 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Causal Effects with the Neural Autoregressive Density Estimator
Aug 17, 2020



Estimation of causal effects is fundamental in situations were the underlying system will be subject to active interventions. Part of building a causal inference engine is defining how variables relate to each other, that is, defining the functional relationship between variables given conditional dependencies. In this paper, we deviate from the common assumption of linear relationships in causal models by making use of neural autoregressive density estimators and use them to estimate causal effects within the Pearl's do-calculus framework. Using synthetic data, we show that the approach can retrieve causal effects from non-linear systems without explicitly modeling the interactions between the variables.
Prediction of rare feature combinations in population synthesis: Application of deep generative modelling
Sep 17, 2019



In population synthesis applications, when considering populations with many attributes, a fundamental problem is the estimation of rare combinations of feature attributes. Unsurprisingly, it is notably more difficult to reliably representthe sparser regions of such multivariate distributions and in particular combinations of attributes which are absent from the original sample. In the literature this is commonly known as sampling zeros for which no systematic solution has been proposed so far. In this paper, two machine learning algorithms, from the family of deep generative models,are proposed for the problem of population synthesis and with particular attention to the problem of sampling zeros. Specifically, we introduce the Wasserstein Generative Adversarial Network (WGAN) and the Variational Autoencoder(VAE), and adapt these algorithms for a large-scale population synthesis application. The models are implemented on a Danish travel survey with a feature-space of more than 60 variables. The models are validated in a cross-validation scheme and a set of new metrics for the evaluation of the sampling-zero problem is proposed. Results show how these models are able to recover sampling zeros while keeping the estimation of truly impossible combinations, the structural zeros, at a comparatively low level. Particularly, for a low dimensional experiment, the VAE, the marginal sampler and the fully random sampler generate 5%, 21% and 26%, respectively, more structural zeros per sampling zero generated by the WGAN, while for a high dimensional case, these figures escalate to 44%, 2217% and 170440%, respectively. This research directly supports the development of agent-based systems and in particular cases where detailed socio-economic or geographical representations are required.
Introducing Super Pseudo Panels: Application to Transport Preference Dynamics
Mar 01, 2019



We propose a new approach for constructing synthetic pseudo-panel data from cross-sectional data. The pseudo panel and the preferences it intends to describe is constructed at the individual level and is not affected by aggregation bias across cohorts. This is accomplished by creating a high-dimensional probabilistic model representation of the entire data set, which allows sampling from the probabilistic model in such a way that all of the intrinsic correlation properties of the original data are preserved. The key to this is the use of deep learning algorithms based on the Conditional Variational Autoencoder (CVAE) framework. From a modelling perspective, the concept of a model-based resampling creates a number of opportunities in that data can be organized and constructed to serve very specific needs of which the forming of heterogeneous pseudo panels represents one. The advantage, in that respect, is the ability to trade a serious aggregation bias (when aggregating into cohorts) for an unsystematic noise disturbance. Moreover, the approach makes it possible to explore high-dimensional sparse preference distributions and their linkage to individual specific characteristics, which is not possible if applying traditional pseudo-panel methods. We use the presented approach to reveal the dynamics of transport preferences for a fixed pseudo panel of individuals based on a large Danish cross-sectional data set covering the period from 2006 to 2016. The model is also utilized to classify individuals into 'slow' and 'fast' movers with respect to the speed at which their preferences change over time. It is found that the prototypical fast mover is a young woman who lives as a single in a large city whereas the typical slow mover is a middle-aged man with high income from a nuclear family who lives in a detached house outside a city.
A Bayesian Additive Model for Understanding Public Transport Usage in Special Events
Dec 20, 2018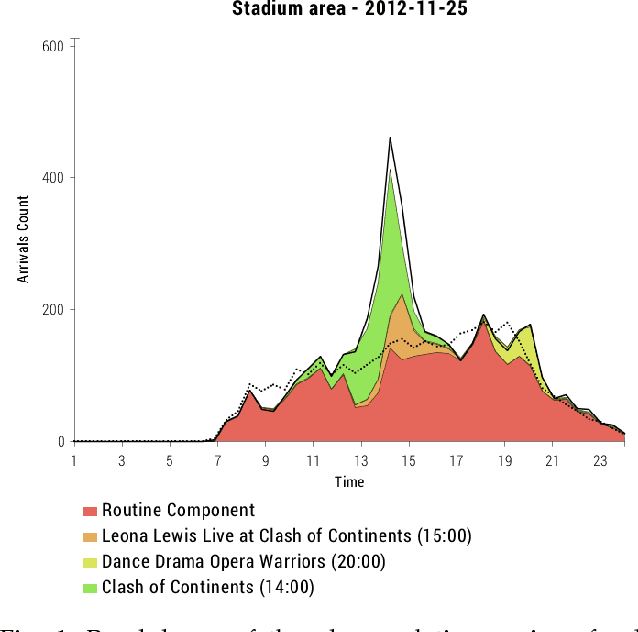


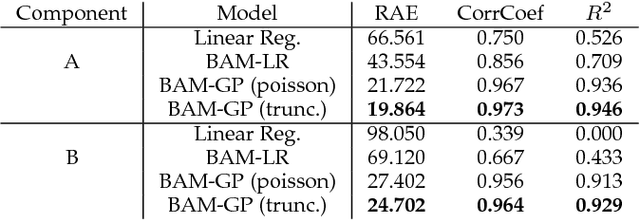
Public special events, like sports games, concerts and festivals are well known to create disruptions in transportation systems, often catching the operators by surprise. Although these are usually planned well in advance, their impact is difficult to predict, even when organisers and transportation operators coordinate. The problem highly increases when several events happen concurrently. To solve these problems, costly processes, heavily reliant on manual search and personal experience, are usual practice in large cities like Singapore, London or Tokyo. This paper presents a Bayesian additive model with Gaussian process components that combines smart card records from public transport with context information about events that is continuously mined from the Web. We develop an efficient approximate inference algorithm using expectation propagation, which allows us to predict the total number of public transportation trips to the special event areas, thereby contributing to a more adaptive transportation system. Furthermore, for multiple concurrent event scenarios, the proposed algorithm is able to disaggregate gross trip counts into their most likely components related to specific events and routine behavior. Using real data from Singapore, we show that the presented model outperforms the best baseline model by up to 26% in R2 and also has explanatory power for its individual components.
* 14 pages, IEEE Transactions on Pattern Analysis and Machine Intelligence (Volume: 39 , Issue: 11 , Nov. 1 2017)
Band gap prediction for large organic crystal structures with machine learning
Oct 30, 2018

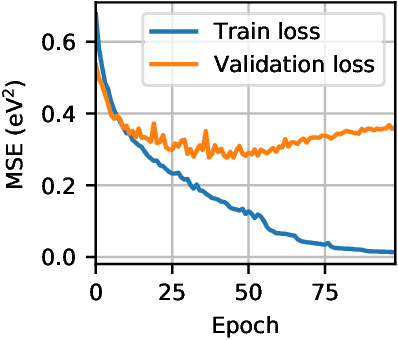

Machine learning models are capable of capturing the structure-property relationship from a dataset of computationally demanding ab initio calculations. In fact, machine learning models have reached chemical accuracy on small organic molecules contained in the popular QM9 dataset. At the same time, the domain of large crystal structures remains rather unexplored. Over the past two years, the Organic Materials Database (OMDB) has hosted a growing number of electronic properties of previously synthesized organic crystal structures. The complexity of the organic crystals contained within the OMDB, which have on average 85 atoms per unit cell, makes this database a challenging platform for machine learning applications. In this paper, we focus on predicting the band gap which represents one of the basic properties of a crystalline material. With this aim, we release a consistent dataset of 12500 crystal structures and their corresponding DFT band gap freely available for download at https://omdb.diracmaterials.org/dataset. We run two recent machine learning models, kernel ridge regression with the Smooth Overlap of Atomic Positions (SOAP) kernel and the deep learning model SchNet, on this new dataset and find that an ensemble of these two models reaches mean absolute error (MAE) of 0.361 eV, which corresponds to a percentage error of 12% on the average band gap of 3.03 eV. The models also provide chemical insights into the data. For example, by visualizing the SOAP kernel similarity between the crystals, different clusters of materials can be identified, such as organic metals or semiconductors. Finally, the trained models are employed to predict the band gap for 260092 materials contained within the Crystallography Open Database (COD) and made available online so the predictions can be obtained for any arbitrary crystal structure uploaded by a user.
Scalable Population Synthesis with Deep Generative Modeling
Aug 21, 2018

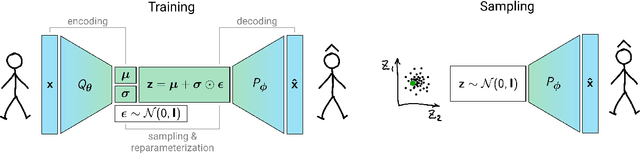
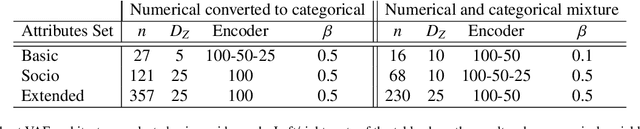
Population synthesis is concerned with the generation of synthetic yet realistic representations of populations. It is a fundamental problem in the modeling of transport where the synthetic populations of micro agents represent a key input to most agent-based models. In this paper, a new methodological framework for how to grow pools of micro agents is presented. This is accomplished by adopting a deep generative modeling approach from machine learning based on a Variational Autoencoder (VAE) framework. Compared to the previous population synthesis approaches based on Iterative Proportional Fitting (IPF), Markov Chain Monte Carlo (MCMC) sampling or traditional generative models, the proposed method allows unparalleled scalability with respect to the number and types of attributes. In contrast to the approaches that rely on approximating the joint distribution in the observed data space, VAE learns its compressed latent representation. The advantage of the compressed representation is that it avoids the problem of the generated samples being trapped in local minima when the number of attributes becomes large. The problem is illustrated using the Danish National Travel Survey data, where the Gibbs sampler fails to generate a population with 21 attributes (corresponding to the 121-dimensional joint distribution). At the same time, VAE shows acceptable performance when 47 attributes (corresponding to the 357-dimensional joint distribution) are used. Moreover, VAE allows for growing agents that are virtually different from those in the original data but have similar statistical properties and correlation structure. The presented approach will help modelers to generate better and richer populations with a high level of detail, including smaller zones, personal details and travel preferences.