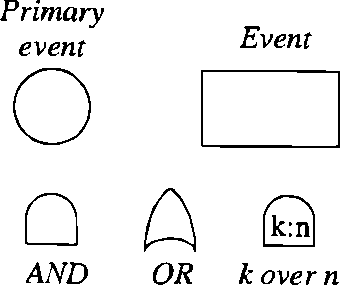

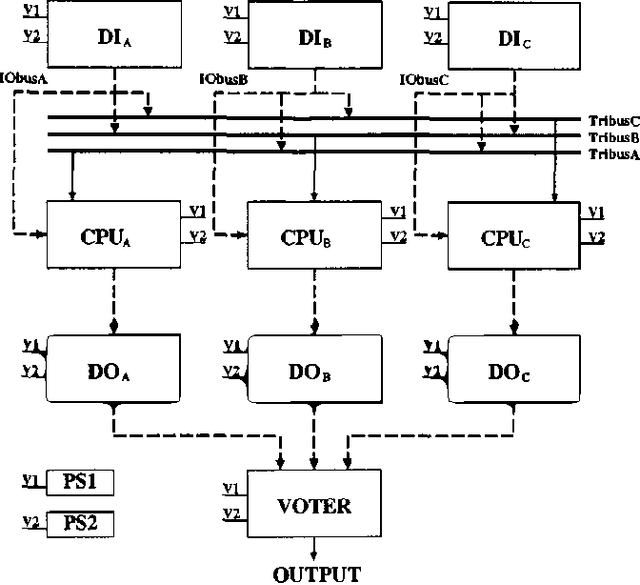
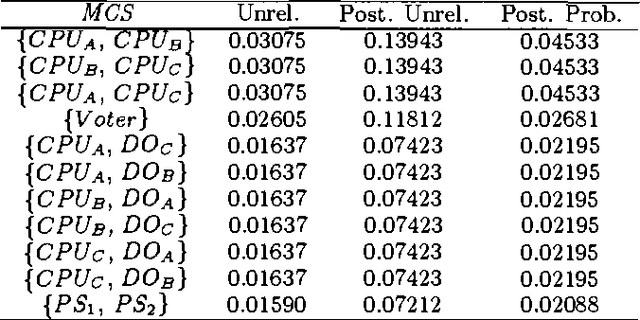
Bayesian Networks (BN) provide robust probabilistic methods of reasoning under uncertainty, but despite their formal grounds are strictly based on the notion of conditional dependence, not much attention has been paid so far to their use in dependability analysis. The aim of this paper is to propose BN as a suitable tool for dependability analysis, by challenging the formalism with basic issues arising in dependability tasks. We will discuss how both modeling and analysis issues can be naturally dealt with by BN. Moreover, we will show how some limitations intrinsic to combinatorial dependability methods such as Fault Trees can be overcome using BN. This will be pursued through the study of a real-world example concerning the reliability analysis of a redundant digital Programmable Logic Controller (PLC) with majority voting 2:3
Parametric Dependability Analysis through Probabilistic Horn Abduction
Oct 19, 2012
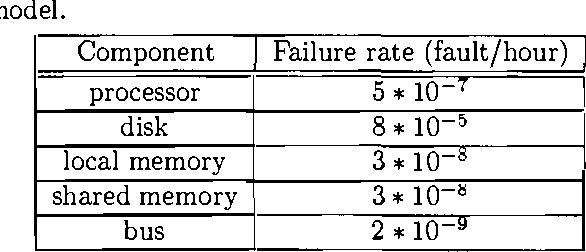
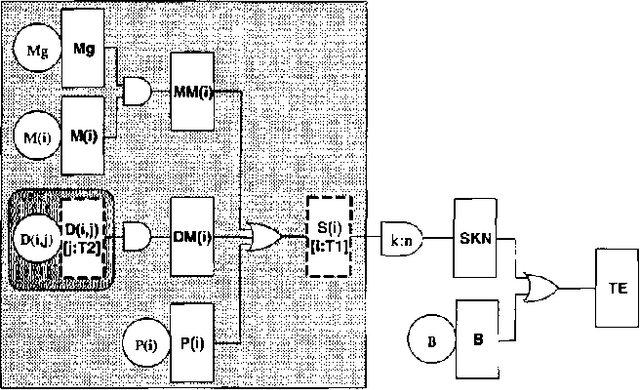
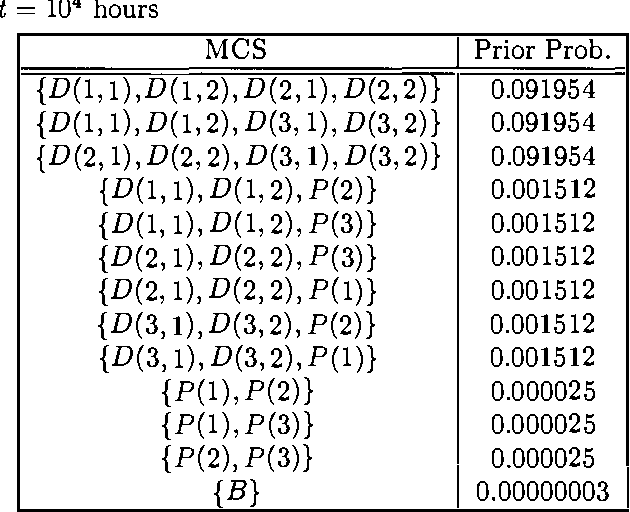
Dependability modeling and evaluation is aimed at investigating that a system performs its function correctly in time. A usual way to achieve a high reliability, is to design redundant systems that contain several replicas of the same subsystem or component. State space methods for dependability analysis may suffer of the state space explosion problem in such a kind of situation. Combinatorial models, on the other hand, require the simplified assumption of statistical independence; however, in case of redundant systems, this does not guarantee a reduced number of modeled elements. In order to provide a more compact system representation, parametric system modeling has been investigated in the literature, in such a way that a set of replicas of a given subsystem is parameterized so that only one representative instance is explicitly included. While modeling aspects can be suitably addressed by these approaches, analytical tools working on parametric characterizations are often more difficult to be defined and the standard approach is to 'unfold' the parametric model, in order to exploit standard analysis algorithms working at the unfolded 'ground' level. Moreover, parameterized combinatorial methods still require the statistical independence assumption. In the present paper we consider the formalism of Parametric Fault Tree (PFT) and we show how it can be related to Probabilistic Horn Abduction (PHA). Since PHA is a framework where both modeling and analysis can be performed in a restricted first-order language, we aim at showing that converting a PFT into a PHA knowledge base will allow an approach to dependability analysis directly exploiting parametric representation. We will show that classical qualitative and quantitative dependability measures can be characterized within PHA. Furthermore, additional modeling aspects (such as noisy gates and local dependencies) as well as additional reliability measures (such as posterior probability analysis) can be naturally addressed by this conversion. A simple example of a multi-processor system with several replicated units is used to illustrate the approach.