 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe impact of deep learning aid on the workload and interpretation accuracy of radiologists on chest computed tomography: a cross-over reader study
Jun 12, 2024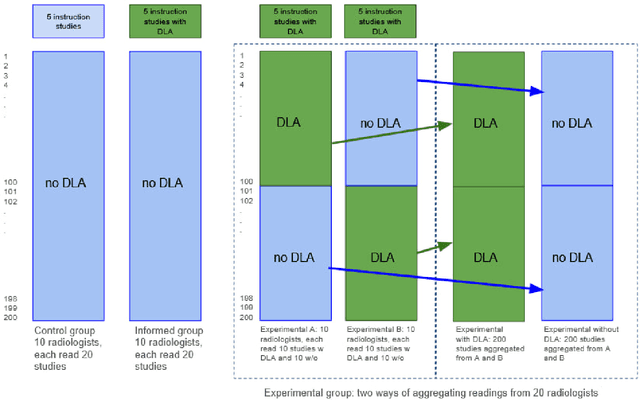
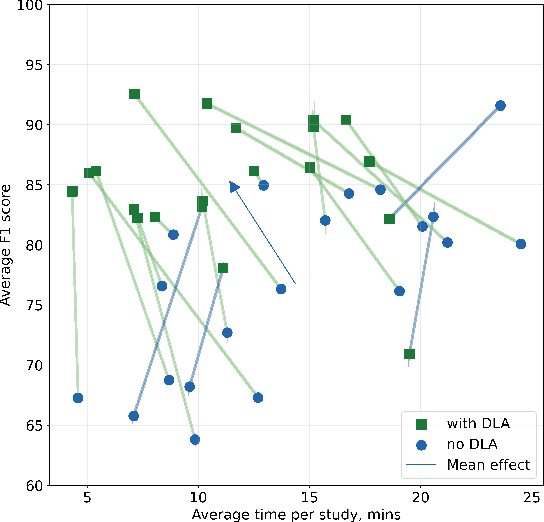
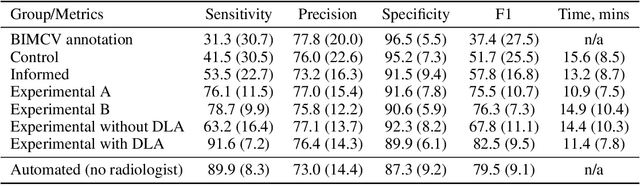
Interpretation of chest computed tomography (CT) is time-consuming. Previous studies have measured the time-saving effect of using a deep-learning-based aid (DLA) for CT interpretation. We evaluated the joint impact of a multi-pathology DLA on the time and accuracy of radiologists' reading. 40 radiologists were randomly split into three experimental arms: control (10), who interpret studies without assistance; informed group (10), who were briefed about DLA pathologies, but performed readings without it; and the experimental group (20), who interpreted half studies with DLA, and half without. Every arm used the same 200 CT studies retrospectively collected from BIMCV-COVID19 dataset; each radiologist provided readings for 20 CT studies. We compared interpretation time, and accuracy of participants diagnostic report with respect to 12 pathological findings. Mean reading time per study was 15.6 minutes [SD 8.5] in the control arm, 13.2 minutes [SD 8.7] in the informed arm, 14.4 [SD 10.3] in the experimental arm without DLA, and 11.4 minutes [SD 7.8] in the experimental arm with DLA. Mean sensitivity and specificity were 41.5 [SD 30.4], 86.8 [SD 28.3] in the control arm; 53.5 [SD 22.7], 92.3 [SD 9.4] in the informed non-assisted arm; 63.2 [SD 16.4], 92.3 [SD 8.2] in the experimental arm without DLA; and 91.6 [SD 7.2], 89.9 [SD 6.0] in the experimental arm with DLA. DLA speed up interpretation time per study by 2.9 minutes (CI95 [1.7, 4.3], p<0.0005), increased sensitivity by 28.4 (CI95 [23.4, 33.4], p<0.0005), and decreased specificity by 2.4 (CI95 [0.6, 4.3], p=0.13). Of 20 radiologists in the experimental arm, 16 have improved reading time and sensitivity, two improved their time with a marginal drop in sensitivity, and two participants improved sensitivity with increased time. Overall, DLA introduction decreased reading time by 20.6%.
Adaptation to CT Reconstruction Kernels by Enforcing Cross-domain Feature Maps Consistency
Mar 28, 2022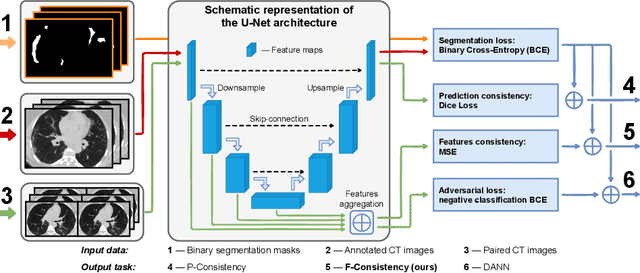
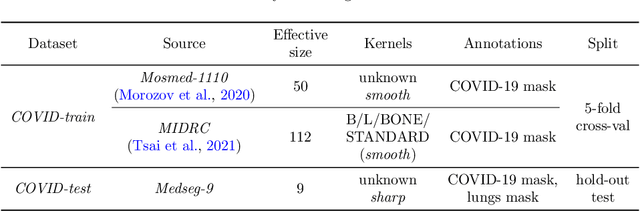

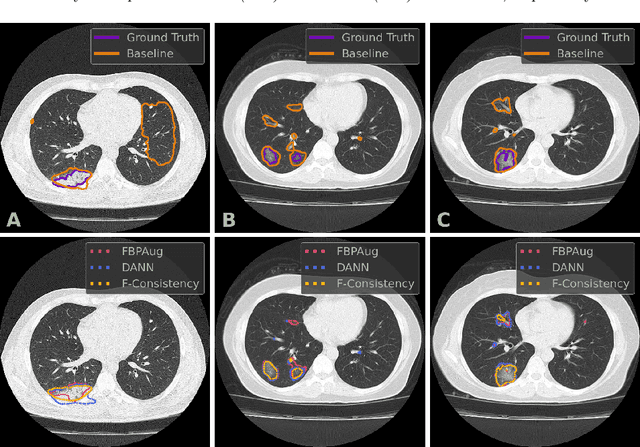
Deep learning methods provide significant assistance in analyzing coronavirus disease (COVID-19) in chest computed tomography (CT) images, including identification, severity assessment, and segmentation. Although the earlier developed methods address the lack of data and specific annotations, the current goal is to build a robust algorithm for clinical use, having a larger pool of available data. With the larger datasets, the domain shift problem arises, affecting the performance of methods on the unseen data. One of the critical sources of domain shift in CT images is the difference in reconstruction kernels used to generate images from the raw data (sinograms). In this paper, we show a decrease in the COVID-19 segmentation quality of the model trained on the smooth and tested on the sharp reconstruction kernels. Furthermore, we compare several domain adaptation approaches to tackle the problem, such as task-specific augmentation and unsupervised adversarial learning. Finally, we propose the unsupervised adaptation method, called F-Consistency, that outperforms the previous approaches. Our method exploits a set of unlabeled CT image pairs which differ only in reconstruction kernels within every pair. It enforces the similarity of the network hidden representations (feature maps) by minimizing mean squared error (MSE) between paired feature maps. We show our method achieving 0.64 Dice Score on the test dataset with unseen sharp kernels, compared to the 0.56 Dice Score of the baseline model. Moreover, F-Consistency scores 0.80 Dice Score between predictions on the paired images, which almost doubles the baseline score of 0.46 and surpasses the other methods. We also show F-Consistency to better generalize on the unseen kernels and without the specific semantic content, e.g., presence of the COVID-19 lesions.