 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulation synthesis for urban resident modeling using deep generative models
Nov 13, 2020

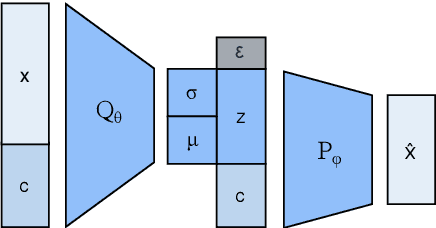

The impacts of new real estate developments are strongly associated to its population distribution (types and compositions of households, incomes, social demographics) conditioned on aspects such as dwelling typology, price, location, and floor level. This paper presents a Machine Learning based method to model the population distribution of upcoming developments of new buildings within larger neighborhood/condo settings. We use a real data set from Ecopark Township, a real estate development project in Hanoi, Vietnam, where we study two machine learning algorithms from the deep generative models literature to create a population of synthetic agents: Conditional Variational Auto-Encoder (CVAE) and Conditional Generative Adversarial Networks (CGAN). A large experimental study was performed, showing that the CVAE outperforms both the empirical distribution, a non-trivial baseline model, and the CGAN in estimating the population distribution of new real estate development projects.
Estimating Causal Effects with the Neural Autoregressive Density Estimator
Aug 17, 2020



Estimation of causal effects is fundamental in situations were the underlying system will be subject to active interventions. Part of building a causal inference engine is defining how variables relate to each other, that is, defining the functional relationship between variables given conditional dependencies. In this paper, we deviate from the common assumption of linear relationships in causal models by making use of neural autoregressive density estimators and use them to estimate causal effects within the Pearl's do-calculus framework. Using synthetic data, we show that the approach can retrieve causal effects from non-linear systems without explicitly modeling the interactions between the variables.
Prediction of rare feature combinations in population synthesis: Application of deep generative modelling
Sep 17, 2019



In population synthesis applications, when considering populations with many attributes, a fundamental problem is the estimation of rare combinations of feature attributes. Unsurprisingly, it is notably more difficult to reliably representthe sparser regions of such multivariate distributions and in particular combinations of attributes which are absent from the original sample. In the literature this is commonly known as sampling zeros for which no systematic solution has been proposed so far. In this paper, two machine learning algorithms, from the family of deep generative models,are proposed for the problem of population synthesis and with particular attention to the problem of sampling zeros. Specifically, we introduce the Wasserstein Generative Adversarial Network (WGAN) and the Variational Autoencoder(VAE), and adapt these algorithms for a large-scale population synthesis application. The models are implemented on a Danish travel survey with a feature-space of more than 60 variables. The models are validated in a cross-validation scheme and a set of new metrics for the evaluation of the sampling-zero problem is proposed. Results show how these models are able to recover sampling zeros while keeping the estimation of truly impossible combinations, the structural zeros, at a comparatively low level. Particularly, for a low dimensional experiment, the VAE, the marginal sampler and the fully random sampler generate 5%, 21% and 26%, respectively, more structural zeros per sampling zero generated by the WGAN, while for a high dimensional case, these figures escalate to 44%, 2217% and 170440%, respectively. This research directly supports the development of agent-based systems and in particular cases where detailed socio-economic or geographical representations are required.